We added to the TAR Course again this weekend with a video introducing Class Fourteen on Step Seven, ZEN Quality Assurance Tests. ZEN stands for Zero Error Numerics with the double-entendre on purpose, but this video does not go into the math, concentration or reviewer focus. Ralph’s video instead provides an introduction to the main purpose of Step Seven from a work-flow perspective, to test and validate the decision to stop the Training Cycle steps, 4-5-6.
 The Training Cycle shown in the diagram continues until the expert in charge of the training decides to stop. This is a decision to complete the first pass document review. The stop decision is a legal, statistical decision requiring a holistic approach, including metrics, sampling and over-all project assessment. You decide to stop the review after weighing a multitude of considerations, including when the software has attained a highly stratified distribution of documents. See License to Kull: Two-Filter Document Culling and Visualizing Data in a Predictive Coding Project – Part One, Part Two and Part Three, and Introducing a New Website, a New Legal Service, and a New Way of Life / Work; Plus a Postscript on Software Visualization. Then you test your decision with a random sample in Step Seven.
The Training Cycle shown in the diagram continues until the expert in charge of the training decides to stop. This is a decision to complete the first pass document review. The stop decision is a legal, statistical decision requiring a holistic approach, including metrics, sampling and over-all project assessment. You decide to stop the review after weighing a multitude of considerations, including when the software has attained a highly stratified distribution of documents. See License to Kull: Two-Filter Document Culling and Visualizing Data in a Predictive Coding Project – Part One, Part Two and Part Three, and Introducing a New Website, a New Legal Service, and a New Way of Life / Work; Plus a Postscript on Software Visualization. Then you test your decision with a random sample in Step Seven.
____
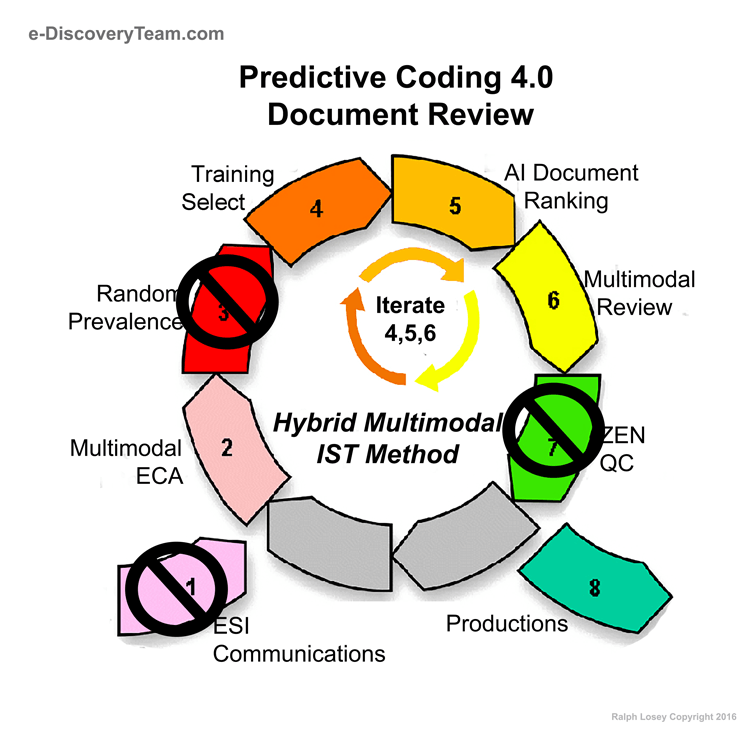
Team Methods in TREC Skipped Steps 1, 3 & 7
_____
____
By the way, I am using the phrase “accept on zero error” in the video in the general quality control sense, not in the specialized usage of the phrase contained in the The Grossman-Cormack Glossary of Technology Assisted Review. I forgot that phrase was in their glossary until recently. I have been using the term in the more general sense for several years. I do not advocate use of the accept on zero error method as defined in their glossary. I am not sure anyone does, but it is in their dictionary, so I felt this clarification was in order.
Stop Decision
 The stop decision is the most difficult decision in predictive coding. The decision must be made in all types of predictive coding methods, not just our Predictive Coding 4.0. Many of the scientists attending TREC 2015 were discussing this decision process. There was no agreement on criteria for the stop decision, except that all seemed to agree it is a complex issue that cannot be resolved by random sampling alone. The prevalence of most projects is too low for that.
The stop decision is the most difficult decision in predictive coding. The decision must be made in all types of predictive coding methods, not just our Predictive Coding 4.0. Many of the scientists attending TREC 2015 were discussing this decision process. There was no agreement on criteria for the stop decision, except that all seemed to agree it is a complex issue that cannot be resolved by random sampling alone. The prevalence of most projects is too low for that.
