 How many different types of Computer Assisted Review (“CAR”) software are there? How do their secret black box search engines work? What are the most effective types of search software available today? I need to shed some light on these questions as a predicate for a discussion of the next stage of the predictive coding debate. As I said in New Developments in Advanced Legal Search: the emergence of the “Multimodal Single-SME” approach, the next stage of the debate is not whether to use a CAR, or how much disclosure you should make, but which CAR, and, most important of all, how to drive the CAR.
How many different types of Computer Assisted Review (“CAR”) software are there? How do their secret black box search engines work? What are the most effective types of search software available today? I need to shed some light on these questions as a predicate for a discussion of the next stage of the predictive coding debate. As I said in New Developments in Advanced Legal Search: the emergence of the “Multimodal Single-SME” approach, the next stage of the debate is not whether to use a CAR, or how much disclosure you should make, but which CAR, and, most important of all, how to drive the CAR.
This blog will start with a list of nine popular types of advanced search algorithms that Herb Roitblat compiled recently for an article he is working on. Herb has allowed me to share that list here. The list is not exhaustive, by any means, and slightly new variants are being developed everyday.
Next I will share information given to me from one of, if not The top information scientist in the world who is working on legal search, Doug Oard. Doug is a Professor in the College of Information Studies and the Institute for Advanced Computer Studies at the University of Maryland. Dr. Oard is also an active researcher. See his list of research projects here, which includes the TREC Legal Search Track that he co-founded with Jason R. Baron and David Lewis. Jason also tells me that Doug is also an excellent pilot.
 Doug Oard generously gave of his time this weekend to help me understand that the central issue of software effectiveness cannot be solved by lists like Herb has created, unless and until you have an understanding as to how the different types of search protocols interact. To do this you have to understand the four different layers of search protocols:
Doug Oard generously gave of his time this weekend to help me understand that the central issue of software effectiveness cannot be solved by lists like Herb has created, unless and until you have an understanding as to how the different types of search protocols interact. To do this you have to understand the four different layers of search protocols:
- Feature Construction
- Feature Set Transformation
- Classifier Design
- Employment Methodology – the way the search engine is used, such as multimodal or Borg
The different search types on Herb’s list are from different levels. For that reason it is somewhat confusing to present them out of context, flattened out, so to speak, into a mere linear list, when they actually exist in a four-dimensional space with each other. Still, lists such as the one Herb Roitblat has prepared provide a very useful reference to see where vendors are placing an emphasis in the systems they design.

For an example of what I mean, the first search type on Herb’s list, Latent Semantic Analysis, is a second-layer type of system module. Second layer type modules transform feature sets that have already been constructed by first layer type decisions. Doug explained that second level types “squash a data universe into one direction” for use by a third level Classifier Design type of code. Second level type protocols do not actually make classification suggestions, such a relevant or not, they only create a space for other software programs to make that call, the classifier systems. To continue with the example, the second-level Latent Semantic Analysis could be used with a third-level classifier design module such as a Support Vector Machine or Nearest Neighbor Classifier for retrieval to happen. Latent Semantic Analysis alone can do nothing unless and until a classifier works in the space it created. For that reason it is not too helpful to say your software uses Latent Semantic Analysis unless you also specify what classifier engine you used.
Bottom line, although Herb’s list is an interesting place to start, and provides a good indicator of vendor emphasis, a full evaluation of search software requires a more complex, four-dimensional analysis of search features and their interactions.
Doug Oard allowed me to examine a manuscript he has nearly completed, Information Retrieval for E-Discovery. He is writing this information science survey with his colleague William Webber, whom I have referred to and quoted on this blog many times before. Doug and William explain in their manuscript the key search features that engineers use to improve search efficiency. I will share the highlights here, which Doug graciously examined and corrected for accuracy, although the opinions and any errors are all mine.
Laundry List of Search Engines
 First, the promised list from the generally jovial Herb Roitblat, whom I like to kid by calling the Borg King. It is a dubious accolade that he takes with a laugh. Dr. Roitblat is a research scientist with a background in psychology who, like me, loves dolphins. Before tuning his attention exclusively to legal search over ten years ago Dr. Roitblat did research in the fields of language acquisition, cognitive science, dolphin biosonar and cognition. He also served as a Professor at the University of Hawaii for seventeen years, where he got to know my brother, George Losey, a Professor of Marine Biology at the same University for over thirty years. See Eg. Losey Lab.
