 The only types of Technology Assisted Review (TAR) software that we endorse for the search of large ESI collections include active machine learning algorithms, which provide full featured predictive coding capacities. Active machine learning is a type of artificial intelligence (AI). When used in legal search these AI algorithms significantly improve the search, review, and classification of electronically stored information (ESI). For this reason I prefer to call predictive coding AI-enhanced review or AI-enhanced search. For more background on the science involved, see LegalSearchScience.com and our sixteen class TAR Training Course.
The only types of Technology Assisted Review (TAR) software that we endorse for the search of large ESI collections include active machine learning algorithms, which provide full featured predictive coding capacities. Active machine learning is a type of artificial intelligence (AI). When used in legal search these AI algorithms significantly improve the search, review, and classification of electronically stored information (ESI). For this reason I prefer to call predictive coding AI-enhanced review or AI-enhanced search. For more background on the science involved, see LegalSearchScience.com and our sixteen class TAR Training Course.
In TARs with AI-enhanced active machine learning, attorneys train a computer to find documents identified by the attorney as a target. The target is typically relevance to a particular lawsuit or legal issue, or some other legal classification, such as privilege. This kind of AI-enhanced review, along with general e-discovery training, are now my primary interests as a lawyer.
Personal Legal Search Background
 In 2006 I dropped my civil litigation practice and limited my work to e-discovery. That is also when I started this blog. At that time I could not even imagine specializing more than that. In 2006 I was interested in all aspects of electronic discovery, including computer assisted review. AI-enhanced software was still just a dream that I hoped would someday come true.
In 2006 I dropped my civil litigation practice and limited my work to e-discovery. That is also when I started this blog. At that time I could not even imagine specializing more than that. In 2006 I was interested in all aspects of electronic discovery, including computer assisted review. AI-enhanced software was still just a dream that I hoped would someday come true.
The use of software in legal practice has always been a compelling interest for me. I have been an avid user of computer software of all kinds since the late 1970s, both legal and entertainment. I even did some game software design and programming work in the early 1980s. My now-grown kids still remember the computer games I made for them.
I carefully followed the legal search and review software scene my whole career, but especially since 2006. It was not until 2011 that I began to be impressed by the new types of predictive coding software entering the market. After I got my hands on the new software, I began to do what had once been unimaginable. I started to limit my legal practice even further. I began to spend more and more of my time on predictive coding types of review work. Since 2012 my work as an e-discovery lawyer and researcher has focused almost exclusively on using predictive coding in large document production projects, and on e-discovery training, another passion of mine. In that year one of my cases produced a landmark decision by Judge Andrew Peck that first approved the use of predictive coding. Da Silva Moore v. Publicis Groupe, 2012 WL 607412 (SDNY Feb. 24, 2012) (approved and adopted in Da Silva Moore v. Publicis Groupe, 2012 WL 1446534, at *2 (SDNY Apr. 26, 2012)). There have been many cases thereafter that follow Da Silva Moore and encourage the use of predictive coding. See eg.: Rio Tinto v. Vale, 2015 WL 872294 (March 2, 2015, SDNY) with a case collection therein.
 Attorney Maura R. Grossman and I are among the first attorneys in the world to specialize in predictive coding as an e-discovery sub-niche. Maura is a colleague who is both a practicing attorney and an expert in the new field of Legal Search Science. We have frequently presented on CLE panels as a kind of technology evangelists for these new methods of legal review. Maura, and her partner, ProfessorGordon Cormack, who is an esteemed information scientist and professor, wrote the seminal scholarly paper on the subject, and an excellent glossary of terms used in TAR. Technology-Assisted Review in E-Discovery Can Be More Effective and More Efficient Than Exhaustive Manual Review, Richmond Journal of Law and Technology, Vol. XVII, Issue 3, Article 11 (2011); The Grossman-Cormack Glossary of Technology-Assisted Review, with Foreword by John M. Facciola, U.S. Magistrate Judge, 2013 Fed. Cts. L. Rev. 7 (January 2013); Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014.
