 I have uncovered a new method for calculating recall in legal search projects that I call ei-Recall, which stands for elusion interval recall. I offer this to everyone in the e-discovery community in the hope that it will replace the hodgepodge of methods currently used, most of which are statistically invalid. My goal is to standardize a new best practice for calculating recall. Towards this end I will devote the next three blogs to ei-Recall. Parts One and Two will describe the formula in detail, and explain why I think it is the new gold standard. Part Two will also provide a detailed comparison with Herb Roitblat’s eRecall. Part Three will provide a series of examples as to how ei-Recall works.
I have uncovered a new method for calculating recall in legal search projects that I call ei-Recall, which stands for elusion interval recall. I offer this to everyone in the e-discovery community in the hope that it will replace the hodgepodge of methods currently used, most of which are statistically invalid. My goal is to standardize a new best practice for calculating recall. Towards this end I will devote the next three blogs to ei-Recall. Parts One and Two will describe the formula in detail, and explain why I think it is the new gold standard. Part Two will also provide a detailed comparison with Herb Roitblat’s eRecall. Part Three will provide a series of examples as to how ei-Recall works.
I received feedback on my ideas and experiments from the top two scientists in the world with special expertise in this area, William Webber and Gordon Cormack. I would likely have presented one of my earlier, flawed methods, but for their patient guidance. I finally settled on the ei-Recall method as the most accurate and reliable of them all. My thanks and gratitude to them both, especially to William, who must have reviewed and responded to a dozen earlier drafts of this blog. He not only corrects logics flaws, and there were many, but also typos! As usual any errors remaining are purely my own, and these are my opinions, not theirs.
ei-Recall is preferable to all other commonly used methods of recall calculation, including Roitbalt’s eRecall, for two reasons. First, ei-Recall includes interval based range values, and, unlike eRecall, and other simplistic ratio methods, is not based on point projections. Second, and this is critical, ei-Recall is only calculated at the end of a project, and depends on a known, verified count of True Positives in a production. It is thus unlike eRecall, and all other recall calculation methods that depend on an estimated value for the number of True Positives found.
Yes, this does limit the application of ei-Recall to projects in which great care is taken to bring the precision of the production to near 100%, including second reviews, and many quality control cross-checks. But this is anyway part of the workflow in many Continuous Active Learning (CAL) predictive coding projects today. At least it is in mine, where we take great pains to meet the client’s concern to maintain the confidentiality of their data. See: Step 8 of the EDBP (Electronic Discovery Best Practices), which I call Protections and is the step after first pass review by CAR (computer assisted review, multimodal predictive coding).
Advanced Summary of ei-Recall
 I begin with a high level summary of this method for my more advanced readers. Do not be concerned if this seems fractured and obtuse at first. It will come into clear 3-D focus later as I describe the process in multiple ways and conclude in Part Three with examples.
I begin with a high level summary of this method for my more advanced readers. Do not be concerned if this seems fractured and obtuse at first. It will come into clear 3-D focus later as I describe the process in multiple ways and conclude in Part Three with examples.
ei-Recall calculates recall range with two fractions. The numerator of both fractions is the actual number of True Positives found in the course of the review project and verified as relevant. The denominator of both fractions is based on a random sample of the documents presumed irrelevant that will not be produced, the Negatives. The percentage of False Negatives found in the sample allows for a calculation of a binomial range of the total number of False Negatives in the Negative set. The denominator of the low end recall range fraction is the high end number of the projected range of False Negatives, plus the number of True Positives. The denominator of the high end recall range fraction is the low end number of the projected range of False Negatives, plus the number of True Positives.
Here is the full algebraic explanation of ei-Recall, starting with the definitions for the symbols in the formula.
- Rl stands for the low end of recall range.
- Rh stands for high end of recall range
- TP is the verified total number of relevant documents found in the course of the review project.
- FNl is the low end of the False Negatives projection range based on the low end of the exact binomial confidence interval.
- FNh is the high end of the False Negatives projection range based on the high end of the exact binomial confidence interval.
Formula for the low end of the recall range:
Rl = TP / (TP+FNh).
Formula for the high end of the recall range:
Rh = TP / (TP+FNl).
This formula essentially adds the extreme probability ranges to the standard formula for recall, which is: R = TP / (TP+FN).

