This is the second part of a two-part article. Part One of Predictive Coding 3.0 described the errors in Predictive Coding 1.0 and 2.0, errors that are corrected by 3.0. The primary error addressed was the fallacy of the secret control set. The control set is very much accepted dogma among most e-discovery vendors and their hired experts. Still, after Part One came out, a few well-known experts spoke publicly in support of my anti-vendor-establishment critique. Many others have written to me privately to say they agree that control sets are b.s., that they have never used them, but few want to wade into the controversy. Never stopped me, especially when the attainment of just legal processes is concerned. Still, criticisms are easy. The articulation of positive replacements is the real challenge, and that is what this Part Two addresses.
____________
 This concluding segment describes the Predictive Coding 3.0 methodology in terms of an eight-step work flow. Steps four, five and six iterate until the active machine training reaches satisfactory levels, and thereafter final quality control and productions are done. Although presented as sequential steps for pedantic purposes, Predictive Coding 3.0 is highly adaptive to circumstances and does not necessarily follow a rigid linear order. For instance, some of the quality control procedures are used throughout the search and review, and rolling productions can begin at any time. Also, the truth is, the work flow is far easier to do, then it is to put in words. I have only rarely been the smartest guy in the room (and they were usually small rooms in rural Florida where I live and went to school) and so, if I can do all of this, then you can too. It is easier than it looks. It just takes some practice and experience. A good guide is also very helpful at first.
This concluding segment describes the Predictive Coding 3.0 methodology in terms of an eight-step work flow. Steps four, five and six iterate until the active machine training reaches satisfactory levels, and thereafter final quality control and productions are done. Although presented as sequential steps for pedantic purposes, Predictive Coding 3.0 is highly adaptive to circumstances and does not necessarily follow a rigid linear order. For instance, some of the quality control procedures are used throughout the search and review, and rolling productions can begin at any time. Also, the truth is, the work flow is far easier to do, then it is to put in words. I have only rarely been the smartest guy in the room (and they were usually small rooms in rural Florida where I live and went to school) and so, if I can do all of this, then you can too. It is easier than it looks. It just takes some practice and experience. A good guide is also very helpful at first.
______________
Eight-Step Work Flow of Predictive Coding 3.0

The eight-step chart provides a model of the Predictive Coding 3.0 methodology. The circular flows depict the iterative steps specific to the predictive coding features. (You may download and freely distribute this chart without further permission, so long as you do not change it.) For background on how to plan for a complex predictive coding document review project, see Form Plan of a Predictive Coding Project. The plan consists of detailed Outline for the project. To understand the 3.0 method, you also need to understand how it is fits into an overall Dual-Filter Culling process. See License to Cull The Two-Filter Document Culling Method (2015).
The overall process is not nearly as complicated as version 1.0 and 2.0, as Grossman and Cormack criticize in their patent claim. See end of Part One of Predictive Coding 3.0 where this is discussed. I have found that it can be taught to any experienced lawyer in a second-chair type of hands-on training. Mere intellectual descriptions, as I am doing here, and have done before in the over fifty or so articles on the subject, can serve as a good preparation for effective apprenticeship training. The following is a full description of the work flow. It should look very familiar to prior readers of my articles on predictive coding. It is consistent with these prior articles, but has several important refinements and improvements that have emerged from my ongoing research and legal practice experience.
Step One: ESI Discovery Communications
 The process starts with ESI Discovery Communications, not only with opposing counsel or other requesting parties, but also with the client and within the e-discovery team assigned to the case. Analysis of the scope of the discovery, and clear communications on relevance and other review procedures, are critical to all successful project management. The ESI Discovery Communications should be facilitated by the lead e-Discovery specialist attorney assigned to the case. But they must include the active participation by the whole team, including all trial lawyers not otherwise very involved in the ESI review. These communications are facilitated by a master plan, the details of which are refined in these initial communications. See eg. Form Plan of a Predictive Coding Project. Since nobody seems to have Spock’s Vulcan mind-meld abilities, this first step can sometimes be difficult, especially if there are many new members to the group. Still, a common understanding of relevance, the target searched, is critical to the successful outcome of the search. This includes the shared wisdom that this understanding will evolve and grow as discussed in Part One of this essay.
The process starts with ESI Discovery Communications, not only with opposing counsel or other requesting parties, but also with the client and within the e-discovery team assigned to the case. Analysis of the scope of the discovery, and clear communications on relevance and other review procedures, are critical to all successful project management. The ESI Discovery Communications should be facilitated by the lead e-Discovery specialist attorney assigned to the case. But they must include the active participation by the whole team, including all trial lawyers not otherwise very involved in the ESI review. These communications are facilitated by a master plan, the details of which are refined in these initial communications. See eg. Form Plan of a Predictive Coding Project. Since nobody seems to have Spock’s Vulcan mind-meld abilities, this first step can sometimes be difficult, especially if there are many new members to the group. Still, a common understanding of relevance, the target searched, is critical to the successful outcome of the search. This includes the shared wisdom that this understanding will evolve and grow as discussed in Part One of this essay.
You begin with analysis and discussions with your client, your internal team, and then with opposing counsel, as to what it is you are looking for and the requesting party is looking for. The point is to clarify the information sought, the target. You cannot just stumble around and hope you will know it when you find it (and yet this happens all too often in legal search). You must first know what you are looking for. The target of most searches is the information relevant to disputed issues of fact in a case or investigation. But what exactly does that mean? If you encounter unresolvable disputes with opposing counsel on the scope of relevance, which can happen during any stage of the review despite your best efforts up-front, you may have to include the Judge in these discussions and seek a ruling.
 This dialogue approach is based on a Cooperative approach to discovery that was popularized by the late, great Richard Braman of the Sedona Conference. Cooperation is not only a best practice, but is, to a certain extent at least, a minimum standard required by rules of professional ethics and civil procedure. The primary goal of these dialogues for Predictive Coding purposes is to obtain a common understanding of the e-discovery requests, and reach agreement on the scope of relevancy and production. Additional conferences on other e-discovery issues are also key to attaining the now strongly rule endorsed doctrine of proportionality.