First, the promised list from the generally jovial Herb Roitblat, whom I like to kid by calling the Borg King. It is a dubious accolade that he takes with a laugh. Dr. Roitblat is a research scientist with a background in psychology who, like me, loves dolphins. Before tuning his attention exclusively to legal search over ten years ago Dr. Roitblat did research in the fields of language acquisition, cognitive science, dolphin biosonar and cognition. He also served as a Professor at the University of Hawaii for seventeen years, where he got to know my brother, George Losey, a Professor of Marine Biology at the same University for over thirty years. See Eg. Losey Lab.

Since leaving the University of Hawaii in 2002, Dr. Roitblat has established himself as a top legal search expert. Herb holds several patents in the area going back to the 1990s. I just love the colorful names in the titles of his patents: “quantum clustering” and “sonar system.” Herb did not include those names on his list of general types, but if you want to learn more, I suggest you click on the links to see the patents for yourself:
- 8,266,121 – Identifying related objects using quantum clustering
- 28,010,534 – Identifying related objects using quantum clustering
- 36,798,715 – Biomimetic sonar system and method
- 46,189,002 – Process and system for retrieval of documents using context-relevant semantic profiles
Herb is also the co-founder and lead scientist of OrcaTec, a legal search software company, so he has some skin in the game. He also serves as the lead scientist of the Electronic Discovery Institute and author of its important study: Roitblat, Kershaw, & Oot, Document categorization in legal electronic discovery: computer classification vs. manual review. Journal of the American Society for Information Science and Technology, 61(1):70–80, 2010. Herb Rotiblat is a frequent contributor to this blog. Also see: An Elusive Dialogue on Legal Search: Part One where the Search Quadrant is Explained, and Part Two on Hybrid Multimodal Quality Controls. We do not agree on everything, but there is no question as to my respect for the mighty Borg King. Here is his list of several of the popular types of legal search algorithms, along with the insertion that I added after the name as to which of the four layers explained by Doug Oard each type belongs to.
- Latent Semantic Analysis. Feature Set Transformation. A mathematical approach that seeks to summarize the meaning of words by looking at the documents that share those words. LSA builds up a mathematical model of how words are related to documents and lets users take advantage of these computed relations to categorize documents.
- Probabilistic Latent Semantic Analysis. Feature Set Transformation. A second mathematical approach that seeks to summarize the meaning of words by looking at the documents that share those words. PLSA builds up a mathematical model of how words are related to documents and lets users take advantage of these computed relations to categorize documents.
- Support Vector Machine. Classifier Design. A mathematical approach that seeks to find a line that separates responsive from non-responsive documents so that, ideally, all of the responsive documents are on one side of the line and all of the non-responsive ones are on the other side.
- Nearest Neighbor Classifier. Classifier Design. A classification system that categorizes documents by finding an already classified example that is very similar (near) to the document being considered. It gives the new document the same category as the most similar trained example.
- Active Learning. Methodology. An iterative process that presents for reviewer judgment those documents that are most likely to be misclassified. In conjunction with Support Vector Machines, it presents those documents that are closest to the current position of the separating line. The line is moved if any of the presented documents has been misclassified.
- Language Modeling. Classifier Design that often presents as a Feature Set Transformation. A mathematical approach that seeks to summarize the meaning of words by looking at how they are used in the set of documents. Language modeling in predictive coding builds a model for word occurrence in the responsive and in the non-responsive documents and classifies documents according to the model that best accounts for the words in a document being considered.
- Relevance Feedback. Methodology. A computational model that adjusts the criteria for implicitly identifying responsive documents following feedback by a knowledgeable user as to which documents are relevant and which are not.
- Linguistic Analysis. Methodology. Linguists examine responsive and non-responsive documents to derive classification rules that maximize the correct classification of documents.
- Naïve Bayesian Classifier. Classifier Design. A system that examines the probability that each word in a new document came from the word distribution derived from trained responsive document or from trained non-responsive documents. The system is naïve in the sense that it assumes that all words are independent of one another.
Some software already on the market use other types of search systems not included on Herb’s list. They may be too new or esoteric to have made Herb’s list, which does not mean they are any better (or worse). There are many more that are just slight variations or mere marketing puffery. My only comment on this list is that for me the most important one is Active Learning. If software does not have this feature built in as a planned method of use, then, in my opinion, it is not a bona fide predictvie coding, machine learning, type of CAR (TAR). More on that in another blog perhaps.