Quest for the Holy Grail of Recall Calculations
 I have spent the last few months in intense efforts to bring this project to conclusion. I have also spent more time writing and rewriting this blog than any I have ever written in my eight plus years of blogging. I wanted to find the best possible recall calculation method for e-discovery work. I convinced myself that I needed to find a new method in order to take my work as a legal search and review lawyer to the next level. I was not satisfied with my old ways and methods of quality control of large legal search projects. I was not comfortable with my prevalence based recall calculations. I was not satisfied with anyone else’s recall methods either. I had heard the message of Gordon Cormack and Maura Grossman clearly stated right here in their guest blog of September 7, 2014: Talking Turkey. In their conclusion they stated:
I have spent the last few months in intense efforts to bring this project to conclusion. I have also spent more time writing and rewriting this blog than any I have ever written in my eight plus years of blogging. I wanted to find the best possible recall calculation method for e-discovery work. I convinced myself that I needed to find a new method in order to take my work as a legal search and review lawyer to the next level. I was not satisfied with my old ways and methods of quality control of large legal search projects. I was not comfortable with my prevalence based recall calculations. I was not satisfied with anyone else’s recall methods either. I had heard the message of Gordon Cormack and Maura Grossman clearly stated right here in their guest blog of September 7, 2014: Talking Turkey. In their conclusion they stated:
We hope that our studies so far—and our approach, as embodied in our TAR Evaluation Toolkit—will inspire others, as we have been inspired, to seek even more effective and more efficient approaches to TAR, and better methods to validate those approaches through scientific inquiry.
I had already been inspired to find better methods of predictive coding, and have uncovered an efficient approach with my multimodal CAL method. But I was still not satisfied with my recall validation approach, I wanted to find a better method to scientifically validate my review work.
Like almost everyone else in legal search, including Cormack and Grossman, I had earlier rejected the so called Direct Method of recall calculation. It is unworkable and very costly, especially in low prevalence collections where it requires sample sizes in the tens of thousands of documents. See Eg. Grossman & Cormack, Comments on ‘The Implications of Rule 26(g) on the Use of Technology-Assisted Review,’ Federal Courts Law Review, Vol. 7, Issue 1 (2014) at 306-307 (“The Direct Method is statistically sound, but is quite burdensome, especially when richness is low.”)
Like Grossman and Cormack, I did not much like any of the other sampling alternatives either. Their excellent Comments articles discusses and rejects Roitblat’s eRecall, and two other methods by Karl Schieneman and Thomas C. Gricks III, which Grossman and and Cormack call the Basic Ratio Method and Global Method. Supra at 307-308.
I was on a quest of sorts for the Holy Grail of recall calculations. I knew there had to be a better way. I wanted a method that used sampling with interval ranges as a tool to assure the quality of a legal search project. I wanted a method that created as accurate an estimate as possible. I also wanted a method that relied on simple fraction calculations and did not depend on advanced math to narrow the binomial ranges, such as William Webber’s favorite recall equation: the Beta-binomial Half formula, shown below.

Webber, W., Approximate Recall Confidence Intervals, ACM Transactions on Information Systems, Vol. V, No. N, Article A, Equation 18, at pg. A:13 (October 2012).
Before settling on my much simpler algebraic formula I experimented with many other methods to calculate recall ranges. Most were much more complex and included two or more samples, not just one. I wanted to try to include a sample that I usually take at the beginning of a project to get a rough idea of prevalence with interval ranges. These were the examples shown by my article, In Legal Search Exact Recall Can Never Be Known, and described in the section, Calculating Recall from Prevalence. I wanted to include the first sample, and prevalence based recall calculations based on that first sample, with a second sample of excluded documents taken at the end of the project. Then I wanted to kind of average them somehow, including the confidence interval ranges. Good idea, but bad science. It does not work, statistically or mathematically, especially in low prevalence.
I found a number of other methods, which, at first, looked like the Holy Grail. But I was wrong. They were made of lead, not gold. Some of the one’s that I dreamed up were made of fools gold! A couple of the most promising methods I tried and rejected used multiple samples of various stratas. That is called stratified random sampling as compared to simple sampling.