This dialogue approach is based on a Cooperative approach to discovery that was popularized by the late, great Richard Braman of the Sedona Conference. Cooperation is not only a best practice, but is, to a certain extent at least, a minimum standard required by rules of professional ethics and civil procedure. The primary goal of these dialogues for Predictive Coding purposes is to obtain a common understanding of the e-discovery requests, and reach agreement on the scope of relevancy and production. Additional conferences on other e-discovery issues are also key to attaining the now strongly rule endorsed doctrine of proportionality.
The dialogues in this first step may, in some cases, require disclosure of the actual search techniques used, which is traditionally protected by work product. The disclosures may also sometimes include limited disclosure of some of the training documents used, both relevant and irrelevant. Nothing in the rules requires disclosure of irrelevant ESI, but if adequate privacy protections are provided, it may be in the best interests of all parties to do so. Such discretionary disclosures may be advantageous as risk mitigation and efficiency tactics. If an agreement on search protocol is reached by the parties, or imposed by the court, the parties are better protected from the risk of expensive motion practice and repetitions of discovery search and production. Agreement on search protocols can also be used to implement bottom line driven proportional review practices. See Eg. the first case approving predictive coding search protocols by Judge Andrew Peck: Da Silva Moore v. Publicis Groupe, 2012 WL 607412 (S.D.N.Y. Feb. 24, 2012) (approved and adopted in Da Silva Moore v. Publicis Groupe, 2012 WL 1446534, at *2 (S.D.N.Y. Apr. 26, 2012)) and the many thereafter that followed Da Silva.
 Also see Judge Andrew Peck’s more recent ruling on predictive coding, especially concerning disclosures: Rio Tinto v. Vale, 2015 WL 872294 (March 2, 2015, SDNY). Here Judge Peck wisely modifies somewhat his original views stated in Da Silva on the issue of disclosure. He no longer thinks that parties should necessarily disclose training documents, and may instead:
Also see Judge Andrew Peck’s more recent ruling on predictive coding, especially concerning disclosures: Rio Tinto v. Vale, 2015 WL 872294 (March 2, 2015, SDNY). Here Judge Peck wisely modifies somewhat his original views stated in Da Silva on the issue of disclosure. He no longer thinks that parties should necessarily disclose training documents, and may instead:
… insure that training and review was done appropriately by other means, such as statistical estimation of recall at the conclusion of the review as well as by whether there are gaps in the production, and quality control review of samples from the documents categorized as non-responsive. See generally Grossman & Cormack, Comments, supra, 7 Fed. Cts. L.Rev. at 301-12.
The Court, however, need not rule on the need for seed set transparency in this case, because the parties agreed to a protocol that discloses all non-privileged documents in the control sets. (Attached Protocol, ¶¶ 4(b)-(c).) One point must be stressed — it is inappropriate to hold TAR to a higher standard than keywords or manual review. Doing so discourages parties from using TAR for fear of spending more in motion practice than the savings from using TAR for review.
Id. at *3. Also see Rio Tinto v. Vale, Stipulation and Order Re: Revised Validation and Audit Protocols for the use of Predictive Coding in Discovery, 14 Civ. 3042 (RMB) (AJP), (order dated 9/2/15 by Maura Grossman, Special Master, and adopted and ordered by Judge Peck on 9/8/15).
Judge Peck here follows the current prevailing view on disclosure that I also endorse, a view entirely in accord with Predictive Coding 3.0. Note that the review of quality control samples is specified in Step Seven, ZEN Quality Assurance Tests, of the 3.0 methodology. The clear trend today is away from full disclosure, especially for irrelevant documents. Counsel is advised to offer translucency, not transparency, and to run quality control tests of the efficacy of their work. The cooperative approach to discovery may sometimes require partial disclosure of relevant documents used for training, but only partial or otherwise limited disclosure of irrelevant documents used in training. Still, the polestar remains cooperation, a goal totally consistent with the protection of client rights and interests. Mancia v. Mayflower Begins a Pilgrimage to the New World of Cooperation, 10 Sedona Conf. J. 377 (2009 Supp.).
Step Two: Multimodal Search Review
 In this step all types of search methods are used to try to find as many relevant documents as possible for the training rounds. In version 3.0 the samples found by the multimodal search methods in Step Two are selected by human judgment, not by random samples. The selections are made with the help of various software search features, including parametric Boolean keyword searches, similarity searches, and concept searches, and even strategic linear reviews of select custodians and date ranges. Documents outside of the dataset such a subpoenas or complaints may be included for training purposes too, even synthetic documents may be used as ideal exemplars.
In this step all types of search methods are used to try to find as many relevant documents as possible for the training rounds. In version 3.0 the samples found by the multimodal search methods in Step Two are selected by human judgment, not by random samples. The selections are made with the help of various software search features, including parametric Boolean keyword searches, similarity searches, and concept searches, and even strategic linear reviews of select custodians and date ranges. Documents outside of the dataset such a subpoenas or complaints may be included for training purposes too, even synthetic documents may be used as ideal exemplars.
All type of searches are used in Step Two except for Predictive coding based searches. They only reason they are not used here in Step Two is because you have not yet started predictive coding training. Step two is the search for the initial training set. It can be a long process, or a very short one. The same multimodal search process is carried out in Step-6, Hybrid Active Training, but now predictive coding is also used. So in that sense Step Six is where full multimodal search comes into play, including interaction with the AI you are training (that is the Hybrid part).
