For ease of future reference this blog contains the entire narrative of the Borg Challenge that was previously reported in five installments: Part One, Two, Three, Four and Five
Borg Challenge: Part One of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodology
 This is the first in a series of reports on a fifty-hour predictive coding experiment using a semi-automated, single-search-method. I usually refer to this method as the Borg approach, after the infamous Star Trek villains. See: Never Heard of Star Trek’s Borg? This method is used by many predictive coding software systems. It contrasts with the hybrid multimodal search method that I use, along with many others.
This is the first in a series of reports on a fifty-hour predictive coding experiment using a semi-automated, single-search-method. I usually refer to this method as the Borg approach, after the infamous Star Trek villains. See: Never Heard of Star Trek’s Borg? This method is used by many predictive coding software systems. It contrasts with the hybrid multimodal search method that I use, along with many others.
Multimodal in the context of predictive coding means the use of all types of searches to find machine training documents, not just one. I call it a hybrid approach because the human search expert remains in control of the machine learning. I recently discovered this follows a well-established practice in information retrieval science called Human–computer information retrieval (HCIR). The multimodal hybrid approach is contra to a monomodal approach where predictive coding only is used, and where the interaction of humans in the process is minimized, or reduced entirely to yes-no decisions.
I think the hybrid multimodal method is superior to the popular alternative Borg methods, but I have no real factual basis for this supposition. To my knowledge no comparisons or other tests have ever been made between the two methodologies. My opinion was based on logic alone, that if one search method was good, many would be better. But as I have previously stated here, my opinion could be wrong. After a lifetime in the law I know that for judgments to be valid they must be based on evidence, not just reason. See eg. There Can Be No Justice Without Truth, And No Truth Without Search. That is also a basic tenet of our scientific age. For these reasons I decided to perform an experiment to test the Borg approach against my own preferred methods. Thus the Borg Challenge experiment was born.
 I had already performed a fifty-hour search project using my methods, which I reported here. Predictive Coding Narrative: Searching for Relevance in the Ashes of Enron. That set a benchmark for me to test the Borg approach against. My experiment would be to repeat the same search I did before, but using the competing method. I would once again search an Enron dataset of 699,082 emails and attachments for evidence of involuntary employment terminations. I would also use the same software, Kroll Ontrack’s Inview, but this time I would configure and use it according to the Borg method. (One of the strengths of Inview is the flexibility of its features, which allowed for easy adaptation to this alternative method.)
I had already performed a fifty-hour search project using my methods, which I reported here. Predictive Coding Narrative: Searching for Relevance in the Ashes of Enron. That set a benchmark for me to test the Borg approach against. My experiment would be to repeat the same search I did before, but using the competing method. I would once again search an Enron dataset of 699,082 emails and attachments for evidence of involuntary employment terminations. I would also use the same software, Kroll Ontrack’s Inview, but this time I would configure and use it according to the Borg method. (One of the strengths of Inview is the flexibility of its features, which allowed for easy adaptation to this alternative method.)
As far as I know, this kind of test comparison of the same large search project, by the same person, searching the same data, but with different methods, has never been done before. I began my project in 2012 during Christmas vacation. I did not finish my final notes and analysis until March 2013. The results of my experiment may surprise you. That is the beauty of the scientific method. But you will have to hang in there with me for the full experiment to see how it turned out. I learned many things in the course of this experiment, including my endurance level at reading Enron chatter.
As in the first review I spent fifty hours to make it a fair comparison. But the whole project took quite a bit longer than that as there is more to this work that just reading Enron emails. I had to keep records of what I did and create a report to share my journey. In my original hybrid multimodal review I wrote a 72-page Narrative describing the search. Predictive Coding Narrative: Searching for Relevance in the Ashes of Enron. I know this is a difficult read for all but the most ardent searchers, and so too was the write-up. For these reasons I looked for a way to spice up my reporting of this second effort. I wanted to try to entice my fellow e-discovery professionals into following my little experiment. My solution was to use video reports, instead of a long written narrative. Then I added some twists to the video, twists that you will see for yourself as the Challenge of the Borg experiment unfolds.
Here is the opening act. It begins in my backyard in Florida in late December 2012.
___________
Borg Challenge: Part Two where I begin the search with a random sample.
 This is the second in a series of reports on a fifty-hour predictive coding experiment using a modified Borg approach to predictive coding. I say a modified Borg approach because I refused to eliminate human judgment entirely. That would be too hideously boring for me to devote over fifty hours of my time. Some of the modifications I made to slightly humanize the Borg approach are explained in the first video below.
This is the second in a series of reports on a fifty-hour predictive coding experiment using a modified Borg approach to predictive coding. I say a modified Borg approach because I refused to eliminate human judgment entirely. That would be too hideously boring for me to devote over fifty hours of my time. Some of the modifications I made to slightly humanize the Borg approach are explained in the first video below.
In this segment I begin the search project with a random sample. Then I began the first two rounds of machine training with the usual auto coding runs and prediction error corrections (steps four and five in the below diagram). The second video below describes the first two iterative rounds. For these videos to make sense you first need to read and watch Borg Challenge: Part One of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodology.