Attorney Maura R. Grossman and I are among the first attorneys in the world to specialize in predictive coding as an e-discovery sub-niche. Maura is a colleague who is both a practicing attorney and an expert in the new field of Legal Search Science. We have frequently presented on CLE panels as a kind of technology evangelists for these new methods of legal review. Maura, and her partner, ProfessorGordon Cormack, who is an esteemed information scientist and professor, wrote the seminal scholarly paper on the subject, and an excellent glossary of terms used in TAR. Technology-Assisted Review in E-Discovery Can Be More Effective and More Efficient Than Exhaustive Manual Review, Richmond Journal of Law and Technology, Vol. XVII, Issue 3, Article 11 (2011); The Grossman-Cormack Glossary of Technology-Assisted Review, with Foreword by John M. Facciola, U.S. Magistrate Judge, 2013 Fed. Cts. L. Rev. 7 (January 2013); Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014.
I recommend your reading of all of their works. I also recommend your review of my over sixty articles on the subject, study of the LegalSearchScience.com website that I put together, and the many references and citations included at Legal Search Science, including the writings of other pioneers in the field, such as the founders of TREC Legal Track, Jason R. Baron, Doug Oard, and other key figures in the field, such as information scientist William Webber. Also see Baron and Grossman, The Sedona Conference® Best Practices Commentary on the Use of Search and Information Retrieval Methods in E-Discovery (2013).pdf (December 2013).
Advanced TARs Require Completely New Driving Methods
TAR is more than just new software. It entails a whole new legal method, a new approach to large document reviews. Below is the diagram of the latest Predictive Coding 4.0 workflow I use in a typical TAR project.
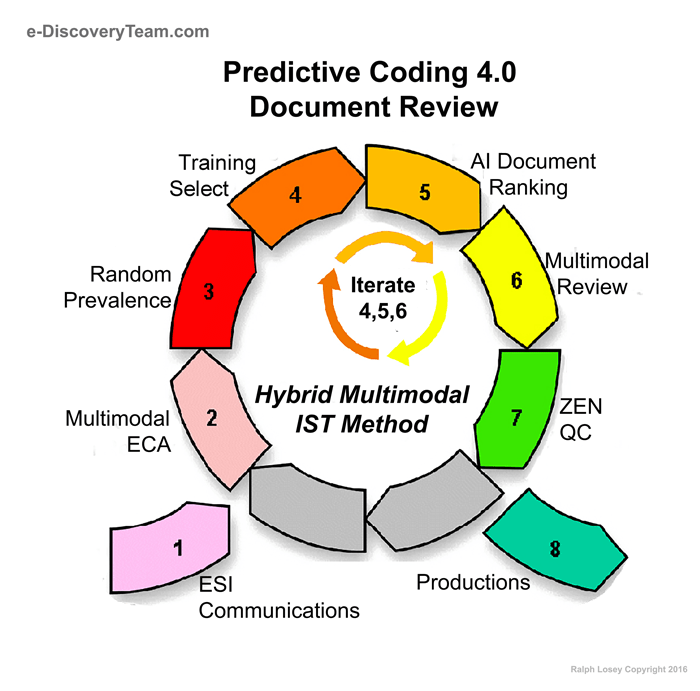
See: TAR Training Course. This sixteen class course teaches our latest insights and methods of Predictive Coding 4.0.
Predictive Coding using the latest 4.0 methods is the new tool for finding the ESI needles of relevant evidence. When used properly, good predictive coding software allows attorneys to find the information they need to defend or prosecute a case in the vast haystacks of ESI they must search, and to do so in an effective and affordable manner.
Professor Cormack and Maura Grossman have also performed experiments on predictive coding methodologies, which, among other things, tested the efficacy of random only based search. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014. They reached the same conclusions that I did, and showed that this random only – Borg approach – is far less effective than even the most simplistic judgmental methods. I reported on this study in full in a series of blogs in the Summer of 2014, Latest Grossman and Cormack Study Proves Folly of Using Random Search for Machine Training, see especially Part One of the series.