Although we speak of searching for relevant documents in Steps Two and Six, it is important to understand that many irrelevant documents are also incidentally found and coded in that process. Active machine learning does not work by training on relevant documents alone. It must also include examples of irrelevant documents. For that reason we sometimes actively search in Steps Two and Six for certain kinds of irrelevant documents to use in training. One of my current research experiments with Kroll Ontrack is to determine the best ratios between relevant and irrelevant documents for effective document ranking. See TREC reports at Mr. EDR as updated from time to time. This is one area where experience, art and skill now come into play, but we are working on standardizing that.
The multimodal search review in Steps Two and Six is carried out under the very general, second level supervision of the Subject Matter Experts on the case. They make final decisions where there is doubt concerning the relevance of a document or document type. The SME role is typically performed by a team, including the partner in charge of the case – the senior SME – and senior associates, and e-Discovery specialist attorney(s) assigned to the case. It is, or should be, a team effort, at least in most large projects.
The old-fashioned Predictive Coding 1.0 and 2.0 notions that a senior partner must work alone as the sole SME, and that he or she has to toil for days reviewing thousands of documents, including random junk files in a supposed control set, is not part of Predictive Coding 3.0. With no control set there is no need for such an inefficient process. Under my system a well-managed project has no SME time-demand problem. When I do a project, acting as the e-Discovery specialist attorney for the case, I listen carefully to the trial lawyer SME as he or she explains the case. By extensive Q&A the members of the team understand what is relevant. We learn from the SME. It is not exactly a Vulcan mind-meld, but it can work pretty well with a cohesive team. Most trial lawyers love to teach and opine on relevance and their theory of the case.
 Although a good SME team communicates and plans well, they also understand, typically from years of experience, that the intended relevance scope is like a battle plan before the battle: No battle plan ever survives contact with the enemy. So too no relevance scope plan never survives contact with the corpus of data. The understanding of relevance will evolve as the documents are studied, the evidence is assessed, and understanding of what really happened matures. If not, someone is not paying attention. In litigation that is usually a recipe for defeat.
Although a good SME team communicates and plans well, they also understand, typically from years of experience, that the intended relevance scope is like a battle plan before the battle: No battle plan ever survives contact with the enemy. So too no relevance scope plan never survives contact with the corpus of data. The understanding of relevance will evolve as the documents are studied, the evidence is assessed, and understanding of what really happened matures. If not, someone is not paying attention. In litigation that is usually a recipe for defeat.
The SME team trains and supervises the document review specialists, aka, contract review attorneys, who usually then do a large part of the manual reviews (Step-Five), and few if any searches. Working with review attorneys is a constant iterative process where communication is critical. Although contract reviewers can be used for efficiency and money-saving purposes, instead of an army-of-one approach that I have also used, I typically use only a few reviewers, say from one to three. With good methods, including culling methods, and good software, it is rarely necessary to have more than that. With the help of strong AI, say that included in Mr. EDR, no more attorneys than that are needed to classify a million or so documents for relevance. More reviewers than that may well be needed for complex redaction projects and other production issues, but not for a well-designed relevance search.
When reviewers are used in relevance culling, it is very important for all members of the SME team to have direct and substantial contact with the actual documents, not just the reviewers. For instance, everyone involved in the project should see all hot documents found in any step of the process. It is especially important for the SME trial lawyer at the top of the expert pyramid to see them, but that is rarely more than a few hundred documents, often just a few dozen. Otherwise, the top SME need only see the novel and grey area documents that are encountered, where it is unclear on which side of the relevance line they should fall in accord with the last instructions. Again, the burden on the senior, and often technologically challenged senior SME attorneys, is fairly light under these Version 3.0 procedures.
 The hands-on involvement of the entire SME team is especially needed in the second step, Multimodal search, and its echo Step Six, but is otherwise limited. The SME involvement up-front is needed to ensure that proper expertise is provided on relevance and the expected story to be told at trial. In some projects, at least one contract lawyer is brought in at Step Two to assist the SME team, and then later help in training of additional reviewers when they are included in Step Five. The e-Discovery specialist with expertise and experience with search, the Experienced Searcher, along with an expert on the software being used, the Power-User, should be involved in all stages of the project. Often these two roles (Power User and Experienced Searcher) are performed by one search expert, but rarely is that person also the sole SME of the legal issues. (I performed all three roles in the EDI Oracle experiment, but that was a rare exception.) In most real-world projects a team approach to the SME function is used. Still, the Experienced Searcher should always be a part if that SME team, if for no other reason than to ensure that the full communications outlined in Step One are maintained throughout the project.
The hands-on involvement of the entire SME team is especially needed in the second step, Multimodal search, and its echo Step Six, but is otherwise limited. The SME involvement up-front is needed to ensure that proper expertise is provided on relevance and the expected story to be told at trial. In some projects, at least one contract lawyer is brought in at Step Two to assist the SME team, and then later help in training of additional reviewers when they are included in Step Five. The e-Discovery specialist with expertise and experience with search, the Experienced Searcher, along with an expert on the software being used, the Power-User, should be involved in all stages of the project. Often these two roles (Power User and Experienced Searcher) are performed by one search expert, but rarely is that person also the sole SME of the legal issues. (I performed all three roles in the EDI Oracle experiment, but that was a rare exception.) In most real-world projects a team approach to the SME function is used. Still, the Experienced Searcher should always be a part if that SME team, if for no other reason than to ensure that the full communications outlined in Step One are maintained throughout the project.
The SME team relies on a primary SME, who is typically the trial lawyer in charge of the whole case, including all arguments of relevance to the judge and opposing counsel, at the start of the review. Thereafter, the head SME is only consulted on an as-needed basis to answer questions and make specific decisions on the grey area documents, again, typically in the echo Step Six, Hybrid Active Training, and Step Five, Document Review, as questions are raised by reviewers. There are always uncertain documents that need elevation to confirm relevance, but as the review progresses, their number usually decreases, and so the time and attention of the senior SME decreases accordingly.