Creating a random sample at the beginning of a review is not necessarily part of a Borg review, and may not be included in most Borg-like software, but it easily could be. It is a best practice that I always include in large scale reviews. When I explain hybrid multimodal machine training using an eight-step model, the first random sample is the third-step, which I call Random Baseline in this diagram.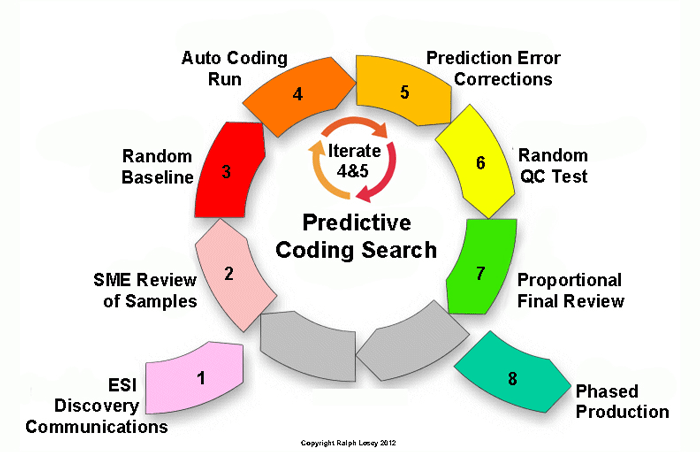
I use the first random sample as part of my quality control program. With the sample I calculate prevalence, the percent of relevant documents in the total collection. This information gives you a good idea of how many of the relevant documents you have located during the course of the project. Of course, what information scientists call concept drift, and we lawyers call improved understanding of relevance, can impact this calculation and should be taken into account. In this search concept drift was not really a factor because I had already done this same search before. Since this was a repeat search, albeit using a different method, the Borg did have an advantage in this comparative test.
I included a random sample at the beginning of the Borg experiment to give the monomodal method every possible benefit and make the comparison as fair as possible. During the experiment I used several other quality control methods that Borg-like software may not have for the same reasons.
Watch the video and learn more about how I used a random sample of 1,183 documents to begin the Borg Challenge. The next video will describe the first two rounds of training after the baseline sample. These videos will provide many details on the methods used and progress made.
Technical Notes
Although in the video I refer to the first two rounds of training, to be technically correct, they are actually the second and third rounds. Since I found some relevant documents in the random sample, I trained on them. The computer used at least some of them as part of its training set to calculate the first 200 documents for my review. Each round of review trained on at least 200 documents. I selected this 200 documents number (it could be configured to be any size), because in my experience with Inview software, this has been a good minimum number of training documents to use.
To get even more technical, some of the documents I identified as relevant in the first random sample were not used in the first training, instead they were held in reserve, also known as held-out data, in what Kroll Ontrack and others call the testing set. Manning, et al, Introduction to Information Retrieval, (Cambridge, 2008) at pg. 262. This testing set derivation from an initial random sample is part of the internal quality control and metrics evaluation built into the Kroll Ontrack’s Inview and other good predictive coding enabled software. It allows the software itself to monitor and validate the progress of the review, but as you will see, in my modified hybrid approach, I primarily rely upon my own techniques to monitor progress. See Human–computer information retrieval (HCIR).
The first round of training came after coding the random sample. In the random review some documents were marked as relevant and provided for training. So what I call the first round of 200 documents in the video was selected both by random and internal evaluation, which I have previously labeled the Enlightened Borg approach. Three-Cylinder Multimodal Approach To Predictive Coding. This means that, to be entirely accurate, when my training sets are concluded (and I am not yet going to reveal how many rounds I went before it concluded (care to place bets?)), you should add one to the total count.
You should also know that the very first round of training, here described as the random sample, was what I call a Luck Borg round based on chance selection. Id. All of the ensuing rounds of training used an Enlightened Borg approach, enhanced with limited HCIR, but excluding any kind of search other than predictive coding based search. I will explain these subtle distinctions further as this Borg Challenge narrative continues.
___________
______________
__________
Borg Challenge: Part Three where I continue my search through round 16 of machine training
 This is the third in a series of reports on a fifty-hour predictive coding experiment using the Borg approach to predictive coding. In this segment my video describes rounds three through sixteen of the training. For these videos to make sense you first need to read and watch Part One and Part Two of the Borg Challenge. If this still makes no sense, you could try reading a science fiction version of the battle between these two competing types of predictive coding review methods, Journey into the Borg Hive. And you thought all predictive coding software and review methods were the same? No, it is a little more complicated than that. For more help and information on Computer Assisted Review, see my CAR page on this blog.
This is the third in a series of reports on a fifty-hour predictive coding experiment using the Borg approach to predictive coding. In this segment my video describes rounds three through sixteen of the training. For these videos to make sense you first need to read and watch Part One and Part Two of the Borg Challenge. If this still makes no sense, you could try reading a science fiction version of the battle between these two competing types of predictive coding review methods, Journey into the Borg Hive. And you thought all predictive coding software and review methods were the same? No, it is a little more complicated than that. For more help and information on Computer Assisted Review, see my CAR page on this blog.