The CAL Variation
After study of the 2014 experiments by Professor Cormack and Maura Grossman reported at the SIGIR conference, I created a variation to the predictive coding work flow, which they call CAL, for Continuous Active Learning. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014, at pg. 9. Also see Latest Grossman and Cormack Study Proves Folly of Using Random Search for Machine Training – Parts One, Two, Three and Four. The part that intrigued me about there study was the use of continuous machine training as part of the entire review. This is explained in detail in Part Three of my lengthy blog series on the Cormack Grossman study.
The form of CAL that Cormack and Grossman tested used high probable relevant documents in all but the first training round. (In the first round, the so called seed set, they trained using documents found by keyword search.) This experiment showed that the method of review of the documents with the highest rankings works well, and should be given significant weight in any multimodal approach, especially when the goal is to quickly find as many relevant documents as possible. This is another take-away from this important experiment.
The “continuous” training aspects of the CAL approach means that you keep doing machine training throughout the review project and batch reviews accordingly. This could become a project management issue. But, if you can pull it off within proportionality and requesting party constraints, it just makes common sense to do so. You might as well get as much help from the machine as possible and keep getting its probability predictions for as long as you are still doing reviews and can make last minute batch assignments accordingly.
I have done several reviews in such a continuous training manner without really thinking about the fact that the machine input was continuous, including my first Enron experiment. Predictive Coding Narrative: Searching for Relevance in the Ashes of Enron. But the Cormack Grossman study on the continuous active learning approach caused me to rethink the my flow chart and create the Version 4.0 process shown above. See: TAR Training Courses (teaches Predictive Coding 4.0).
Hybrid Human Computer Information Retrieval

In further contradistinction to the Borg, or random only approaches, where the machine controls the learning process, I advocate a hybrid approach where Man and Machine work together. In my hybrid method the expert reviewer remains in control of the process, and their expertise is leveraged for greater accuracy and speed. The human intelligence of the SME is a key part of the search process. In the scholarly literature of information science this hybrid approach is known as Human–computer information retrieval (HCIR).
The classic text in the area of HCIR, which I endorse, is Information Seeking in Electronic Environments (Cambridge 1995) by Gary Marchionini, Professor and Dean of the School of Information and Library Sciences of U.N.C. at Chapel Hill. Professor Marchionini speaks of three types of expertise needed for a successful information seeker:
- Domain Expertise. This is equivalent to what we now call SME, subject matter expertise. It refers to a domain of knowledge. In the context of law the domain would refer to particular types of lawsuits or legal investigations, such as antitrust, patent, ERISA, discrimination, trade-secrets, breach of contract, Qui Tam, etc. The knowledge of the SME on the particular search goal is extrapolated by the software algorithms to guide the search. If the SME also has System Expertise, and Information Seeking Expertise, they can drive the process themselves. (That is what I did in the EDI Oracle competition. I did the whole project as an Army of One, and my results were unbeatable.) Otherwise, an SME will need expert helpers with such system and search expertise. These experts must also have legal knowledge because they must be capable of learning enough from the SME to recognize the relevant documents.
- System Expertise. This refers to expertise in the technology system used for the search. A system expert in predictive coding would have a deep and detailed knowledge of the software they are using, including the ability to customize the software and use all of its features. In computer circles a person with such skills is often called a power-user. Ideally a power-user would have expertise in several different software systems. They would also be an expert in a particular method of search.
- Information Seeking Expertise. This is a skill that is often overlooked in legal search. It refers to a general cognitive skill related to information seeking. It is based on both experience and innate talents. For instance, “capabilities such as superior memory and visual scanning abilities interact to support broader and more purposive examination of text.” Professor Marchionini goes on to say that: “One goal of human-computer interaction research is to apply computing power to amplify and augment these human abilities.” Some lawyers seem to have a gift for search, which they refine with experience, broaden with knowledge of different tools, and enhance with technologies. Others do not.
Id. at pgs.66-69, with the quotes from pg. 69.