The first round of machine training is also sometimes called the initial Seed Set Build, but under 3.0 there is nothing special about it. The following training rounds are identified by number (assuming you even keep track of them at all), such as the second round of training, the third, etc. The only thing special about the first round of training is that it cannot include rank-based document searches because no predictive coding ranking has yet occurred. The ranking of documents according to probable relevance is only established by the machine training. So, of course, it cannot be used before the first training begins. It is instead used in Step Six Hybrid Active Training.
 Personally, I like to keep track of and control when the training happens, as opposed to having training running continuously in the background. That is where art and experience again come it. It is also where the man-machine hybrid aspects of my search methods come in. I like to see the impact on ranking of particular training documents. I like to see how it impacts the learning of Mr. EDR. If it is always on, you cannot really see it on a granular, document by document level. The conscious knowledge of training rounds is not a mandatory aspect of Predictive Coding 3.0, but does help me to maintain a close hybrid relationship with the AI in the software, the ghost in the machine. This is one of the things, for me at least, that makes predictive coding so much fun. Working with Mr. EDR can be a real blast. I hope to explain this a little better later in this essay, and in other essays that I plan to write to in the future on the joys of predictive coding.
Personally, I like to keep track of and control when the training happens, as opposed to having training running continuously in the background. That is where art and experience again come it. It is also where the man-machine hybrid aspects of my search methods come in. I like to see the impact on ranking of particular training documents. I like to see how it impacts the learning of Mr. EDR. If it is always on, you cannot really see it on a granular, document by document level. The conscious knowledge of training rounds is not a mandatory aspect of Predictive Coding 3.0, but does help me to maintain a close hybrid relationship with the AI in the software, the ghost in the machine. This is one of the things, for me at least, that makes predictive coding so much fun. Working with Mr. EDR can be a real blast. I hope to explain this a little better later in this essay, and in other essays that I plan to write to in the future on the joys of predictive coding.
Step Three: Random Baseline
 The third step, which is not necessarily chronological, is essentially a computer function with statistical analysis. Here you create a random sample and analyze the results of expert review of the sample. Some review is thus involved in this step and you have to be very careful it is correctly done. This sample is taken for statistical purposes to establish a baseline for quality control purposes in Step Seven. Typically prevalence calculations are made at this point. Some software also uses this random sampling selection for purposes of a control set creation. As explained in Part One, Predictive Coding 3.0 does not use a control set, because it is so unreliable. In version 3.0 the sole purpose of the sample is to determine prevalence. Also see: In Legal Search Exact Recall Can Never Be Known. This can help guide your review and help you to decide when to stop training and move from the last iterative cycle of Step Six, into Step Seven – ZEN Quality Assurance Tests.
The third step, which is not necessarily chronological, is essentially a computer function with statistical analysis. Here you create a random sample and analyze the results of expert review of the sample. Some review is thus involved in this step and you have to be very careful it is correctly done. This sample is taken for statistical purposes to establish a baseline for quality control purposes in Step Seven. Typically prevalence calculations are made at this point. Some software also uses this random sampling selection for purposes of a control set creation. As explained in Part One, Predictive Coding 3.0 does not use a control set, because it is so unreliable. In version 3.0 the sole purpose of the sample is to determine prevalence. Also see: In Legal Search Exact Recall Can Never Be Known. This can help guide your review and help you to decide when to stop training and move from the last iterative cycle of Step Six, into Step Seven – ZEN Quality Assurance Tests.
In Step Three an SME is only needed to verify the classifications of any grey area documents found in the random sample. The random sample review should be done by one reviewer, typically your best contract reviewer. They should be instructed to code as Uncertain any documents that are not obviously relevant or irrelevant based on their instructions and Step One. All relevance codings should be double checked, as well as Uncertain documents. The senior SME is only consulted on an as-needed basis.
Document review in Step Three is limited to the sample documents. Aside from that, this step is a computer function and mathematical analysis. Pretty simple after you do it a few times. In complex cases a consulting statistician or scientist might be needed for a short consult, especially if you want to go beyond simple random sampling and do stratification, or some other complex variation. Most of the time this is not necessary and any competent version 3.0 vendor expert should be able to help you through it.
Step Four: AI Predictive Ranking
 This is the Auto Coding Run where the software’s predictive coding calculations are performed. The software I use, at least most of the time, is Kroll Ontrack’s Mr. EDR. In the Fourth Step the software does all of the work. It applies all of the training provided by the lawyers to sort the data corpus according to their instructions. In Step Four the human trainers can take a coffee break while Mr. EDR ranks all of the documents for us according to probable relevance, or whatever other category we request. For instance, I usually like to train and rank on Highly Relevant and Privilege at the same time as plain Relevant – Irrelevant.
This is the Auto Coding Run where the software’s predictive coding calculations are performed. The software I use, at least most of the time, is Kroll Ontrack’s Mr. EDR. In the Fourth Step the software does all of the work. It applies all of the training provided by the lawyers to sort the data corpus according to their instructions. In Step Four the human trainers can take a coffee break while Mr. EDR ranks all of the documents for us according to probable relevance, or whatever other category we request. For instance, I usually like to train and rank on Highly Relevant and Privilege at the same time as plain Relevant – Irrelevant.
The first time the training runs used to be called the seed set training. Step Four repeats, with steps Five and Six, in an iterative process, which is also known as Continuous Active learning (CAL). The first repetition of the training is known as the second round of training, the next, the third round, etc. These iterations continue until the training is complete within the proportional constraints of the case. At that point the attorney in charge of the search may declare the search complete and ready for the next quality assurance test in Step Seven.
It is important to understand that this diagram is just a linear two-dimensional representation of Predictive Coding 3.0 for teaching purposes. These step descriptions are also a simplified explanation, at least to some extent. Step Four can take place just a soon as a single document has been coded. You could have continuous, ongoing machine training, all the time, if you wanted. That is what CAL means. Although it would be inefficient, you could in theory have as many rounds of training as there are documents reviewed and classified. In my TREC experiments with Mr. EDR, we would sometimes have over fifty rounds of training, and still complete the Topic review in just over a day.