The kind of repetitive review task method I am testing here, where you let the computer do most of the thinking and merely make yes-no decisions, can be tedious and difficult. As the project progressed I began to suspect that it was not only taking a toll on my mind and concentration, but also having physical effects. Some might say the changes are an improvement over my normal appearance, but my wife did not think so. Note the Borg appear to be somewhat like vampires and prefer the dark. Click on these two short video reports and see for yourself.
_____________
_________
Borg Challenge: Part Four where I complete the experiment
This is the fourth in a series of reports on a fifty-hour predictive coding experiment using the Borg approach to predictive coding. In this segment my video describes rounds seventeen forward of the machine training. The experiment comes to an end, and none too soon, as I was beginning to feel like a character in a Kafka novel. For these videos to make sense you first need to read and watch Part One, Part Two, and Part Three of the Borg Challenge. Even then, who knows? Kafkaesque videos providing predictive coding narratives based on Star Trek villans are not for everyone.
___________
_______
Borg Challenge: Part Five where I summarize my findings
This is the fifth installment in a series of reports on a fifty-hour predictive coding experiment using Borg-like monomodal methods. In this last segment I summarize my findings and compare the results with my earlier search using multimodal methods. The two searches of 699,082 documents were identical in every respect, except for methodology. The experiment itself is described in Part One, Part Two, Part Three and Part Four of the Borg Challenge. The results reported in my videos below may surprise you.
___________
_______
Now that you have heard the full story of the Borg Challenge, you may want to see the contemporaneous notes that I made during the experiment. I also reproduce them below.
_______
Notes of Borg Challenge Review of 699,082 ENRON Documents
Ralph C. Losey
Initial Random Sample to begin project with review of a random sample of 1,183 documents.
• 4 relevant were found.
• Prevalence = 0.25359% (3/1183)
• Spot Projection = 1,773 documents (699,082* 0.25359%)
• Using Binomial = 0.25 +/- 0.05% to 0.74%
• From 350 documents to 5,173 documents
• Took 130 minutes to review (2.16 hrs)
Total Relevant Found by Borg After 50 Rounds = 579
Total Relevant Found by Multimodal = 661.
That’s 81 more documents by Multimodal, which is a 14% improvement.
Put the other way, the Borg method found just under 88% of the Multimodal total.
Final Quality Assurance Random Sample to end project with random sample of 1,183
• 1 relevant was found in the 1,183. Borderline. News article about Enron firing two employees – 5403549. It had not been reviewed.
• Of the 1,183 sample, 26 had been previously reviewed and all had been categorized irrelevant. I agreed with all prior coding.
• Prevalence = 0.0845% (1/1183)
• Spot Projection = 591 documents (699,082* 0.0845%)
• Using Binomial = 0.08 +/- 0.0% to 0.47%
• From 0 documents to 3,286 documents
• Took 150 minutes to review (2.5 hrs)
Elusion = 0.0845% and none were Hot. Shows inadequacies of the Elusion Test in low prevalence.
Combine two Borg random samples taken: 2,366 with 5 found. (95% +/- 1.57%)
Multimodal random sample of 1,507 with 2 found = 0.13%
All Three: 3,873 samples with 7 found = 0.18% = 1,264 spot projection
Binomial = 0.07% – 0.37% = 489 to 2,587
Using most accurate spot projection of 1,264.
Borg retrieval of 578 = Recall 46% (worst case scenario = 578/2,587 = 22% recall)
Multimodal retrieval 659 = Recall 52% (that’s 13% improvement) (worst case = 659/2587 =
25%) (13.6% improvement)
Best Case scenario = 691 relevant. Borg 578 = 83.6%. Multimodal 659 = 95.4%
TOTAL HOT FOUND IN MULTIMODAL = 18.
TOTAL HOT FOUND IN BORG = 13 (only 72% of total found by multimodal)
____________
ROUNDS
Each round consists of a review of 200 documents selected by Inview for training. Inview selected 80% of the 200 on the basis of its uncertain (160 documents) and 20% by random sample (40 documents)
1. 3 relevant found.
• control # 470687; marginally relevant email
• 12005752; barely relevant email
• 12004180 – marginal
• 6 seconds per file: 9.1 files per minute 546 miles per hour
2. -0- relevant found.
• over 80% were foreign language
• took 30 mins – 6.7 files per min., 9 second per file
3. -0- relevant found.
• 155 of them were empty PST files, 3 mins; 12 minutes for the rest
4. 3 relevant found.
• mix of file types; 54 obvious irrelevant; took 5 mins; 146 took 25 mins
• 12007083 – good email re severance payments
• 12009832 – severance plan related email
• 12006688 – waiver and release form
5. 1 relevant found.
• ZERO Relevant files found in the 200 served
• At this point I also ran a special search to see if any 50%+ probable to rank relevant; one new doc predicted relevant 75.7%, control 12006689 – waiver agreement (similar to one already marked)
6. -0- relevant found.
• 50% + search found no new
7. 1 relevant found.
