 This is the second in a series of reports on a fifty-hour predictive coding experiment using a modified Borg approach to predictive coding. I say a modified Borg approach because I refused to eliminate human judgment entirely. That would be too hideously boring for me to devote over fifty hours of my time. Some of the modifications I made to slightly humanize the Borg approach are explained in the first video below.
This is the second in a series of reports on a fifty-hour predictive coding experiment using a modified Borg approach to predictive coding. I say a modified Borg approach because I refused to eliminate human judgment entirely. That would be too hideously boring for me to devote over fifty hours of my time. Some of the modifications I made to slightly humanize the Borg approach are explained in the first video below.
In this segment I begin the search project with a random sample. Then I began the first two rounds of machine training with the usual auto coding runs and prediction error corrections (steps four and five in the below diagram). The second video below describes the first two iterative rounds. For these videos to make sense you first need to read and watch Borg Challenge: Part One of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodology.
Creating a random sample at the beginning of a review is not necessarily part of a Borg review, and may not be included in most Borg-like software, but it easily could be. It is a best practice that I always include in large scale reviews. When I explain hybrid multimodal machine training using an eight-step model, the first random sample is the third-step, which I call Random Baseline in this diagram.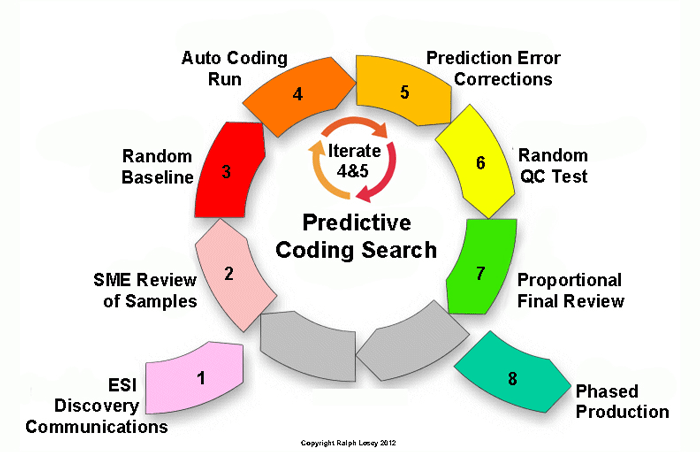
I use the first random sample as part of my quality control program. With the sample I calculate prevalence, the percent of relevant documents in the total collection. This information gives you a good idea of how many of the relevant documents you have located during the course of the project. Of course, what information scientists call concept drift, and we lawyers call improved understanding of relevance, can impact this calculation and should be taken into account. In this search concept drift was not really a factor because I had already done this same search before. Since this was a repeat search, albeit using a different method, the Borg did have an advantage in this comparative test.
I included a random sample at the beginning of the Borg experiment to give the monomodal method every possible benefit and make the comparison as fair as possible. During the experiment I used several other quality control methods that Borg-like software may not have for the same reasons.
Watch the video and learn more about how I used a random sample of 1,183 documents to begin the Borg Challenge. The next video will describe the first two rounds of training after the baseline sample. These videos will provide many details on the methods used and progress made.
Technical Notes
Although in the video I refer to the first two rounds of training, to be technically correct, they are actually the second and third rounds. Since I found some relevant documents in the random sample, I trained on them. The computer used at least some of them as part of its training set to calculate the first 200 documents for my review. Each round of review trained on at least 200 documents. I selected this 200 documents number (it could be configured to be any size), because in my experience with Inview software, this has been a good minimum number of training documents to use.
To get even more technical, some of the documents I identified as relevant in the first random sample were not used in the first training, instead they were held in reserve, also known as held-out data, in what Kroll Ontrack and others call the testing set. Manning, et al, Introduction to Information Retrieval, (Cambridge, 2008) at pg. 262. This testing set derivation from an initial random sample is part of the internal quality control and metrics evaluation built into the Kroll Ontrack’s Inview and other good predictive coding enabled software. It allows the software itself to monitor and validate the progress of the review, but as you will see, in my modified hybrid approach, I primarily rely upon my own techniques to monitor progress. See Human–computer information retrieval (HCIR).
The first round of training came after coding the random sample. In the random review some documents were marked as relevant and provided for training. So what I call the first round of 200 documents in the video was selected both by random and internal evaluation, which I have previously labeled the Enlightened Borg approach. Three-Cylinder Multimodal Approach To Predictive Coding. This means that, to be entirely accurate, when my training sets are concluded (and I am not yet going to reveal how many rounds I went before it concluded (care to place bets?)), you should add one to the total count.
You should also know that the very first round of training, here described as the random sample, was what I call a Luck Borg round based on chance selection. Id. All of the ensuing rounds of training used an Enlightened Borg approach, enhanced with limited HCIR, but excluding any kind of search other than predictive coding based search. I will explain these subtle distinctions further as this Borg Challenge narrative continues.
___________
______________
Stay tuned for Borg Challenge: Part Three where I continue my search through round sixteen of machine training.
[…] of the training. For these videos to make sense you first need to read and watch Part One and Part Two of the Borg Challenge. If this still makes no sense, you could try reading a science fiction […]
[…] in a Kafka novel. For these videos to make sense you first need to read and watch Part One, Part Two, and Part Three of the Borg Challenge. Even then, who knows? Kafkaesque videos providing […]
[…] in every respect, except for methodology. The experiment itself is described in Part One, Part Two, Part Three and Part Four of the Borg Challenge. The results reported in my videos below may […]
[…] narrative of the Borg Challenge that was previously reported in five installments: Part One, Two, Three, Four and […]