The e-Discovery Team grapples with the stop decision in every project, although in most it is a fairly simple decision because no more relevant documents have surfaced to the higher rankings. Still, in some projects it can be tricky. That is where experience is especially helpful. We do not want to quit too soon and miss important relevant information. On the other hand, we do not want to waste time look at uninteresting documents.
Still, in most projects we know it is about time to stop when the stratification of document ranking has stabilized. The training has stabilized when you see very few new documents predicted relevant that have not already been human reviewed and coded as relevant. You essentially run out of documents for step six review. Put another way, your step six no longer uncovers new relevant documents.
 This exhaustion marker may, in many projects, mean that the rate of newly found documents has slowed, but not stopped entirely. I have written about this quite a bit, primarily in Visualizing Data in a Predictive Coding Project –Part One, Part Two and Part Three. The distribution ranking of documents in a mature project, one that has likely found all relevant documents of interest, will typically look something like the diagram below. We call this the upside down champagne glass with red relevant documents on top and irrelevant on the bottom.
This exhaustion marker may, in many projects, mean that the rate of newly found documents has slowed, but not stopped entirely. I have written about this quite a bit, primarily in Visualizing Data in a Predictive Coding Project –Part One, Part Two and Part Three. The distribution ranking of documents in a mature project, one that has likely found all relevant documents of interest, will typically look something like the diagram below. We call this the upside down champagne glass with red relevant documents on top and irrelevant on the bottom.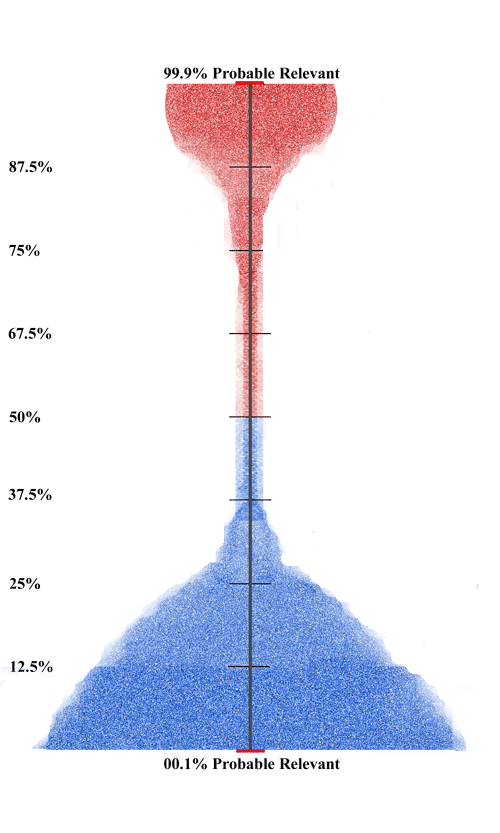 Also see Postscript on Software Visualization where even more dramatic stratification are encountered and shown.
Also see Postscript on Software Visualization where even more dramatic stratification are encountered and shown.
 Another key determinant of when to stop is the cost of further review. Is it worth it to continue on with more iterations of steps four, five and six? See Predictive Coding and the Proportionality Doctrine: a Marriage Made in Big Data, 26 Regent U. Law Review 1 (2013-2014) (note article was based on earlier version 2.0 of our methods where the training was not necessarily continuous). Another criteria in the stop decision is whether you have found the information needed. If so, what is the purpose of continuing a search? Again, the law never requires finding all relevant, only reasonable efforts to find the relevant documents needed to decide the important fact issues in the case. Rule 1 and 26(b)(1) must be considered.
Another key determinant of when to stop is the cost of further review. Is it worth it to continue on with more iterations of steps four, five and six? See Predictive Coding and the Proportionality Doctrine: a Marriage Made in Big Data, 26 Regent U. Law Review 1 (2013-2014) (note article was based on earlier version 2.0 of our methods where the training was not necessarily continuous). Another criteria in the stop decision is whether you have found the information needed. If so, what is the purpose of continuing a search? Again, the law never requires finding all relevant, only reasonable efforts to find the relevant documents needed to decide the important fact issues in the case. Rule 1 and 26(b)(1) must be considered.
The stop decision is state of the art in difficulty and creativity. We often provide custom solutions for testing the decision depending upon project contours and other unique circumstances. I wish Duke would have a conference on that, instead of one to reinvent old wheels. But as George Bernard Shaw said, those who can, do. You know the rest.
Conclusion
 We continue with our work improving our document review methods and improving the free TAR Course. We want to make information on best practices in this area as accessible as possible and as easy to understand as possible. We have figured out our processes over thousands of projects since the Da Silva Moore days (2011-2012). It has come out of legal practice, trial and error. We learn by doing, but we also teach this stuff, just not for a living. We also run scientific experiments in TREC and on our own, again, just not for a living. Our Predictive Coding 4.0 Hybrid Multimodal IST method has not come out of conferences and debates. It is a legal practice, not an academic study or exercise in group consensus.