• one relevant release form 12006941;
• all else were not even close except for a contract termination email
• no new ranked relevant docs
8. 1 relevant found.
• 1 relevant employment handbook with term provisions – 12010249
• The rest of the documents were junk, meaning not even close
9. 3 relevant found.
• one relevant email; a general notice to all employees on bankruptcy that mentions employment termination. Control 11236804
• relevant general release (as before) 12000320
• relevant separation agreement 12000546
10. 38 relevant found.
• 34 relevant found in 200 + 4 known by rank outside of the 200 = 38 total
• multiple copies (28) re Reporting to Work Next Week (multiple copies); this email was sent to all employees just before bankruptcy
• 2 more of same found that were on claims
• 4 relevant employee agreement form
• total 34 relevant out of this 200
• ran relevancy marking search – 4 new ones seen ranked
11. 6 relevant found.
• three of the six found in the 200 were of a new type; the other three were more of the same
• relevancy search rank; none new
12. 12 relevant found.
• 2 relevant severance contracts
• 1 relevant employment manual
• 9 relevant FAQ scripts
• 40 minutes for review here (agreements – require more reading to see if there are previous related to termination of employment)
13. 15 relevant found.
• 3 relevant found out of 200, plus 12 from ranked search; total 15 new relevant
• two relevant from the 200 re notice to all employees
• one Canadian release was relevant in the 200
• search of 50%+ probability showed 202 new files predicted relevant, 182 of which were spreadsheets. That was a big jump. But only12 of the predictions were correct (all the Word docs)
• 190 of the 202 50%+ predicted relevant were not in fact relevant
• all of the 12 Word docs were correct predictions
• 6 pdf files – all were irrelevant.
• took another hour for the probability search of 202 documents
14. -0- relevant found.
• included many (150) agreements having nothing to do with employment. All irrelevant
• Predictions were usually about 33% likely relevant and 33% likely irrelevant
15. 19 relevant found.
• 14 were found from the 200:
• 1 relevant spreadsheet calculating termination severance amount
• 1 script to use to talk to terminated employee 12007598
• 4 benefit severance case scenarios
• 1 form termination letter 12006691
• 1 legal advice letter re severance plan 12114935
• 3 actual employment termination letters 12010037
• 1 policy plan change notice
• 1 restated severance plan 12007612
• 2 copies 1 advice from Littler re severance 12009928
• Ran a 50%+ relevancy probability search and 1,487 new predicted relevant documents were shown. A partial review of the 212 I thought most likely to be relevant showed that five (5) were in fact relevant.
• 106 of these were spreadsheets; all reviewed and irrelevant
• 1,331 of the 1,487 were document files; I coded 58 of them. All
irrelevant.
• 31 emails (approx); reviewed all 31, 3 were relevant
• 1 of these 31, found relevant 12007475 was a close question
• Other two ere relevant, eg. 4500240
• I also reviewed 17 odd type file extensions and all were irrelevant
16. 8 relevant found.
• one of the relevant was a close ques. where an offer of employment was rescinded. I considered it relevant – 12010086
17. 12 relevant found.
• 6 found in the 200
• Another 6 in 50%+ probability search
• These 6 were found in the 200:
• relevant emp. contract provisions discussion re termination 12001241
• severance questions – 12006474
• ques re termination for cause – 12006554
• severance plan revisions email – 12011276
• letter rescinding emp. offer – 12007269
• email re severance meeting – 10715815
• search of 50% + probable relevant; 9 not previously reviewed; 6 were relevant; 3 were not
18. 6 relevant found.
• 2 – interrogatory in an employment case 12006517
• 2- Littler re emp. contract – 8400148 – 2 copies
• employment offer rescission
• Oregon statute re: employee requests after termination – 12002602
• many irrelevant contracts were in the review
• 50% + probability search showed no new
19. 28 relevant found.
• email re severance plan revision 12006469
• note – 2 already marked relevant docs were in this set, they were 99% probable
• email re termination of one employee, 12006943
• email re emp. termination – 15508142
• email with ques. re severance – 12005851
• close ques – ERISA plan question email – 12006777
• employee (Ming) dispute re her terminate documentation – 12010029
• employee (Kim) ques. re his severance and email internal re: giving Kim severance – 12005206
• employee complaint of discriminatory termination – 15514893
• 5 email re script for employee terminations – 12007133
• email ques. re severance – 12005421
• email ques. re: severance – 12005422
• another email reply re severance
• another email reply
• another email reply
• another email reply 12010778
• employee incorrectly sent termination
• 2 notices due to computer error 4109833
• voluntary and involuntary termination discussed
• 4 emails re severance plan
• email re severance legal issue (WARN)
• email re termination law suit – 8003332
• this round had many relevant documents and complicated ones; round took 50-60 minutes
• search of 50%+ shows no uncategorized docs
20. -0- relevant found.
• search of 50% + shows no new documents
21. 12 relevant found.
• did 50% + – nothing new
• minutes re emp. contract of Fastow discussing termination – 8003490
• 2 emails re: severance contract – 12007223
• 2 emails re severance contract
• 2 email from individual employee re unfair termination 15511658
• email re severance plan
• 2 complaints by employee, Lion, re discriminatory termination – 8004527
• Oregon statute re: termination
• waiver interpretation email
• email re severance plan
• note irrelevant email that is close – 17312114
22. 5 relevant found.