All three of these skills are required for an attorney to attain expertise in legal search today, which is one reason I find this new area of legal practice requires a team effort.
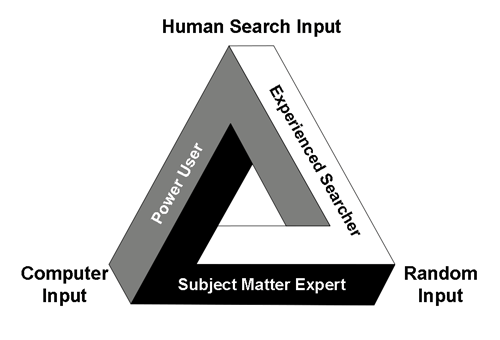
It is not enough to be an SME, or a power-user, or have a special knack for search. You have to be able to do it all, and usually the only way to do that is to work with a team that has all these skills, and good software too. With a team it is not really that difficult, but like anything requires initial training and then experience. Still, among the three skill-sets, studies have shown that, System Expertise, which in legal search primarily means mastery of the particular software used (Power User), is the least important. Id. at 67. The SMEs are more important, those who have mastered a domain of knowledge. In Professor Marchionini’s words:
Thus, experts in a domain have greater facility and experience related to information-seeking factors specific to the domain and are able to execute the subprocesses of information seeking with speed, confidence, and accuracy.
Id. That is one reason that the Grossman Cormack glossary builds in the role of SMEs as part of their base definition of computer assisted review:
A process for Prioritizing or Coding a Collection of electronic Documents using a computerized system that harnesses human judgments of one or more Subject Matter Expert(s) on a smaller set of Documents and then extrapolates those judgments to the remaining Document Collection.
Glossary at pg. 21 defining TAR.
According to Marchionini, Information Seeking Expertise, much like Subject Matter Expertise, is also more important than specific software mastery. Id. This may seem counterintuitive in the age of Google, where an illusion of simplicity is created by typing in words to find websites. But legal search of user-created data is a completely different type of search task than looking for information from popular websites. In the search for evidence in a litigation, or as part of a legal investigation, special expertise in information seeking is critical, including especially knowledge of multiple search techniques and methods. Again quoting Professor Marchionini:
Expert information seekers possess substantial knowledge related to the factors of information seeking, have developed distinct patterns of searching, and use a variety of strategies, tactics and moves.
Id. at 70.
In the field of law this kind of information seeking expertise includes the ability to understand and clarify what the information need is, in other words, to know what you are looking for, and articulate the need into specific search topics. This important step precedes the actual search, but is an integral part of the process. As one of the basic texts on information retrieval written by Gordon Cormack, et al, explains:
Before conducting a search, a user has an information need, which underlies and drives the search process. We sometimes refer to this information need as a topic …
Buttcher, Clarke & Cormack, Information Retrieval: Implementation and Evaluation of Search Engines (MIT Press, 2010) at pg. 5. The importance of pre-search refining of the information need is stressed in the first step of the above diagram of Predictive Coding 4.0 methods, ESI Discovery Communications. It seems very basic, but is often under appreciated, or overlooked entirely in the litigation context where information needs are often vague and ill-defined, lost in overly long requests for production and adversarial hostility.
Hybrid Multimodal Bottom Line Driven Review
My descriptive name for what Marchionini calls the variety of strategies, tactics and moves is Hybrid Multimodal. See eg. Bottom Line Driven Proportional Review (2013). I refer to it as a multimodal method because, although the predictive coding type of searches predominate (shown on the below diagram as AI-enhanced review – AI), I also use the other modes of search, including Unsupervised Learning Algorithms (explained in LegalSearchScience.com) (often called clustering or near-duplication searches), keyword search, and even some traditional linear review (although usually very limited). As described, I do not rely entirely on random documents, or computer selected documents for the AI-enhanced searches, but use a four-cylinder approach that includes human judgment sampling and AI document ranking. See: TAR Training Course. This sixteen class course teaches our latest insights and methods of Predictive Coding 4.0.