My questionable, but inspired research method for this very time consuming development work consisted of background reading, aimless pondering, sleepless nights, intuition, trial and error (appropriate I suppose for a former trial lawyer), and many consults with the top experts in the field (another old trial lawyer trick). I ran though many other alternative formulas. I did the math in several standard review project scenarios, only to see the flaws of these other methods in certain circumstances, primarily low prevalence.
Every experiment I tried with added complexity, and added effort of multiple samples, proved to be fruitless. Indeed, most of this work was an exercise in frustration. (It turns out that noted search expert Bill Dimm is right. There is no free lunch in recall.) My experiments, and especially the expert input I received from Webber and Cormack, all showed that the extra complexities were not worth the extra effort, at least not for purposes of recall estimation. Instead, my work confirmed that the best way to channel additional efforts that might be appropriate in larger cases is simply to increase the sample size. This, and my use of confirmed True Positives, are the only sure-fire methods to improve the reliability of recall range estimates. They are the best ways to lower the size of the interval spread that all probability estimates must include.
Finding the New Gold Standard
 ei-Recall meets all of my goals for recall calculation. It maintains mathematical and statistical integrity by including probable ranges in the estimate. The size of the range depends on the size of the sample. It is simple and easy to use, and easy to understand. It can thus be completely transparent and easy to disclose. It is also relatively inexpensive and you control the costs by controlling the sample size (although I would not recommend a sample size of less than 1,500 in any legal search project of significant size and value).
ei-Recall meets all of my goals for recall calculation. It maintains mathematical and statistical integrity by including probable ranges in the estimate. The size of the range depends on the size of the sample. It is simple and easy to use, and easy to understand. It can thus be completely transparent and easy to disclose. It is also relatively inexpensive and you control the costs by controlling the sample size (although I would not recommend a sample size of less than 1,500 in any legal search project of significant size and value).
Finally, by using verified True Positives, and basing the recall range calculation on only one random sample, one of the null set, instead of two samples, the chance factor inherent to all random sampling is reduced. I described these chance factors in detail in In Legal Search Exact Recall Can Never Be Known, in the section on Outliers and Luck of Random Draws. The possibility of outlier events is still possible using ei-Recall, but is minimized by limiting the sample to the null set and only estimating a projected range of False Positives. While it is true that the prevalence based recall calculations described in In Legal Search Exact Recall Can Never Be Known, also only use one random sample, that is a sample of the entire document collection to estimate a projected range of relevant documents, True Positives. The number of relevant documents found will (or at least should be in any half-way decent search) be a far larger number than the number of False Negatives. For that reason alone the variability range (interval spread) of the straight elusion recall method should typically be smaller and more reliable.
Focus Your Sampling Efforts on Finding Errors of Omission
 The number of documents presumed irrelevant, the Negatives, or null set, will always be smaller than the total document collection, unless of course you found no relevant documents at all! This means you will always be sampling a smaller dataset when doing an elusion sample, than when doing a prevalence sample of the entire collection. Therefore, if you are trying to find your mistakes, the False Negatives, look for them where they might lie, in the smaller Negative set, the null set. Do not look for them in the larger complete collection, which includes the documents you are going to produce, the Positive set. Your errors of omission, which is what you are trying to measure, could not possibly be there. So why include that set of documents in the random sample? That is why I reject the idea of taking a sample at the end of the entire collection, including the Positives.
The number of documents presumed irrelevant, the Negatives, or null set, will always be smaller than the total document collection, unless of course you found no relevant documents at all! This means you will always be sampling a smaller dataset when doing an elusion sample, than when doing a prevalence sample of the entire collection. Therefore, if you are trying to find your mistakes, the False Negatives, look for them where they might lie, in the smaller Negative set, the null set. Do not look for them in the larger complete collection, which includes the documents you are going to produce, the Positive set. Your errors of omission, which is what you are trying to measure, could not possibly be there. So why include that set of documents in the random sample? That is why I reject the idea of taking a sample at the end of the entire collection, including the Positives.
The Positives, the documents to be produced, have already been verified enough under my two-pass system. They have been touched multiple times by machines and humans. It is highly unlikely there will be False Positives. Even if there are, the requesting party will not complain about that. Their concern should be on completeness, or recall, especially if any precision errors are minor.