• 3 relevant found in 200, plus 2 more in 50% + – total 5 relevant
• email re severance plan
• email re severance plan
• email re severance plan
• 50% + probable search: 8 not previously categorize; 2 were relevant
23. 8 relevant found.
• Relevant – severance calculation spreadsheet
• email re emp. term. and immigration
• email re: severance plan communication to all employees
• email that mentions contract termination of employee for cause
• email re: revised severance plan
• follow-up email re: immigration issue above
• email re severance plan
• email re severance plan
• 50% + probability search – 185 found – all previously categorized
24. 10 relevant found.
• 9 from the 200, and 1 from probability – total 10
• 50%+ probability search – one new prediction 62.6% which was correct – total 179
• Relevant found from the 200
• email re termination date and vesting
• email re tax on severance and agreement
• email re severance and part-time employees
• irrelevant, but close call – 15508438
• relevant email re severance and merge
• email re UK employee that mentions severance if terminated
• email re let the severance plan speak for itself
• severance question
• Ms. Bates employment termination
• EEOC case – strong relevant 12005636; only predicted 19.5%
• Severance pay plan assessment – close – 12011364
• total number of relevant so far = 273
25. 3 relevant found in 200, and 1 from probability – total 4.
• relevant email re termination
• reinstatement remedy in EEOC case for wrongful termination – 12007303
• email re: voluntary and involuntary question
• search 50% + probability – 184 – 2 not categorized, 1 relevant (57.3%) and 1 not relevant (58%)
26. 1 relevant found in 200.
• email re: severance plan
27. 8 relevant found in 200
• 3 emails with emp. complaint re severance and vacation
• severance email
• mass email re mistaken notice of termination 12305510
• part-time employee and severance issue
• retention of outside counsel re termination without legal permission. Close question. 12005884
• severance and UK and US employees
28. 5 relevant found in 200, and 7 from probability – total 12
• email re hiring outside counsel
• Fairness in severance based on tenure 12512159
• 3 emails re emp. contract terms, specific as to termination
• run 50% + probability search – 185 total. Review all. Notes below.
• one doc was 70.4% predicted relevant. I had previously marked it as irrelevant and of course trained on it. I now read the agreement more carefully and found termination provisions I had missed before. I agreed it was relevant! 12003549
• another email found like above where termination is found in end of email and so I changed my mind and mark relevant 1200928
• another, this time in a form letter where I now see it has termination language in it 12001275
• another, a WARN notice discussion 12005220
• another, a non-disclosure form with termination discussion that I had marked irrelevant before; 58.3% probable relevant 14632937
• one where I stuck with my guns and still disagreed 12011390. Computer predicted 90.5% relevant and only 1% irrelevant even though I had categorized it as irrelevant.
• another one where computer is right and I changed my mind 12005421. It was ranked 88.8% likely relevant even though I had previously coded as irrelevant.
• another one re termination of employee named Ming where I changed my mind and agree – 67.7% likely relevant. 12010029
29. 50 relevant found in 200 and 3 from probability – total 53.
• 3 emails re severance and tenure
• termination complaint email re India
• email re: severance benefits
• 40 copies of same email re mistaken notice of termination and savings plan
• email re employee relocation or termination
• severance and part-timers
• 3 severance re total costs and Dynergy
• 50% search – 3 previously marked by me as irrelevant now show as likely relevant. Looking again I now see computer is right and they should be marked relevant:
– one concerns a foreign employment contract with 70.1% relevant ranking and I change my mind and agree – 13725405. It only ranked the agreement as 7.3% likely irrelevant, even though I had coded as irrelevant.
– I agreed with a release email, but it was close call. Computer said 90.5% relevant 12011390
– I agreed with the third one too re co scripts and a question on severance 12007134
30. 8 relevant found from 200. Note: corrections made to errors by a Quality Control check of marked relevant documents. The corrected total relevant is now 292.
• email re severance payments
• email re severance calculations
• email re employment contracts and severance
• email re waivers and release
• email re a suit on wrongful termination; very obvious relevant email 12006801
• 2 emails re amended severance to extend employment a month
• email re bankruptcy and severance payments
• ran 50% + not categorized – zero
• First Quality Control Check: I ran a total relevancy search and found 363 total, and double checked all of the, Then I found 71 errors, all errors, which I corrected. They were labeled relevant and were not – all obvious. Pretty sure this was caused by checking the wrong box when doing rapid coding of obvious irrelevant. Made adjustment to coding input layout to make this more unlikely to happen. Good lesson learned here.
• I reran all of the training to be safe the bad input was corrected
31. 3 relevant found from 200. Note: additional QC efforts found 5 more mistakes in prior manual coding. All errors were documents incorrectly marked relevant.