The various types of legal search methods used in a multimodal process are shown in this search pyramid. Most information scientists I have spoken to agree that it makes sense to use multiple methods in legal search and not just rely on any single method. UCLA Professor Marcia J. Bates first advocated for using multiple search methods back in 1989, which she called it berrypicking. Bates, Marcia J. The Design of Browsing and Berrypicking Techniques for the Online Search Interface, Online Review 13 (October 1989): 407-424. As Professor Bates explained in 2011 in Quora:
Most information scientists I have spoken to agree that it makes sense to use multiple methods in legal search and not just rely on any single method. UCLA Professor Marcia J. Bates first advocated for using multiple search methods back in 1989, which she called it berrypicking. Bates, Marcia J. The Design of Browsing and Berrypicking Techniques for the Online Search Interface, Online Review 13 (October 1989): 407-424. As Professor Bates explained in 2011 in Quora:
An important thing we learned early on is that successful searching requires what I called “berrypicking.” … Berrypicking involves 1) searching many different places/sources, 2) using different search techniques in different places, and 3) changing your search goal as you go along and learn things along the way. This may seem fairly obvious when stated this way, but, in fact, many searchers erroneously think they will find everything they want in just one place, and second, many information systems have been designed to permit only one kind of searching, and inhibit the searcher from using the more effective berrypicking technique.
This berrypicking approach, combined with HCIR, is what I have found from practical experience works best with legal search.
My Battles in Court Over Predictive Coding
In 2012 my case became the first in the country where the use of predictive coding was approved. See Judge Peck’s landmark decision Da Silva Moore v. Publicis, 2012 WL 607412 (S.D.N.Y. Feb. 24, 2012) (approved and adopted in Da Silva Moore v. Publicis Groupe, 2012 WL 1446534, at *2 (S.D.N.Y. Apr. 26, 2012)). In that case my methods of using Recommind’s Axcelerate software were approved. Later in 2012, in another first, an AAA arbitration approved our use of predictive coding in a large document production. In that case I used Kroll Ontrack’s Inview software over the vigorous objections of the plaintiff, which, after hearings, were all rejected. These and other decisions have helped pave the way for the use of predictive coding search methods in litigation.
Scientific Research
In addition to these activities in court I have focused on scientific research on legal search, especially machine learning. I have, for instance, become one of the primary outside reporters on the legal search experiments conducted by TREC Legal Track of the National Institute of Science and Technology. See eg. Analysis of the Official Report on the 2011 TREC Legal Track – Part One, Part Two and Part Three; Secrets of Search: Parts One, Two, and Three. Also see Jason Baron, DESI, Sedona and Barcelona. In 2015, and again in 2016, I was a participant in TREC total Recall Track. My team members were the top search experts at Kroll Ontrack whom have all trained and mastered Predictive Coding 4.0 methods. The e-Discovery Team participation in TREC is reported on at MrEDR.com, the name my team gave to the Kroll Ontrack software we used in these experiments.
After the TREC Legal Track closed down in 2011, and then reopened in 2015 with the Total Recall Track, and again in 2016, the only group participant scientific study to test the efficacy of various predictive coding software, and search methods, is the one sponsored by Oracle, the Electronic Discovery Institute and Stanford. This search of a 1,639,311 document database was conducted in early 2013, with the results reported in Monica Bay’s article, EDI-Oracle Study: Humans Are Still Essential in E-Discovery (LTN Nov., 2013). Here is the below chart published by LTN that summarizes the results.

Monica Bay summaries the findings of the research as follows:
Phase I of the study shows that older lawyers still have e-discovery chops and you don’t want to turn EDD over to robots.
 With respect to my dear friend Monica, I must disagree with her conclusion. The age of the lawyers is irrelevant. The best predictive coding trainers do not have to be old, they just have to be SMEs, power users of good software, and have good search skills. In fact, not all SMEs are old, although many may be. It is the expertise and skills that matter, not age per se. It is true as Monica reports that the lawyer, a team of one, who did better in this experiment than all of the other much larger participant groups, was chronologically old. But that fact is irrelevant. The skill set and small group size, namely one, is what made the difference. See: Less Is More: When it comes to predictive coding training, the “fewer reviewers the better” – Parts One, Two, and Three.