Search Features
All of the mentioned search types, and more, can be used in combination to create the CARs sold today by e-discovery vendors. Doug Oard says ultimately that just knowing the search types is not enough. Lawyers should focus on search features, not types, and on how the various levels of features work together. Doug says that is how search software is actually designed, by concentration on features. Here is Professor Oard’s explanation of search features from his manuscript survey for Information Retrieval (“IR”) students:
Information retrieval researchers have long experience with content-based retrieval in which the representation is built from counts of term occurrences in documents, but specialized systems also use other features (e.g., metadata found in library catalogs, the link structure of the Web, or patterns of purchase behavior). Borrowing a term from machine learning, we might call the process of crafting useful features “feature engineering” (Scott and Matwin, 1999). Four broad types of features have been found to be useful in IR generally over the years: content; context; description; and behavior. Content is what is inside the document itself; the remaining three are varieties of metadata.
Information Retrieval for E-Discovery, pg. 28.
Doug Oard then elaborates on the four different types of software search features, starting with the all important content search, where he says, there is in general little about content representation that is unique to e-discovery. The standard techniques used in information retrieval to locate target information content include:
- Common text processing techniques such as the removal of stopwords and stemming
- Term weighting calculated to give emphasis to terms frequently appearing in a particular document but rare in the collection.
In addition to content searches, the three other types of search features all pertain to types of metadata: context, description, and behavior. Effective search software will never just search content alone, it will also search metadata. This means, in my opinion, that any evaluation you make of CAR should include a careful examination of how (and if) it searches all kinds of metadata. I found the explanation given in the Oard and Webber manuscript for the three types of metadata search features to be easier to follow that the content search methods. Most e-discovery lawyers deal with these kinds of metadata everyday, even though we do not use the same terminology. Here is the Oard and Webber Information Retrieval for E-Discovery description:
Contextual Metadata. Defined succinctly, contextual metadata is any representation that serves to characterize the context within which some content was generated. … From this discussion, we can identify three broad classes of contextual metadata: time-document associations (e.g., date written), person document associations (e.g., the person who stored an email message), and content relationships (e.g., reply-to relationships).
Descriptive Metadata. A broad definition of descriptive metadata is metadata that directly describes, but is not part of (nor automatically generated from), the content of an item. Any form of content-indicative annotation or tag for a document constitutes descriptive metadata.
Behavioral Metadata. Behavioral metadata, loosely defined, is any metadata that provides information about how people have interacted with an item after its creation. Examples of behavioral metadata include the most recent time at which a file was accessed (which is maintained by many file systems); the most recent time a document was printed (which is maintained within the document by Microsoft Office products); whether the user had designated for deletion a file that was later recovered from a disk image using forensic techniques; and whether and to whom an email or attachment was forwarded (Martin et al., 2005).
Search software designers should keep all four types of search features in mind when designing first-layer type software systems: content search; context metadata search; description metadata search; and behavior metadata search. Designers should also keep all four layers in mind when designing any one layer. They all work together, and you cannot have search without all four.
- Feature Construction
- Feature Set Transformation
- Classifier Design
- Employment Methods
That includes the last layer, how search software is used. That is why vendor usage protocol development and user training is so important.
In my opinion, to properly evaluate any search software you should consider how these four features, four layers, were constructed, a process Oard and Webber call feature engineering. My non-technical understanding of their explanation of feature engineering is that, like any kind of design, it is a matter of trade-offs and expense. What are you trying to accomplish? What kind of data will you be searching? Who will be using the software? What combinations of search types do you plan to use in the four layers? What are the pros and cons of any particular combination you use? Good design necessarily requires all four layers to work well together. They are not designed from the ground up, starting with Feature Construction. Doug explained that information retrieval systems are designed by thinking about all of these layers together, a process he calls co-design.
Oard and Webber explain that useful search software:
[M]ust allow users to specify their retrieval goal in an effectively operationalizable way that ultimately can be made to conform with the representation of the ESI that is to be searched. There are two general forms this specification can take: (1) formulating queries, and (2) providing annotated examples. The two can work together: while example-based classifiers are popular, some way of choosing the initial examples is required. The discussion of specification starts, therefore, with query formulation.