• Email re complaint about termination
• email re revisions and terminations
• Q&A related questions re severance
• Quality Control Check: Probability search of 25%+ predicted relevant but not coded relevant – 12 found. 5 of them were mistakes where I changed my mind and now coded them as relevant. The details of this QC process are as follows:
– Employment contract 13737371 with termination provisions. I mistakenly marked this as irrelevant before because I saw the employer was UBS Warburg. I looked even more carefully now and saw they were acting as a successor in interest to Enron. For that reason I changed my mind. Relevant prediction was 85.4%
– non-disclosure contract with 41.8% relevant prediction. I stuck with my original decision and didn’t change, but it was a close call as other non disclosure agreements had termination provisions (this one did not) and I had called the others with such provisions as relevant.
– a foreign language email sending picture was 78.6% predicted relevant. Computer was obviously wrong.
– email that on top was about crude oil, but below was about severance. Very unusual. I missed that before. 12512165. I changed the coding to relevant. It had a 36.1% probability rank.
– another email just like above. I was wrong. 32.8% probability.
– email about severance calculation that I made mistaken before as irrelevant and now corrected. 29.4% probability.
– email re employee termination that I missed before as the language was near end of otherwise irrelevant discussion 47.5% probability
– 3 agreements between companies that had termination language. 89.7% probable, but computer is wrong. Not about employees. I was about deal contract terminations between companies.
– list of 7 employees in an email. 60.2%, but computer is wrong as nothing relevant 12832822
– waiver of benefits, 52.6% predicted relevant but computer is wrong, not relevant
• total relevant after corrections is now exactly 300
32. 4 relevant found from 200.
• email re termination and rescissions. Predicted relevant at 62.8%. Only document over 28% predicted relevant in this 200 group
• next highest ranked document was 27% probable relevant, about terminated employees 12007207
• email question re part time employees and severance
• email re suggestion on severance plan and severance
33. 1 relevant found from 200. Note, additional QC finds 7 mistaken irrelevant, which were corrected. And one new relevant found by the QC ranking search. Total net gain of 8.
• email thanking Ken Lay for remaining $200 Million 15511524
• The QC search was a 25%+ probable relevant but uncategorized relevant search. Had 19 results. 10 were correctly categorized as irrelevant. 2 not categorized at all. Of these, one was relevant 69.9%, another was not 52.4%. 7 mistakes found in my prior coding of the documents as irrelevant. Net gain of eight relevant.
34. 9 relevant found from 200.
• Started with a QC of relevant search 25%+ not categorized relevant – 10 docs found. No mistakes.
• Of the 200 machine selected, 9 relevant were found
• email re decision on which employees in a small group to keep and which to terminate 12841827
• email re employee complaint re severance
• 3 more emails re Kim Lay’s won’t take the $200 million bonus
• email re severance
• email related to Key Lay $200 Million
• email re buyer and severance terms
• email re revocation and offers and signing bonus
35. 16 relevant found from 200.
• email re termination and an employment contract
• 4 emails re Fastow rumor and payout clause
• 2 forwards of Fastow rumor email
• notes re floor meeting included termination
• bankruptcy and severance
• re rescissions of offers
• taking points
• re: Ken Lay’s email
• Q&A type memos, includes severance
• email re job offer rescission
• email re offer rescission
• re severance and bankruptcy sale of entity
36. 10 relevant found from 200.
• 2 emails re Fastow rumor
• Q&A type
• Korean employee termination
• severance and Dynergy sale
• employment contract and severance
• offer rescind
• offer rescind
• offer rescind
• emp. contract related
• QC Search using 25% and not marked relevant = 10. Same as before. All irrelevant.
37. 5 relevant found from 200.
• re employment contract termination provisions
• Employee firing. Strong. 12005248
• non-disclosure agreement with termination language
• note re Dynergy meeting severance
• offer rescission
38. 10 relevant found from 200.
• employee contract re termination
• 4 – Q&A type
• offer rescission related
• 2 – rescission related
• employee term in sale of company
• foreign employee termination
• payment error on terminated employee
• for cause terminations
• rescission
• QC search 25% + not categorized relevant: 10. Same as before. No changes.
39. 16 relevant found from 200.
• employee complaint re termination
• foreign employee termination
• 3 – employment contract and term provisions
• severance contract related
• termination and bankruptcy related
• mistaken termination
• foreign separation contract
• employee complaint re firing and benefits
• employee contract re termination
• re litigation
• re termination
• employee litigation
• offer rescission
• offer rescission
40. 9 relevant found from 200. Another 50 found from search of 25%+ not previously categorized. Total 59.
• employee complaint re termination
• no terminations to be announced on thanksgiving
• EEOC case was discussed
• Complaint re severance. Strong relevance. 12005256
• email re CEO termination in sale and severance from David Oxley to Louise Kitchen
• mistaken termination notice
• email re termination of employees and benefits
• email re termination of employees and benefits
• re termination timing
• Rand a search for all 25%+, but not previously categorized search. Total 62 found in that search. Review of all of them shows that 50 of them are relevant, and 12 were not.
• Relevant count search shows total now at 444
41. 10 relevant found from 200. Another 3 found from 25% + search – 13 total.