With respect to my dear friend Monica, I must disagree with her conclusion. The age of the lawyers is irrelevant. The best predictive coding trainers do not have to be old, they just have to be SMEs, power users of good software, and have good search skills. In fact, not all SMEs are old, although many may be. It is the expertise and skills that matter, not age per se. It is true as Monica reports that the lawyer, a team of one, who did better in this experiment than all of the other much larger participant groups, was chronologically old. But that fact is irrelevant. The skill set and small group size, namely one, is what made the difference. See: Less Is More: When it comes to predictive coding training, the “fewer reviewers the better” – Parts One, Two, and Three.
Moreover, although Monica is correct to say we do not want to”turn over” review to robots, this assertion misses the point. We certainly do want to turn over review to robot-human teams. We want our predictive coding software, our robots, to hook up with our experienced lawyers. We want our lawyers to enhance their own limited intelligence with artificial intelligence – the Hybrid approach. Robots are the future, but only if and as they work hand-in-hand with our top human trainers. Then they are unbeatable, as the EDI-Oracle study shows.
 For the time being the details of the EDI-Oracle scientific study are still closed, and even though Monica Bay was permitted to publicize the results, and make her own summary and conclusions, participants are prohibited from discussion and public disclosures. For this reason I can say no more on this study, and only assert without facts that Monica’s conclusions are in some respects incorrect, that age is not critical, that the hybrid multimodal method is what is important. I hope and expect that someday soon the gag order for participants will be lifted, the full findings of this most interesting scientific experiment will be released, and a free dialogue will commence. Truth only thrives in the open, and science concealed is merely occult. That is one of many reason why the more open TREC experiments in 2015 and 2016 are so important. See MrEDR.com.
For the time being the details of the EDI-Oracle scientific study are still closed, and even though Monica Bay was permitted to publicize the results, and make her own summary and conclusions, participants are prohibited from discussion and public disclosures. For this reason I can say no more on this study, and only assert without facts that Monica’s conclusions are in some respects incorrect, that age is not critical, that the hybrid multimodal method is what is important. I hope and expect that someday soon the gag order for participants will be lifted, the full findings of this most interesting scientific experiment will be released, and a free dialogue will commence. Truth only thrives in the open, and science concealed is merely occult. That is one of many reason why the more open TREC experiments in 2015 and 2016 are so important. See MrEDR.com.
Why Predictive Coding Is Important
I continue to focus on this sub-niche area of e-discovery as I am convinced that it is critical to advancement of the law in the 21st Century. Our own intelligence and search skills must be enhanced by the latest AI software. Predictive Coding 4.0 methods allow a skilled attorney using the latest predictive coding type software to review at remarkable rates of speed and cost. The AI-enhanced review rates are more than 250-times faster than traditional linear review, and the costs less than a tenth as much. See eg Predictive Coding Narrative: Searching for Relevance in the Ashes of Enron; EDI-Oracle Study: Humans Are Still Essential in E-Discovery (LTN Nov., 2013); also see MrEDR.com.
My Life as a Limo Driver and Trainer
I have spoken on this subject at many CLEs around the world since 2011. I explain the theory and practice of this new breakthrough technology. I also consult on a hands-on basis to help others learn the new methods. As an old software lover who has been doing legal document reviews since 1980, I also continue to like to do these review projects myself. I like to run AI_enhanced document review projects myself, not just teach others or supervise what they do. I enjoy the interaction and enhancements from the hybrid, human-robot approach. Certainly I need an appreciate the artificial intelligence boosts to my own limited capacities.
I also like to serve as a kind of limo driver for trial lawyers from time to time. The top SMEs in the world (I prefer to work with the best), are almost never also software power-users, nor do they have special skills or talents for information seeking outside of depositions. For that reason they need me to run the review projects for them. To switch to the robot analogy again, I like and can work with the bots, they cannot.