We continue with our work improving our document review methods and improving the free TAR Course. We want to make information on best practices in this area as accessible as possible and as easy to understand as possible. We have figured out our processes over thousands of projects since the Da Silva Moore days (2011-2012). It has come out of legal practice, trial and error. We learn by doing, but we also teach this stuff, just not for a living. We also run scientific experiments in TREC and on our own, again, just not for a living. Our Predictive Coding 4.0 Hybrid Multimodal IST method has not come out of conferences and debates. It is a legal practice, not an academic study or exercise in group consensus.
Try it yourself and see. Just do not use the first version methods of predictive coding that we used back in Da Silva Moore. Another TAR Course Update and a Mea Culpa for the Negative Consequences of ‘Da SIlva Moore’. Use the latest version 4.0 methods.
 The old methods, versions 1.0 and 2.0, that most of the industry still follows, must be abandoned. Predictive Coding 1.o did not use continuous active training, it used Train Then Review (TTR). That invited needless disclosure debates and other poor practices. Version 1.0 also used control sets. In version 2.0 continuous active training (CAT) replaced TTR, but control sets are still used. In version 3.0 CAT is used, and Control Sets are abandoned. In our version 3.0 we replaced the secret control set basis of recall calculation with a prevalence based random sample guide in Step Three and an elusion based quality control sample in Step Seven. See: Predictive Coding 3.0 (October 2015).
The old methods, versions 1.0 and 2.0, that most of the industry still follows, must be abandoned. Predictive Coding 1.o did not use continuous active training, it used Train Then Review (TTR). That invited needless disclosure debates and other poor practices. Version 1.0 also used control sets. In version 2.0 continuous active training (CAT) replaced TTR, but control sets are still used. In version 3.0 CAT is used, and Control Sets are abandoned. In our version 3.0 we replaced the secret control set basis of recall calculation with a prevalence based random sample guide in Step Three and an elusion based quality control sample in Step Seven. See: Predictive Coding 3.0 (October 2015).
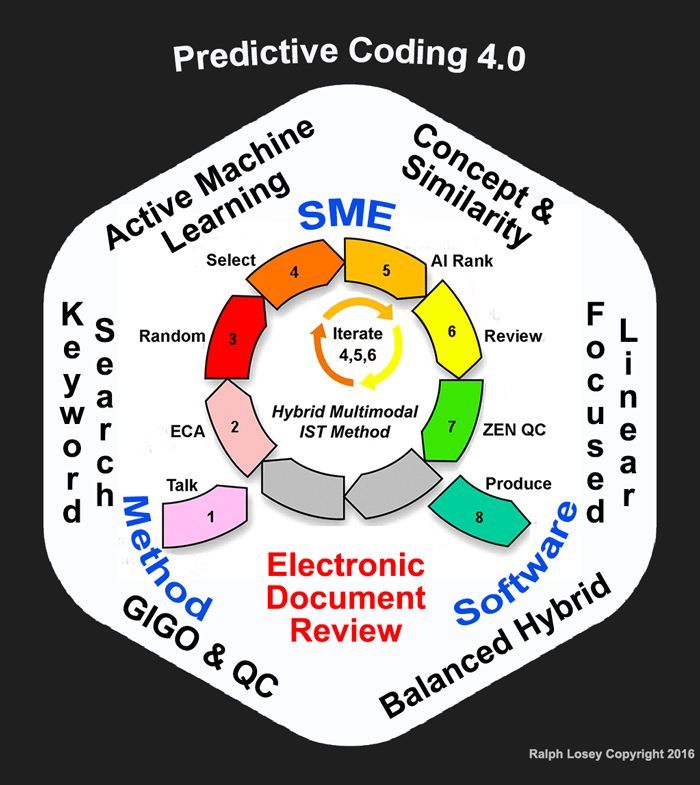
In version 4.0, our current version, we further refined the continuous training aspects of our method with the technique we call Intelligently Spaced Training, IST.
 Our new eight-step Predictive Coding 4.0 is easier to use than every before and is now battled tested in both legal and scientific arenas. Take the TAR Course, try using our new methods of document review, instead of the old Da Silva Moore methods. If you do, we think you will be as excited about predictive coding as we are. Why I Love Predictive Coding: Making document review fun with Mr. EDR and Predictive Coding.
Our new eight-step Predictive Coding 4.0 is easier to use than every before and is now battled tested in both legal and scientific arenas. Take the TAR Course, try using our new methods of document review, instead of the old Da Silva Moore methods. If you do, we think you will be as excited about predictive coding as we are. Why I Love Predictive Coding: Making document review fun with Mr. EDR and Predictive Coding.
Reblogged this on The eDiscovery Nerd.