• re termination notices
• 2 re severance payout
• mistaken severance notice
• termination benefits
• Terminated employees
• terminated foreign citizen employee
• 2 – termination action plan
• mistaken termination notice
• “may Ken Lay rot in Hell” – disgruntled employee 15516349
• Ran a 25%+ probable relevant but not categorized as relevant. 15 found. 3 were in fact relevant. No mistakes in my coding.
42. 9 relevant found from 200. Another 2 found from 25%+ search – total 11.
• re termination bonus
• complaint re review and severance
• complaint re notice of benefits
• 2 – complaint re notice of benefits
• re employment contract for Japan and termination
• re terminations
• terminations and stock options
• termination letters
• Ran a 25%+ search and found 17 not categorized. Only 2 were relevant.
– One prior mistakes in coding where I missed a reference to termination, It was 31.7% probable relevant. Pertained to Leaf River. 12006992
• check on total number of relevant shows 468
• Metrics check shows I have now reviewed 9,893 documents (114,037 pgs)
– 9,425 were irrelevant
– 468 were relevant
43. 4 relevant found from 200.
• re non-compete for laid off employees
• re Japanese employee’s contract and termination
• complaint re fairness of termination selection
• Japanese employee lawsuit
44. 4 relevant found from 200. Another 4 mistakes corrected – total 8.
• complaint email to Kim Kay re $80 million bonus 15507937
• severance packages for terminated employees
• employment letter mentions severance payments
• concerning an impromptu firing for Internet posting
• Ran a 25%+ not categorized relevant and 9 were found. 4 were relevant. I had made a mistake on two documents, one of which had three copies:
– 3 Q&A severance with a severance mention I missed before. 12009822
– non-disclosure contract where close study showed it had a termination provision in it.
45. 8 relevant found out of the 200. Another 4 from QC – total 12.
• Q&A type
• discussion re severance in buy out
• reimbursement contract mentions termination
• ques. re severance plan (close question)
• emp. contract and severance
• severance calculations
• severance calculations
• ques. re termination and severance
• Ran a 25%+ not categorized as relevant search and 10 found. I found 6 to be irrelevant, but 4 were relevant. These had all previously been marked by me as irrelevant. I changed my mind on 4 total. Three here described (forgot to describe the last one):
– Visa related question. Close ques. 49.4%. 12010923
– question re severance and tuition reimbursement 34.2%
– an emp. Contract. Close question; see paragraph 4. 29.7%. 12000991
• to date I’ve trained 9,429 docs, reviewed total of 10,493 files and 116,309 pages
• 492 total relevant
46. 5 relevant found out of 200.
• bonus forms with termination provisions
• Japan terminated manager, relevant part at end
• eliminating positions
• mistaken termination
• no planned layoffs for one office
47. 18 relevant found out of 200.
• Note I reviewed the 200 by relevancy ranking. The top four highest ranked were relevant. 58% -> 36%
– 1 was law suit re EEOC,
– 3 were termination benefits
• severance plan
• termination and savings
• employment reinstatement after termination
• 2 – employment termination (13th in ranking). So this means 10 out of top 13 ranked were relevant.
• change link in above email on termination and savings. (Now 11 out of top 14 were relevant.)
• wrongfully terminated employee. (Now 12 out of top 15.)
• Q&A related (now 13/17)
• 3 – Q&A – 16/21 top ranked; slowed down when hit below 10% probable relevance.
• 2 – relevant legal memos re closure of plant and union regulations. Had an IP relevance score of only .0000687131, but it had a probability score of 33.8%. It was in fact strong relevance of a new document type, (2 copies) #12002609 #12003939 (took picture).
• Note – this round took over an hour, as did several of the prior rounds, where I ran into longer documents and close calls.
48. 16 relevant found out of 200.
• 32 of the 200 were obvious by file name junk files of the kind I had seen before. Bulk coded them all irrelevant
• 4 others were found that had already been coded irrelevant. They were all obvious irrelevant.
• I sorted the remaining documents by IP score and looked at most likely relevant on down to get a better sense of training.
• The highest probability ranked was .7980, an email – 4112126. It was a question about severance plan, which I have seen before on another part of the email chain, or one close to it. Marked relevant (1). Note this email had only a 6.9% probability in the category ranking.
• Next 2 highest ranked were same email type having to do with a list of employees who may have been laid off. 3 more later found 6th are 8th and 11th ranked. A total of relevant (5). 13757418 and 13757419.
• the 4th highest ranked doc was an email on reinstatement that I judged close, but decided was relevant (1) – 3107238
• 2 Q&As, which I’d seen before – both relevant (2) – 12010371 and 12007128. Ranked only 3.2% in category relevance and also .32 (32%) in IP score.
• 1 email re Q&A talking point. Only 2.3% category relevant
• 3 – emails re headcount identifying who will be cut. All relevant. All had only 7.6% probability
• 1 email re French subsidiary employee future
• 1 email again on employee lists, which I think was done for purposes related to termination. Close question.
• 1 borderline relevant
• After this point it was all irrelevant showing n IP score effectiveness
• 533 – total relevant found so far
49. 14 relevant found out of 200.