There is no reason to include the Positives in a final recall search in any project with verified True Positives. That just unnecessarily increases the total population size and thereby increases the possibility of an inaccurate sample. Estimates made from a sample of 1,500 documents of a collection of 150,000 documents will be more accurate, more reliable, than estimates made from a sample of 1,500 documents in another much larger collection of 1,500,000. The only exception is when there is an even distribution of target documents making up half of the total collection – 50% prevalence.
 Sample size does not scale perfectly, only roughly, and the lower the prevalence, the more inaccurate it becomes. That is why sampling is not a miracle tool in legal search, and recall measures are range estimates, not certainties. In Legal Search Exact Recall Can Never Be Known. Recall measure when done right, as it is in ei-Recall, is a powerful quality assurance tool, to be sure, but it is not the end-all of quality control measures. It should be part of a larger tool kit that includes several other quality measures and techniques. The other quality control methods should be employed throughout the review, not just at the end like ei-Recall. Maura Grossman and Gordon Cormack agree with me on this. Comments on ‘The Implications of Rule 26(g) on the Use of Technology-Assisted Review,’ supra at 285. They recommend that validation:
Sample size does not scale perfectly, only roughly, and the lower the prevalence, the more inaccurate it becomes. That is why sampling is not a miracle tool in legal search, and recall measures are range estimates, not certainties. In Legal Search Exact Recall Can Never Be Known. Recall measure when done right, as it is in ei-Recall, is a powerful quality assurance tool, to be sure, but it is not the end-all of quality control measures. It should be part of a larger tool kit that includes several other quality measures and techniques. The other quality control methods should be employed throughout the review, not just at the end like ei-Recall. Maura Grossman and Gordon Cormack agree with me on this. Comments on ‘The Implications of Rule 26(g) on the Use of Technology-Assisted Review,’ supra at 285. They recommend that validation:
consider all available evidence concerning the effectiveness of the end-to-end review process, including prior scientific evaluation of the TAR method, its proper application by qualified individuals, and proportionate post hoc sampling for confirmation purposes.
Ambiguity in the Scope of the Null Set
 There is an open-question in my proposal as to exactly how you define the Negatives, the presumed irrelevant documents that you sample. This may be varied somewhat depending on the circumstances of the review project. In my definition above I said the Negatives were the documents presumed to be irrelevant that will not be produced. That was intentionally somewhat ambiguous. I will later state with less ambiguity that Negatives are the documents not produced (or logged for privilege). Still, I think this application should be varied sometimes according to the circumstances.
There is an open-question in my proposal as to exactly how you define the Negatives, the presumed irrelevant documents that you sample. This may be varied somewhat depending on the circumstances of the review project. In my definition above I said the Negatives were the documents presumed to be irrelevant that will not be produced. That was intentionally somewhat ambiguous. I will later state with less ambiguity that Negatives are the documents not produced (or logged for privilege). Still, I think this application should be varied sometimes according to the circumstances.
In some circumstances you could improve the reliability of an elusion search by excluding from the null set all documents coded irrelevant by an attorney, either with or without actual review. The improvement would arise from shrinking the size of the number of documents to be sampled. This would allow you to focus your sample on the documents most likely to have an error.
For example, you could have 50,000 documents out of 900,000 not produced, that have actually been read or skimmed by an attorney, and coded irrelevant. You could have yet another 150,000 that have not been actually been read or skimmed by an attorney, but have been bulked coded irrelevant by an attorney. This would not be uncommon in some projects. So even though you are not producing 900,000 documents, you may have manually coded 200,000 of those, and only 700,000 have been presumed irrelevant on the basis of computer search. Typically in predictive coding driven search that would be because their ranking at the end of the CAL review was too low to warrant further consideration. In a simplistic keyword search they would be documents omitted from attorney review because they did not contain a keyword.
In other circumstances you might want to include the documents attorneys reviewed and coded as irrelevant, for instance, where you were not sure of the accuracy of their coding for one reason or another. Even then you might want to exclude other sets of documents for other grounds. For instance, in predictive coding projects you may want to exclude some bottom strata of the rankings of probable relevance. For example, you could exclude the bottom 25%, or maybe the bottom 10%, or bottom 2%, where it is highly unlikely that any error has been made in predicting irrelevance of those documents.