Query formulation, such as lists of keywords with Boolean connectors, are well-known to e-discovery practitioners. Oard and Webber explain:
Two basic techniques are known for building good queries: “building blocks,” and “pearl growing” (Harter, 1986; Marley and Cochrane, 1981). The “building blocks” approach starts with facet analysis to identify the criteria a relevant document must satisfy. An alternative approach is known as “pearl growing,” the key idea of which is iterative query refinement through the examination of documents. Initial queries are both overly narrow (missing relevant material) and overly broad (including irrelevant material).
My preferred multimodal approach to search (a type of Active Learning, layer-four methodology) uses both the building block and pearl growing approach to level-three classifiers. I define certain criteria for a relevant document by factual and legal analysis, and I set up and run various queries, types of keyword searches of content and metadata. And I also use iterative processes, pearl growing, where I keep refining inquiries by examination of documents. The refinement may be modified keyword searches, in other words, a new and refined building block, or it may be by machine learning, which Oard and Webber call Learning from Examples:
Learning from Examples. An alternative to retrieval specification using explicit queries is to automatically learn a model from annotated examples using supervised machine learning. Typically, the user interacts with such classifiers by annotating examples of relevant and nonrelevant documents; the classifier then learns which document features (Section 3.3) are predictive of relevance. Both positive and negative examples are necessary to train a classifier. When relevant documents are a relatively small proportion of the collection, however, an insufficient number of positive examples might be obtained by a random sample (Lewis and Gale, 1994). Moreover, a fully automated classifier cannot learn the importance of a feature that it never sees in an example. The query formulation strategies described above (Section 3.4.1) can be useful in locating a sufficiently rich and diverse initial (or “seed”) set of examples. Some e-discovery practitioners, however, prefer to select the seed set by pure random sampling to avoid the (actual or perceived) potential for classifier output to be biased by the choice of query.
The last reference to some e-discovery practitioners selecting the first round of machine training, the so-called seed set, solely by random, is what I have been calling part of the Borg approach. Random is good to a point, it does help counter any potential bias, but in my opinion both random and judgmental sampling found by queries should be used. It is a mistake to rely on chance alone. It is terribly inefficient, and probably not as effective. (I know, I’ve tried it and will report on that at another time.) But most importantly, it fails to utilize the most important feature of any legal search, the human brain (what we used to call wetware), which is the foundation for the multimodal search pyramid. The supposition that lawyers are incapable of overcoming a bias to distort the truth, and so their active queries should be kept to a minimum, is a gross exaggeration at best, and a slap in the face of lawyer professionalism at worst.
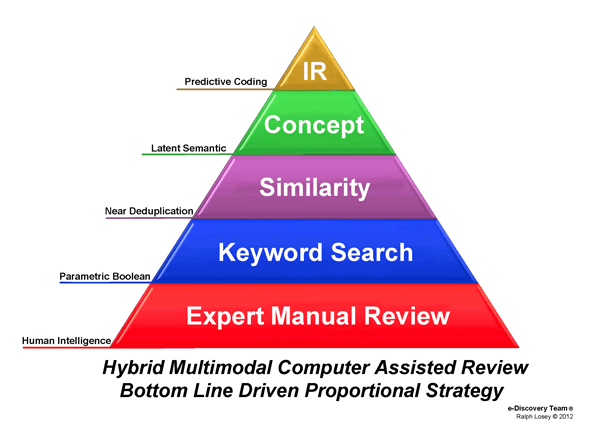
The Borg approach forgets that humans can never be taken out of the picture of legal search. For it is lawyers and judges who define the search target to begin with. We define what we are looking for and judge whether or not it has been located. Relevant or irrelevant may be a binary process, but the reasoning behind it is not. It sometime involves quite complicated legal analysis to determine whether a document is in or out, much less how much weight it should be given, i.e. – is it Hot or not.
Apparently many information scientists agree with my fourth-layer multimodal approach, where I use building block and pearl growing approaches to Active Learning. I learned from Oard and Webber of research supporting my position:
Brassil et al. (2009) claim that both facet analysis and iterative refinement are central to effective e-discovery. Pearl growing by itself is not particularly good at finding previously unknown aspects of a topic; achieving sufficient diversity therefore requires first applying something like building blocks, and then refining the initial results using something like pearl growing.