As mentioned, I personally do not like the machine to train at certain arbitrarily set time intervals, which is the way most continuous training CAL 2.0 software does it (i.e. – every fifteen minutes). I like to be in control and to tell the machine exactly when and if to train. I do that to improve communication and understanding of the software ranking. It helps me to have a better intuitive understanding of the machine processes. It allows me to see for myself how a particular document, or usually a particular group of documents, impacts the overall ranking. This is an important part of the Hybrid aspects of the Predictive Coding 3.0 Hybrid Multimodal Method.
 Step Four in the eight-step workflow is a purely algorithmic function. The ranking of a million documents may take as long as an hour, or even more, depending on the complexity, the number of documents, and software. Or it might just take a few minutes. This depends on the circumstances and tasks presented. From the human trainer perspective Step Four is just slight break to relax and keep the mind clear, while the computer does all of the work.
Step Four in the eight-step workflow is a purely algorithmic function. The ranking of a million documents may take as long as an hour, or even more, depending on the complexity, the number of documents, and software. Or it might just take a few minutes. This depends on the circumstances and tasks presented. From the human trainer perspective Step Four is just slight break to relax and keep the mind clear, while the computer does all of the work.
The predictive coding software in this step is analyzing all of the document categorizations made in Step Three for the initial run, the seed set. Thereafter in all subsequent training rounds, when Step Four repeats, the Machine, for me Mr. EDR, not only uses the input from Steps Two and Three, but also the new documents reviewed in Step Five, and found and selected for training coded in Step Six. Note that skilled searchers rarely use all documents coded as training documents, and that is where the art and experience of search come in again. The concern is to avoid over-training on any one document type and thus lowering recall and missing a key black-swan document. There is also the question of the ideal relevance/irrelevance ratio for effective document ranking.
All documents selected for training are included in this Step Four computer processing. The software studies the documents marked for training, and then scans all of the data uploaded onto the review platform (aka, the corpus). It then ranks all of the documents according to probable relevance (and, as mentioned according to other categories too, such as Highly Relevant and Privilege, and does all of these categories at the same time, but for simplicity purposes here we will just consider the relevance rankings). It essentially assigns a probable value of from 0.01% to 99.9% probable relevance to each document in the corpus. (Note, some software uses different ranking values, but this is essentially what it is doing.) A value of 99.9% represents the highest probability that the document matches the category trained, such as relevant, or highly relevant, or privileged. A value of 0.01% means no likelihood of matching. A probability ranking of 50% represents equal likelihood. The machine is uncertain as to the document classification.
The first few times this AI-Ranking step is run, the software predictions as to a document’s categorization are often wrong, sometimes wildly so. It depends on the kind of search and data involved, and the number of documents already classified and included for training. That is why spot-checking and further training are always needed for predictive coding to work properly.
Predictive Ranking at this point in AI development is necessarily an iterative process where human feedback is provided throughout the process. Analytic software in the future may be far less dependent on human involvement in the iterative process, but for now it is critical. That is where the next two Steps Five and Six come in, Document Review and Hybrid Active Training.
Step Five: Document Review
This is the step where most of the actual document review is done, where the documents are seen and classified by human reviewers. Note that I also sometimes refer to this step as Multimodal Search Review to emphasize that more than review takes place here. All types of search may also be conducted in this step and the next to find and batch out documents for human review and machine training. This step thus parallels Step Two except that documents are also found by ranking of probable relevance. This is not yet possible in Step Two because Step Four of of AI Predictive Ranking has not yet occurred.
In my experience, the human document review can take as little as one-second per document, assuming your software is good and fast, and it is an obvious document, to as long as a half-hour. The lengthy time to review a document is rare and only occurs where you have to fast-read a long document to be sure of its classification. Step five is the human time intensive part of Predictive Coding 3.0 and can take most of the time. Although, when I do a review, I usually spend more than half of the time in the other steps, sometimes considerable more. The TREC experiment was a good example of that, so was the Oracle EDI experiment.

Depending on the classification during Step Five Document Review, a document is either produced, if relevant and not-privileged, or not produced if irrelevant. If relevant and privileged, then it is logged, but not produced. If relevant, not privileged, but confidential for some reason, then it is either redacted and/or specially labeled before production. The special labeling performed is typically to prominently affix the word CONFIDENTIAL on the Tiff image production, or the phrase CONFIDENTIAL – ATTORNEYS EYES ONLY. The actual wording of the legends depends upon the parties confidentiality agreement or court order.
When redaction is required, the total time to review a document can sometimes go way up. The same goes for double and triple checking of privileged documents that sometime infect document collections in large numbers. In my TREC and Oracle experiments redactions and privilege double-checking were not required. The time-consuming redactions are often deferred to Step Eight – Productions. The equally as time-consuming privilege double-checking efforts can also be deferred to Step Seven – Quality Assurance, and again for a third-check in Step Eight.
When reviewing a document not already manually classified, the reviewer is usually presented with a document that the expert searcher running the project has determined is probably relevant. Typically this means it has higher than a 50% probable relevant ranking. The reviewer may, or may not, know the ranking. Whether you disclose that to a reviewer depends on a number of factors. Since I usually only use highly skilled reviewers, I trust them with disclosure. But sometimes you may not want to disclose the ranking.
During the review many documents predicted to be relevant, will not be. The reviewers will code them correctly, as they see them. If they are in doubt, they should consult the SME team. Furthermore, special quality controls in the form of second reviews on a random, or judgmental, selection process may be imposed on Man Machine disagreements. They often involve close questions and the ultimate results of the resolved conflicts are typically used in the next round of training. That is a decision made in Step Six. Prediction error corrections can be the focus of special searches in Step Six that look for such conflicts. Most quality version 3.0 software such as Mr. EDR have search functions built-in that are designed to locate all such conflicts. Reviewers then review and correct the computer errors by a variety of methods, or change their own prior decisions. This typically requires SME team involvement, but only very rarely senior level SMEs.