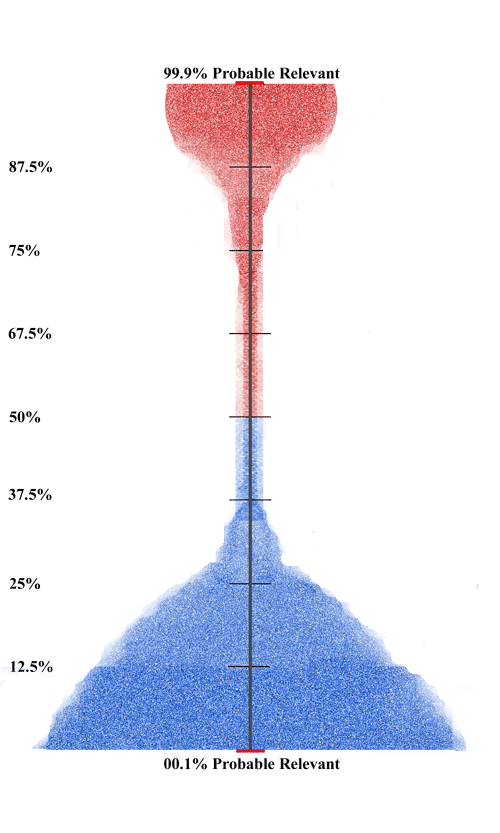 In the data visualization diagram I explained in Visualizing Data in a Predictive Coding Project – Part Two (shown right) you could exclude some bottom portion of the ranked documents shown in blue. You could, for instance, limit the Negatives searched to those few documents in the 25% to 50% probable relevance range. Of course, whenever you limit the null set, you have to be careful to adjust the projections accordingly. Thus, if you find 1% False Negatives in a sample of a presumably enriched sub-collection of 10,000 out of 100,000 total Negatives, you cannot just project 1% of 100,000 and assume there are a total of 1,000 False Negatives (plus or minus of course). You have to project the 1% from the sample of the size of the sub-collection sampled, and so it would be 1% of 10,000, or 100 False Negatives, not 1,000, again subject to the confidence interval range, a range that varies according to your sample size.
In the data visualization diagram I explained in Visualizing Data in a Predictive Coding Project – Part Two (shown right) you could exclude some bottom portion of the ranked documents shown in blue. You could, for instance, limit the Negatives searched to those few documents in the 25% to 50% probable relevance range. Of course, whenever you limit the null set, you have to be careful to adjust the projections accordingly. Thus, if you find 1% False Negatives in a sample of a presumably enriched sub-collection of 10,000 out of 100,000 total Negatives, you cannot just project 1% of 100,000 and assume there are a total of 1,000 False Negatives (plus or minus of course). You have to project the 1% from the sample of the size of the sub-collection sampled, and so it would be 1% of 10,000, or 100 False Negatives, not 1,000, again subject to the confidence interval range, a range that varies according to your sample size.
Remember, the idea is to focus your random search to find mistakes on the group of documents that are most likely to have mistakes. There are many possibilities.
In still other scenarios you might want to enlarge the Negatives to include documents that were never included in the review project at all. For instance, if you collected emails from ten custodians, but eliminated three as unlikely to have relevant information as per Step 6 of the EDBP (culling), and only reviewed the email of seven custodians, then you might want to include select documents from the three excluded custodians in the final elusion test.
There are many other variations and issues pertaining to the scope of the Negatives set searched in ei-Recall. There are too many to discuss in this already long article. I just want to point out in this introduction that the makeup and content of the Negatives sampled at the end of the project is not necessarily cut and dry.
Advantage of End Project Sample Reviews
 Basing recall calculations on a sample made at the end of a review project is always better than relying on a sample made at the beginning. This is because final relevance standards will have been determined and fully articulated by the end of a project. Whereas at the beginning of any review project, the initial relevance standards will be tentative. They will typically change in the course of the review. This is known as relevance shift, where the understanding of relevance changes and matures during the course of the project.
Basing recall calculations on a sample made at the end of a review project is always better than relying on a sample made at the beginning. This is because final relevance standards will have been determined and fully articulated by the end of a project. Whereas at the beginning of any review project, the initial relevance standards will be tentative. They will typically change in the course of the review. This is known as relevance shift, where the understanding of relevance changes and matures during the course of the project.