The random Borg debate goes beyond planting the initial seed for the pearl to grow. It includes what documents to show in the subsequent rounds of training. Again, I advocate a balanced approach, where random selection is used, and human judgment using other types of search, such a similarity and concept and clustering are also used in the training. Some software, including the one I normally use, includes a third component, the documents where the computer is uncertain about its ranking. Oard and Webber explain such an active learning process as follows:
Classifiers are frequently trained iteratively, by adding more annotated examples until some level of measured reliability is achieved. Examples additional to the initial seed set can be selected by simple random sampling, or else the classifier itself can determine which documents to annotate next, in a process known as active learning. In active learning, it is typically the documents that the classifier is most unsure about classifying that are selected for assessment. Active learning generally requires fewer training examples than random or passive learning (Lewis and Gale, 1994). Iterative training workflows may also include a step where the user is asked to review inconsistent or outlier assessments (O’Neill et al., 2009).
The exam of inconsistent categorizations between actual coding and predicted rank is an important quality control that you should also look for in good search software.
The Oard and Webber manuscript also elaborates on deduplication, near deduplication (similarities), email thread reconstruction, and clustering as important search features. Their explanation on clustering is helpful to see:
Clustering: Clustering helps to address cases in which decisions can and should be made on an entire set of documents at once. These may be final decisions (e.g., to mark each document family in a set of exact duplicates as responsive or as not responsive) or they may be intermediate decisions in some staged decision process (e.g., to include all documents held by some custodian).
Oard and Webber also provide useful information on machine learning content classifier types of design – level three. It brings in the aspect of knowing, and not-knowing, how the software is reacting to the document examples you train it with. In the software I typically use, the response to new classifier examples is usually not readily apparent or easily interpretable, but after some experience with the software and the data under review, you can get a feel for how the software is responding. It becomes a kind of intuitive, hybrid man-machine interchange. This allows a searcher to tune the classifications and know when to stop the iterations. Apparently this kind of phenomenon is not unknown, and is even a software evaluation factor, involving the kind of tradeoffs inherent in any design. As Oard and Webber observe:
Many classifier designs learn statistical models that are not easily interpreted or directly tunable by people. For instance, a support vector machine learns a separating hyperplane in a transformed multidimensional feature space (Joachims, 1998), while (supervised) probabilistic latent semantic analysis infers a generative model of words and documents from topical classes (Barnett et al., 2009). There are, however, classifier designs that yield decision rules that are at least somewhat interpretable. Examples include rule induction (Stevens, 1993), association rule learning (Agrawal et al., 1996) and decision trees (Quinlan, 1998). Unfortunately, the less explainable statistical text classifiers also tend to be the most effective (Dumais et al., 1998).
When the model built by an automated classifier is not easily interpretable, the use of example-based statistical classifiers places a heavy emphasis upon evaluation to guide classifier training and to assure classifier effectiveness.
This is an important consideration for me in evaluating a new CAR, have software designers reached a good balance between deep analysis and obvious results in the level three classifiers? I do not want it to be so obscure as to be impossible for an experienced searcher to tune, and know when to stop, yet at the same time I want classifier effectiveness. I want the computer to be able to find types of responsive documents beyond my expectations.
Conclusion
Search software design requires the careful and balanced implementation of the search features mentioned by Doug Oard and William Webber. All of the feature layers discussed should be considered. In my opinion, you should evaluate the strength of the software in the following areas, as they all impact the overall quality, effectiveness, and efficiency of the programs:
- Search of content
- Search of contextual metadata
- Search of descriptive metadata
- Search of behavioral metadata
- Classifier design
- Active query formulation features (building blocks)
- Annotated example training features (pearl growing)
- Random training abilities
- Human judgment training features
- Software uncertainty selected training
- Balance in your classifier system between complexity and intuitiveness
- Deduplication, near deduplication, and similarity searches
- Concept searches, what exactly are they doing and how
- Clustering features
- Email thread and families
- Quality Control features
- Quality Assurance features
- Confidentiality Protection features, including privilege logging and redacting
- Recommended method(s) of use (level four)
- Ease of operation
- Clarity and efficiency of user interface
- Customizability for particular licensees, projects, users
- Response time (each entry and length of search processing)
- Reporting capacities and usefulness
- Expense
There are many other criteria, I know, such as information security, more specific user interface issues, reviewer and production issues, reviewer monitoring and interface, online access, etc. Software selection should also carefully consider the software support and training issues. Project management support is also critical, some say just as important as the software itself, especially for novice users of the search software.