• I sorted all of the 200 by IP score again for review to try to get a better sense of ranking and whether more rounds would be productive.
• 2 – highest IP score was .694 with category probability of 56.3% – 13759801. They are emails re 4 employees wanting to know if still employed or not. Borderline, but I say relevant again. Another in chain.
• Q&A answer type – relevant – 120006812
• Email re eliminating positions was relevant; but the next document, with 6th highest rank was borderline, but not relevant.
• 7th ranked is relevant – another talking points memo
• 2 – 8th and 10th ranked are obvious relevant, but only cat. prob. of 9.8% (IP score of .347)
• 2 – email and response by employee indicating when he thinks he’ll be terminated
• email re termination and non-compete
• email saying a particular employee shouldn’t be “fired.”
• Note: up to here I’ve reviewed top 19 ranked docs and 13 have been relevant.
• email re waiver form for separation being illegal – 12011427
• email re analysis of who should be terminated; interesting – 3817115
• Note after around the top ranked120 I switched to file name sort as all were probably irrelevant anyway and its faster to review with that sort view in place.
• 1 odd email of no importance was found relevant after that; an outline re where to find terminated employees email – 8909940 – category probability only 1.0%
50. 13 relevant found out of 200. An additional 11 more relevant from 25%+ category searches. Total 24.
• before any review a search shows 550 docs are 50%+ probable relevant and 55 docs of the 550 were not yet categorized relevant. I reviewed these and the 200 from machine selected.
• First marked 81 obvious irrelevant by file name order. The switched to file raking order to review the rest; only 3 docs had .54, .58 and .706; the rest were under .54
• Top ranked .706 – #13723687 re an employee termination. I had seen another earlier part of this email chain before. Her boss didn’t want to lose her.
• 2nd ranked was another talking points memo
• 0 – 3rd ranked – close call, but I know from other emails that the employee list here discussed pertains to who gets retention bonuses, not who gets terminated. Not relevant.
• 4th ranked .466 – is relevant; employee list, but this one pertains to terminations
• list email, close call, but relevant. .406
• list email, close call, but relevant.
• email re keeping the employee again, same before. .389
• another close relevant, repeat re list
• another re list and cuts of employee. Only 8.9% cat. prob. and .356 IP score
#13758900
• email asking question re bankruptcy court and payments to terminated employees. Had not seen before #15507580 – only 10% category probability.
• Another re keeping same employee (Deirdre)
• 2 emails re keeping tow other people
• Note: at this point I am down to the lowest ranked 92 where I find only one relevant, next described. Also, I’m seeing many emails re termination, but involves deal contract terminations between companies.
• Email from fired employee complaining re low severance.) After that was a funny (and dirty) irrelevant email – 10617832.)
• Run total relevant searches and find 567 have been categorized relevant, and 47,021 categorized irrelevant.
• Run probability ranked searches and find 520 documents are ranked 50%+. Of those, 15 were not categorized relevant. Ran a 25%+ and only found 25 more documents, meaning only 10 documents between 25% and 50% probable relevant.
• Reviewed all of the 25%+ higher documents (total 25) that were not categorized relevant. Of those, 11 were not previously categorized. All were reviewed and found to be relevant. The other 14 had been previously reviewed and marked irrelevant. I reviewed them again. Most of these were close calls, but I still considered all of them irrelevant and did not change any. Here are the documents from the not-reviewed 11, where I found them all to be relevant:
• 2 – re terminated employee list – 13759551 and 13723640
• 4 – re position lists with rationale – 13757156
• 2 – employees and positions not to terminate – 9703787
• keep two employees, seen before
• 2 – re save two employees from cut, seen before
• New Total Relevant found is 578
STOPPED ROUNDS HERE AND PERFORM QUALITY ASSURANCE TEST
Decision to stop was based on the few documents found going all of the way down to 25%+, the lack of any real new documents in several rounds, and the total time expended to date, which is about same as time expended in the prior multimodal before final test.
[…] in the Ashes of Enron (detailed description of a multimodal search of 699,082 ENRON documents); Borg Challenge (description of same search using a semi-automated monomodal method). Worst case scenario, […]
[…] Borg Challenge: The Complete Report – http://bit.ly/ZwNKrd (@RalphLosey) […]
[…] A series of videos and blogs describing the review have also been published on the author’s blog. Borg Challenge: Report of my experimental review of 699,082 Enron documents using a semi-automated m… (2013). The video reports include satirical segments based on the Startrek Borg villains to try to […]
[…] with greater particularity in the search narratives. Predictive Coding Narrative (2012); Borg Challenge Report (2013). A random sample of 1,507 documents was made in the first review wherein 2 relevant […]
[…] Challenge: Report of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodo… (a five-part written and video series comparing two different kinds of predictive coding search […]
[…] Coding. I even went so far as to test that approach myself and reported on it. Borg Challenge: Report of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodo… (a five-part written and video series comparing two different kinds of predictive coding search […]
[…] in my fifty-hour Borg protocol test I used something close to this SAL protocol. Borg Challenge: Report of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodo… (a five-part written and video series comparing two different kinds of predictive coding search […]