This variance of adjudication between samples can be corrected during and at the end of the project by careful re-review and correction of initial sample relevance adjudications. This also requires correction of changes of all codings made during the review in the same way, not just inconsistencies in sample codings.
The time and effort spent to reconcile the adjudications might be better spent on a larger sample size of the final elusion sample. Except for major changes in relevance, where you would anyway have to go back and make corrections as part of quality control, it may not be worth the effort to remediate the first sample, just so you can still use it again at the end of the project with an elusion sample. That is because of the unfortunate statistical fact of life, that the two recall methods cannot be added to one another to create a third, more reliable number. I know. I tried. The two recall calculations are apples and oranges. Although a comparison between the two range values is interesting, they cannot somehow be stacked together to improve the reliability of either or both of them.
Prevalence Samples May Still Help Guide Search, Even Though They Cannot Be Reliably Used to Calculate Recall
 I like to make a prevalence sample at the beginning of a project to get a general idea of the number of relevant documents there might be, and I emphasize general and might, in order to help with my search. I used to make recall calculation from that initial sample too, but no longer (except in small cases under the theory it is better than nothing), because it is simply too unreliable. The prevalence samples can help with search, but not with recall calculations used to test the quality of the search results. For quality testing it is better to sample the null set and calculate recall using the ei-Recall method.
I like to make a prevalence sample at the beginning of a project to get a general idea of the number of relevant documents there might be, and I emphasize general and might, in order to help with my search. I used to make recall calculation from that initial sample too, but no longer (except in small cases under the theory it is better than nothing), because it is simply too unreliable. The prevalence samples can help with search, but not with recall calculations used to test the quality of the search results. For quality testing it is better to sample the null set and calculate recall using the ei-Recall method.
Still, if you are like me, and like to take a sample at the start of a project for search guidance purposes, then you might as well do the math at the end of the project to see what the recall range estimate is using the prevalence method described in In Legal Search Exact Recall Can Never Be Known. It is interesting to compare the two recall ranges, especially if you take the time and trouble to go back and correct the first prevalence sample adjudications to match those of calls made in your second null set sample (that can eliminate the problem of concept drift and reviewer inconsistencies). Still, go with the recall range values of the ei-Recall, not prevalence. It is more reliable. Moreover, do not waste your time, as I did for weeks, trying to somehow average out the results. I traveled down that road and it is a dead-end.
Claim for ei-Recall
 My claim is that ei-Recall is the most accurate recall range estimate method possible that uses only algebraic math within everyone’s grasp. (This statement is not exactly true because binomial confidence interval calculations are not simple algebra, but we avoid these calculations by use of an online calculator. Many are available.) I also claim that ei-Recall is more reliable, and less prone to error in more situations, than a standard prevalence based recall calculation, even if the prevalence recall includes ranges as I did in In Legal Search Exact Recall Can Never Be Known.
My claim is that ei-Recall is the most accurate recall range estimate method possible that uses only algebraic math within everyone’s grasp. (This statement is not exactly true because binomial confidence interval calculations are not simple algebra, but we avoid these calculations by use of an online calculator. Many are available.) I also claim that ei-Recall is more reliable, and less prone to error in more situations, than a standard prevalence based recall calculation, even if the prevalence recall includes ranges as I did in In Legal Search Exact Recall Can Never Be Known.
I also claim that my range based method of recall calculation is far more accurate and reliable than any simple point based recall calculations that ignore or hide interval ranges, including the popular eRecall. This later claim is based on what I proved in In Legal Search Exact Recall Can Never Be Known, and is not novel. It has long been known and accepted by all experts in random sampling, that recall projections that do not include high-low ranges are inexact and often worthless and misleading. And yet attorneys and judges are still relying on point projections of recall to certify the reasonableness of search efforts. The legal profession and our courts need to stop relying on such bogus science and turn instead to ei-Recall.
I am happy to concede that scientists who specialize in this area of knowledge like Dr. Webber and Professor Cormack can make slightly more accurate and robust calculations of binomial recall range estimates by using extremely complex calculations such as Webber’s Beta-binomial formula.