Coming up with the right mix is not an easy design process. It takes time and great expense to develop sophisticated legal search algorithms. Although the basic technologies have been known for years, the application to legal search is fairly new. Some companies have understood the importance of investing in these new advanced search methods and features. They have been doing it for years. Other are just now playing catch up and pasting together something, just so they can say they have a CAR with machine training capacities.
A few good questions to ask software vendors when you are trying to make a decision on which one to use include:
- Which of Herb Rotiblat’s list of nine are in your black box? Any others?
- How do they fit into Doug Oard’s and William Webber’s four layers?
- Please try to explain in layman’s language how it operates? If a judge ever insists on hearing about this in a Daubert or less formal type of hearing, who are your designated spokespersons. Can I see their resumes?
- When did you start working on incorporating predictive coding into your software? When was your product with these features first released? (You can check this representation by looking for their old ads still on the Internet.)
- What kind of investment in this technology have you made, approximate dollar amount?
- Are you using your own code, or are you licensing someone else’s? If partially outsourced, which parts and why?
- If outsourced, do other software vendors use the same code? If so, why should I use yours instead of theirs?
- If you did create your own software, what is your development cycle? What version are you on now?
- What improvements are you working on now, short-term and long? Can I see the last release notes?
- What resources do you now have committed to the software enhancement process? How many people and what are their qualifications?
- What scientific experts, researchers, or engineers have contributed to your software?
- Do you have any objective or third-party test results and testimonials? References?
- Can I see all of your White Papers on CAR?
- Who would you assign to assist me on predictive coding issues? Who would be my project manager(s)?
- Length of commitment? Transferability? Refunds if we don’t like it?
- And most importantly, can I take a test drive of your CAR, one where I do the driving, without vendor passengers (unless I have questions) and have time to see how it works?
Do not just pick your CAR on the basis of price alone, or type of algorithms as per Herb’s list, and never select search and review software on the basis of vendor advertising alone. If you do, you may end up with the famous Griswold clunker!

[…] Many Types of Legal Search Software in the CAR Market Today – http://bit.ly/Xk8mCA (Ralph […]
[…] The Many Types of Legal Search Software in the CAR Market Today (Ralph Losey, E-Discovery Team) […]
[…] Many Types of Legal Search Software in the CAR Market Today – http://bit.ly/Xk8mCA (Ralph […]
[…] retrieval experts Doug Oard and William Webber call this iterative process learning by example. The Many Types of Legal Search Software in the CAR Market Today, quoting Oard and Webber’s manuscript Information Retrieval for […]
[…] The Many Types of Legal Search Software in the CAR Market Today. […]
[…] Many Types of Legal Search Software in the CAR Market Today – http://bit.ly/Xk8mCA (Ralph […]
You actually make it seem so easy with your presentation but I find this
topic to be actually something that I think I would never understand.
It seems too complex and extremely broad for me.
I am looking forward for your next post, I will try to get
the hang of it!
I think everything posted made a lot of sense. However, what about
this? suppose you wrote a catchier post title?
I ain’t suggesting your information is not solid., but what if you added something that makes people desire more? I mean The Many Types of Legal Search Software in the CAR Market Today | e-Discovery Team ® is kinda plain. You might glance at Yahoo’s
front page and note how they write news headlines to grab viewers interested.
You might add a related video or a picture or two to grab readers excited about everything’ve written. In my opinion, it would make your posts a little livelier.
Many businesses only have occasional need of a van,
or need one only for a short period of time. Also, target household
expenditures on electricity and water. Issues may come up unexpectedly’new insurance and medical costs, or you may be paying rent or mortgage for the first time.
Hello! Do you use Twitter? I’d like to follow you if that would be ok. I’m definitely
enjoying your blog and look forward to new updates.
[…] The Many Types of Legal Search Software in the CAR Market Today; […]
[…] The Many Types of Legal Search Software in the CAR Market Today. […]
[…] The Many Types of Legal Search Software in the CAR Market Today. […]
[…] articles on this subject to try to debunk this method, and yet this method lives on. See eg The Many Types of Legal Search Software in the CAR Market Today; Three-Cylinder Multimodal Approach To Predictive […]