The predictive coding software learns from all of corrections to its predictive rankings. Steps 4 and 5 then repeat as shown in the diagram. This iterative process is considered a positive feedback loop that continues until the computer predictions are accurate enough to satisfy the proportional demands of the case.
Step Six: Hybrid Active Training
 In this step new documents are selected for review in the next iteration of Step Five. Moreover, in Step Six decisions are made as to what documents to include in training in the next round of Step Four, AI Predictive Ranking. Step Six is much like Step Two, Multimodal Search Review, except that now new types of document ranking search are possible. Since the documents are now all probability ranked in Step Four, you can use this ranking to select documents for the next round of document review (Step Five). For instance, the research of Cormack and Grossman, has shown that selection of the highest ranked documents can be a very effective method to continuously find and train relevant documents. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014, at pg. 9. Also see Latest Grossman and Cormack Study Proves Folly of Using Random Search for Machine Training – Parts One, Two, Three and Four. Another popular method, also tested and reported on by Grossman and Cormack, is to select mid-ranked documents, the ones the computer is uncertain about.
In this step new documents are selected for review in the next iteration of Step Five. Moreover, in Step Six decisions are made as to what documents to include in training in the next round of Step Four, AI Predictive Ranking. Step Six is much like Step Two, Multimodal Search Review, except that now new types of document ranking search are possible. Since the documents are now all probability ranked in Step Four, you can use this ranking to select documents for the next round of document review (Step Five). For instance, the research of Cormack and Grossman, has shown that selection of the highest ranked documents can be a very effective method to continuously find and train relevant documents. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014, at pg. 9. Also see Latest Grossman and Cormack Study Proves Folly of Using Random Search for Machine Training – Parts One, Two, Three and Four. Another popular method, also tested and reported on by Grossman and Cormack, is to select mid-ranked documents, the ones the computer is uncertain about.
The preferred active learning process in the iterative machine learning steps of Predictive Coding 3.0 is now four-fold. How you mix and match the four methods is a matter of personal preference. Here are my team’s current preferences.
1. High Ranked Documents. My team will almost always look to see what the highest unreviewed ranked documents are after AI Predictive Ranking, Step Four. We may review them on a document by document basis, or only by spot-checking them. In the later, more common spot-checking scenario, a quick review of a certain probable relevant range, say all documents ranked between 95% to 99.9% (Mr. EDR has no 100%), may show that they all seem obvious relevant. We may then bulk code all documents in that range as relevant without actually reviewing them. This is a very powerful and effective method with Mr. EDR, and other software (so I’ve heard), so long as care is used not to over-extend the probability range. In other situations, we may only select the 99%+ probable relevant set for checking and bulk coding without review. The safe range typically changes as the review evolves and your latest conception of relevance is successfully imprinted on the computer.
 In our cases the most enjoyable part of the review project comes when we see that Mr. EDR has understood our training and gone beyond us. He starts to see patterns that we cannot. He amazingly unearths documents that my team never thought to look for. The relevant documents he finds are sometimes dissimilar to any others found. They do not have the same key words, or even be the same known concepts. Still, Mr. EDR sees patterns in these documents that we do not. He finds the hidden gems of relevance, even outliers and black swans. That is when we think of Mr. EDR as going into superhero mode. At least that is the way my e-Discovery Team likes to talk about him.
In our cases the most enjoyable part of the review project comes when we see that Mr. EDR has understood our training and gone beyond us. He starts to see patterns that we cannot. He amazingly unearths documents that my team never thought to look for. The relevant documents he finds are sometimes dissimilar to any others found. They do not have the same key words, or even be the same known concepts. Still, Mr. EDR sees patterns in these documents that we do not. He finds the hidden gems of relevance, even outliers and black swans. That is when we think of Mr. EDR as going into superhero mode. At least that is the way my e-Discovery Team likes to talk about him.
By the end of most projects Mr. EDR attains a much higher intelligence and skill level than our own (at least on the task of finding the relevant evidence in the document collection). He is always lightening fast and inexhaustible, even untrained, but by the end of his education, he becomes a genius. Definitely smarter than any human as to this one task. Mr. EDR in that kind of superhero mode is what makes Predictive Coding 3.0 so much fun.
Watching AI with higher intelligence than your own, intelligence which you created by your training, is exciting. More than that, the AI you created empowers you to do things that would have been impossible before, absurd even. For instance, using Mr. EDR, my e-Discovery Team of three attorneys was able to do 30 review projects and classify 16,576,820 documents in 45 days. See TREC experiment summary at Mr. EDR. This is a very gratifying feeling of empowerment and augmentation of our own abilities. The high-AI experience comes though very clearly in the ranking of Mr. EDR near the end of the project, or really anytime before that, when he catches on to what you want and starts to find the hidden gems. I urge you all to give Predictive Coding 3.0 a try so you can have this same kind of advanced AI hybrid excitement.
 2. Mid-Ranked Uncertain Documents. We often choose to allow the machine, in our case Mr. EDR, to select the documents for review in the next iterated Step Five. We listen to what Mr. EDR tells us are the documents he wants to see. These are documents where the software classifier is uncertain of the correct classification. They are usually in the 40% to 60% probable relevant range. Human guidance on these documents as to their relevance helps the machine to learn by adding diversity to the documents presented for review. This in turn also helps to locate outliers of a type the initial judgmental searches in Step Two and Five may have missed.
2. Mid-Ranked Uncertain Documents. We often choose to allow the machine, in our case Mr. EDR, to select the documents for review in the next iterated Step Five. We listen to what Mr. EDR tells us are the documents he wants to see. These are documents where the software classifier is uncertain of the correct classification. They are usually in the 40% to 60% probable relevant range. Human guidance on these documents as to their relevance helps the machine to learn by adding diversity to the documents presented for review. This in turn also helps to locate outliers of a type the initial judgmental searches in Step Two and Five may have missed.