 Such alternative black box type approaches are, however, disadvantaged by the additional expense from expert consultations and testimony to implement and explain. (Besides, at the present time, neither Webber nor Cormack are available for such consultations.) My approach is based on multiplication and division, and simple logic. It is well within the grasp of any attorney or judge (or anyone else) who takes the time to study it. My relatively simple system thus has the advantage of ease of use, ease of understanding, and transparency. These factors are very important in legal search.
Such alternative black box type approaches are, however, disadvantaged by the additional expense from expert consultations and testimony to implement and explain. (Besides, at the present time, neither Webber nor Cormack are available for such consultations.) My approach is based on multiplication and division, and simple logic. It is well within the grasp of any attorney or judge (or anyone else) who takes the time to study it. My relatively simple system thus has the advantage of ease of use, ease of understanding, and transparency. These factors are very important in legal search.

Although the ei-Recall formula may seem complex at first glance, it is really just ratios and proportions. I reject the argument some make that calculations like this are too complex for the average lawyer. Ratios and proportions are part of the Grade 6 Common Core Curriculum. Reducing word problems to ratios and proportions is part of the Grade 7 Common Core, so too is basic statistics and probability.
Overview of How ei-Recall Works
ei-Recall is designed for use at the end of a search project as a final quality assurance test. A single random sample is taken of the documents that are not marked relevant and so will not be produced or privileged-logged – the Negatives. (As mentioned, definition and scope of the Negatives can be varied depending on project circumstances.) The sample is taken to estimate the total number of False Negatives, documents falsely presumed irrelevant that are in fact relevant. The estimate projects a range of the probable total number of False Negatives using a binomial interval range in accordance with the sample size. A simplistic and illusory point value projection is not used. The high end of the range of probable False Negatives is shown in the formula and graphic as FNh. The low end of the projected range of False Negatives is FNl.
This type of search is generally called an elusion based recall search. As will be discussed here in some detail, well-known software expert and entrepreneur, Herb Rotiblat, who has a PhD in psychology, advocates for the use of a similar elusion based recall calculation that uses only the point projection of the total False Negatives. He has popularized a name for this method: eRecall, and uses it with his company’s software.
I here offer a more accurate alternative that avoids the statistical fallacies of point projections. Rotiblat’s eRecall, and other ratio calculations like it, ignore the interval high and low range range inherent in all sampling. My version includes interval range, and for this reason an “i” is added to the name: ei-Recall.
ei-Recall is more accurate than eRecall, especially when working with low prevalence datasets, and, unlike eRecall, is not misleading because it shows the total range of recall. It is also more accurate because it uses the exact count of the documents verified as relevant at the end of the project, and does not estimate the True Positives value. I offer ei-Recall to the e-discovery community as a statistically valid alternative, and urge its speedy adoption.
To be continued ….
A few months ago I made a comment that predicted a showdown between opposing sides methodology for technology assisted review. Given that you now propose a superior method for culling down a collection to a responsive document set, would you oppose the other side’s use of eRecall? In essence, if you use ei-Recall and the other side uses eRecall you may be giving the other side an advantage either by pointing them directly to the relevant documents or giving them a larger quantity of relevant documents.
I like your methodology but it’s going to take quite some time to gain traction. I predict many lawyers and vendors will push something like eRecall for years to come because it will be considered “good enough”. Until more attorneys are willing to fight for more accurate discovery I’m not holding my breath.
There is a fundamental and very important difference between achieving Recall, and measuring Recall.
Second corollary point to remember, errors in finding important documents, recall achievement errors, can have significant adverse consequences. That drives an attorney’s work, plus the desire to do the best job possible to find out what really happened. Good lawyers understand that cases are won or lost primarily by the facts. The law is also important, but the facts drive the law in our common law system of justice. That is why our system is so strong. eDiscovery and big document review are not ends in themselves. They are just one of several means to the end of the discovery of admissible evidence of what really happened, iw – the truth. Fortunately truth matters in our system of justice, so thus too must recall as an achievement.
[…] read Part One of this article before reading this […]
[…] read Part One and Part Two of this article before reading this third and final […]
[…] Ralph Losey has recently proposed another method for estimating recall and declared it to be the new Gold Standard for measuring […]