3. Random. We may also select some documents at random, either by proper computer random sampling or, more often, by informal random selection, including spot-checking. This again helps maximize recall and premature focus on the relevant documents initially retrieved. Random samples taken in Steps Three and Seven are typically also all included for training, and, of course, are always very carefully reviewed. The use of random selection for training purposes alone is minimized in Predictive Coding 3.0.
4. Multimodal Human Search. Most of the time when not following the machine’s high ranked selection we are using whatever search method we can to try to find relevant documents in Step Six. It is a multimodal search process, except this time we can also use a variety of document ranking based searches. As mentioned, the ranked searches are not available in Step Two because the active machine learning had not already begun. The searches may include some linear review of selected custodians or dates, parametric Boolean keyword searches, similarity searches of all kinds, concept searches, as well as several unique predictive coding probability searches. We call that a multimodal approach. Again, you need not limit these searches to ESI in the original dataset, but can also use outside documents such a subpoenas or complaints; even synthetic documents may be used as ideal exemplars.
Step Seven: ZEN Quality Assurance Tests
ZEN here stands for Zero Error Numerics. Predictive Coding 3.0 requires quality control activities in all steps, but the efforts peak in this Step Seven. For more on the ZEN approach to quality control in document review see ZeroErrorNumerics.com. In Step Seven a random sample is taken to try to evaluate the recall range attained in the project. The method currently favored is described in detail in Introducing “ei-Recall” – A New Gold Standard for Recall Calculations in Legal Search – Part One, Part Two and Part Three. Also see: In Legal Search Exact Recall Can Never Be Known.
In Step Seven a random sample is taken to try to evaluate the recall range attained in the project. The method currently favored is described in detail in Introducing “ei-Recall” – A New Gold Standard for Recall Calculations in Legal Search – Part One, Part Two and Part Three. Also see: In Legal Search Exact Recall Can Never Be Known.

 The ei-Recall test is based on a random sample of all documents to be excluded from the Final Review for possible production. Unlike the ill-fated control set of Predictive Coding 1.0 methodologies, the sample here is taken at the end of the project. At that time the final relevance conceptions have evolved to their final form and therefore much more accurate projections of recall can be made from the sample. The documents sampled can be based on documents excluded by category prediction (i.e. probable irrelevant) and/or by probable ranking of documents with proportionate cut-offs. The focus is on a search for any false negatives (i.e., relevant documents incorrectly predicted to be irrelevant) that are Highly Relevant or otherwise of significance.
The ei-Recall test is based on a random sample of all documents to be excluded from the Final Review for possible production. Unlike the ill-fated control set of Predictive Coding 1.0 methodologies, the sample here is taken at the end of the project. At that time the final relevance conceptions have evolved to their final form and therefore much more accurate projections of recall can be made from the sample. The documents sampled can be based on documents excluded by category prediction (i.e. probable irrelevant) and/or by probable ranking of documents with proportionate cut-offs. The focus is on a search for any false negatives (i.e., relevant documents incorrectly predicted to be irrelevant) that are Highly Relevant or otherwise of significance.
Total 100% recall of all relevant documents is said by the professors to be scientifically impossible (unless you produce all documents, 0% precision), a myth that I predict will soon be shattered. In any event, be it either impossible or very rare, total recall of all relevant document is legally unnecessary. The legal requirement is reasonable, proportional efforts to find the ESI that is important to resolve the key disputed issues of fact in the case. The goal is to avoid all false negatives of Highly Relevant documents. If this error is encountered, one or more additional iterations of Steps 4, 5 and 6 are required.
In Step Seven you also make and test the decision to stop the training (the repetition of Steps Four, Five and Six). This decision is evaluated by the random sample, but determined by a complex variety of factors that can be case specific. Typically it is determined by when the software has attained a highly stratified distribution of documents. See License to Kull: Two-Filter Document Culling and Visualizing Data in a Predictive Coding Project – Part One, Part Two and Part Three, and Introducing a New Website, a New Legal Service, and a New Way of Life / Work; Plus a Postscript on Software Visualization.
When the stratification has stabilized you will see very few new documents found as predicted relevant that have not already been human reviewed and coded as relevant. You essentially run out of documents for Step Five review. Put another way, your Step Six no longer uncovers new relevant documents. This exhaustion marker may in many projects mean that the rate of newly found documents has slowed, but not stopped entirely. I have written about this quite a bit, primarily in Visualizing Data in a Predictive Coding Project –Part One, Part Two and Part Three. The distribution ranking of documents in a mature project that has likely found all relevant documents of interest will typically look something like the diagram below. We call this the upside down champagne glass with red relevant documents on top and irrelevant on the bottom.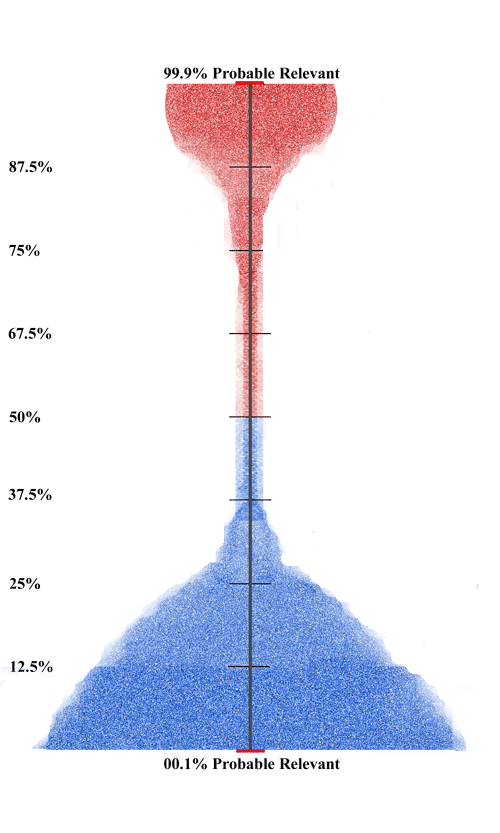
Also see Postscript on Software Visualization where even more dramatic stratifications are encountered and shown.
Another key determinant of when to stop is the cost of further review. Is it worth it to continue on with more iterations of Steps Four, Five and Six? See Predictive Coding and the Proportionality Doctrine: a Marriage Made in Big Data, 26 Regent U. Law Review 1 (2013-2014). Another criteria in the stop decision is whether you have found the information needed. If so, what is the purpose of continuing a search? Again, the law never requires finding all relevant, only reasonable efforts to find the relevant documents needed to decide the important fact issues in the case. This last point is often overlooked by inexperienced lawyers.
Step Eight: Phased Production
This last step is where the documents are actually produced. Technically, it has nothing to do with a predictive coding protocol, but for completeness sake, I wanted to include it in the work flow. This final step may also include document redaction, document labeling, and a host of privilege review issues, including double-checking, triple checking of privilege protocols. These are tedious functions where contract lawyers can be a big help. The actual identification of privileged documents from the relevant should have been part of the prior seven steps.
The production of electronic documents to the requesting party is done after a last quality control check of the media on which the production is made, typically CDs or DVDs. If you have to do FTP production to meet a tight deadline, I suggest also producing the same documents again the next day on a tangible media to keep a permanent record of the production. Always use a WORM medium for the production, meaning write once, and read many times. That means the data you produced cannot be altered. This might be helpful later for forensic purposes, along with hash, to confirm ESI authenticity and detect any changes.
The format of the production should be a non-issue. This is supposed to be discussed at the initial Rule 26(f) conference. Still, you might want to check again with the requesting party before you select the final production format and metadata fields. Remember, cooperation should be your benchmark and courtesy to opposing counsel on these small issues can go a long way. The existence of a clawback agreement and order, including a Rule 502(d) Order, should also be routinely verified before the production is made. Again, this should be a non-issue. The forms used should be worked out as part of the initial 26(f) meet and greet.
The final work included here is to prepare a privilege log. All good vendor review software should make this into a semi-automated process, and thus slightly less tedious. The logging is typically delayed until after production. Check with local rules on this and talk to the requesting party to let them know it is coming. Also, production is usually done in rolling stages as review is completed in order to buy more time and good will. As mentioned before, production of at least some documents can begin very early in the process and does not have to wait until the last step. Waiting to produce all of your documents at once is rarely a good idea, but is sometimes necessary.
Conclusion
After talking to many scientists in the information retrieval world I have found that they all agree it is a good idea to find relevant documents for training in any way you can. It makes no sense to limit yourself to any one search method. They agree that multimodal is the way to go, even if they do not use that language (after all, I did make up the term). They also all agree that effective text retrieval searches today should use some type of active machine learning (what we in the legal world calls predictive coding), and not just rely on the old search methods of keyword, similarity and concept. The multimodal use of all of the old methods to find training documents for the new method of active machine learning, is clearly the way to go. This hybrid approach exemplifies man and machine working together in an active partnership, a union where the machine augments human search abilities, not replaces them.
The Hybrid Multimodal Predictive Coding 3.0 approach described here is still not followed by most e-discovery vendors, including several prominent software vendors. They instead rely entirely on machine selected documents for training, or even worse, rely entirely on random selected documents to train the software. Others use all search methods except for predictive coding, primarily just keyword searches. They do so to try to keep it simple they say. It may be simple, but the power and speed given up for that simplicity is not worth it.
 The users of the old software and old-fashioned methods will never know the genuine thrill that most search lawyers using AI experience when watching really good AI in action. The good times roll when you see that the AI you have been training has absorbed your lessons. When you see the advanced intelligence that you helped create kick-in to complete the project for you. When you see your work finished in record time and with record results. It is sometimes amazing to see the AI find documents that you know you would never have found on your own. Predictive coding AI in superhero mode can be exciting to watch.
The users of the old software and old-fashioned methods will never know the genuine thrill that most search lawyers using AI experience when watching really good AI in action. The good times roll when you see that the AI you have been training has absorbed your lessons. When you see the advanced intelligence that you helped create kick-in to complete the project for you. When you see your work finished in record time and with record results. It is sometimes amazing to see the AI find documents that you know you would never have found on your own. Predictive coding AI in superhero mode can be exciting to watch.
My entire e-Discovery Team had a great time watching Mr. EDR do his thing in the thirty Recall Track TREC Topics in 2015. We would sometimes be lost, and not even understand what the search was for anymore. But Mr. EDR knew, he saw the patterns hidden to us mere mortals. In those cases we would just sit back and let him do the driving, occasionally cheering him on. That is when my Team decided to give Mr. EDR a cape and superhero status. He never let us down. It is a great feeling to see your own intelligence augmented and save you like that. It was truly a hybrid human-machine partnership at its best. I hope you get the opportunity soon to see this in action for yourself.
[…] in a systematic, repeatable, and verifiable manner. See: Predictive Coding 3.0, part one and part two and the over fifty or so articles on the subject that I have written since mid-2011. The hybrid […]
Great article! What do you believe is the amount of labor savings to be achieved using this approach over a traditional search method? Do you have any metrics on how much time is spent in the training steps? Thanks again for a wonderful article.
[…] Meanwhile, I’ve got an essay in the works regarding Ralph Losey’s magnum opus regarding Predictive Coding 3.0. (I’m reading all 15,000 words so you don’t have […]
[…] have been getting those kinds of positive feelings a lot lately using the new Predictive Coding 3.0 methodology and Kroll Ontrack’s latest eDiscovery.com Review software (“EDR”). So too have my […]