I can only do my job as a limo driver – robot friend in an effective manner if the SME first teaches me enough of their domain to know where I am going; to know what documents would be relevant or hot or not. That is where decades of legal experience handling a variety of cases is quite helpful. It makes it easer to get a download of the SME’s concept of relevance into my head, and then into the machine. Then I can act as a surrogate SME and do the machine training for them in an accurate and consistent manner.

Working as a driver for an SME presents many special communication challenges. I have had to devise a number of techniques to facilitate a new kind of SME surrogate agency process. See: Predictive Coding 4.0 restated here in one post.
Of course, it is easier to do the search when you are also the SME. For instance, in one project I reviewed almost two million documents, by myself, in only two-weeks. That’s right. By myself. (There was no redaction or privilege logging, which are tasks that I always delegate anyway.) A quality assurance test at the end of the review based on random sampling showed a very high accuracy rate was attained. There is no question that it met the reasonability standards required by law and rules of procedure.
It was only possible to do a project of this size so quickly because I happened to be an SME on the legal issues under review, and, just as important, I was a power-user of the software, and have, at this point, mastered my own search and review methods.
Thanks to the new software and version 4.0 methods, what was considered impossible, even absurd, just a few short years ago, namely one attorney accurately reviewing two million documents by him or herself in 14-days, is attainable by many experts. My story is not unique. Maura tells me that she once did a seven-million document review by herself. That is why Maura and Gordon were correct to refer to TAR as a disruptive technology in the Preface to their Glossary. Technology that can empower one skilled lawyer to do the work of hundreds of unskilled attorneys is certainly a big deal, one for which we have Legal Search Science to thank. It is also why I urge you to study this subject more carefully and learn to train the document review robots yourself. Either that, or hire a limo driver like me.
Before you begin to actually carry out a predictive coding project, with or without an expert to run your project, you need to plan for it. This is critical to the success of the project. Here is detailed outline of a Form Plan for a Predictive Coding Project that I used to use as a complete checklist. (It’s a little dated now.)
My Writings on TAR
A good way to continue your study in this area is to read the articles by Grossman and Cormack, and the over sixty or so articles on the subject that I have written since mid-2011. They are listed in rough chronological order, with the most recent on top.
 I am especially proud of the legal search experiments I have done using AI-enhanced search software provided to me by Kroll Ontrack to review the 699,083 public Enron documents and my reports on these reviews. Comparative Efficacy of Two Predictive Coding Reviews of 699,082 Enron Documents. (Part Two); A Modest Contribution to the Science of Search: Report and Analysis of Inconsistent Classifications in Two Predictive Coding Reviews of 699,082 Enron Documents. (Part One). I have been told by scientists that my over 100 hours of search, comprised of two fifty-hour search projects using different methods, is the largest search project by a single reviewer that has ever been undertaken, not only in Legal Search, but in any kind of search. I do not expect this record will last for long, as others begin to understand the importance of Information Science in general, and Legal Search Science in particular. But for now I will enjoy both the record and lessons learned from the hard work involved.
I am especially proud of the legal search experiments I have done using AI-enhanced search software provided to me by Kroll Ontrack to review the 699,083 public Enron documents and my reports on these reviews. Comparative Efficacy of Two Predictive Coding Reviews of 699,082 Enron Documents. (Part Two); A Modest Contribution to the Science of Search: Report and Analysis of Inconsistent Classifications in Two Predictive Coding Reviews of 699,082 Enron Documents. (Part One). I have been told by scientists that my over 100 hours of search, comprised of two fifty-hour search projects using different methods, is the largest search project by a single reviewer that has ever been undertaken, not only in Legal Search, but in any kind of search. I do not expect this record will last for long, as others begin to understand the importance of Information Science in general, and Legal Search Science in particular. But for now I will enjoy both the record and lessons learned from the hard work involved.
April 2014 Slide Presentation by Ralph Losey on Predictive Coding Using now ‘slightly dated’ 3.0 Methods
Please contact me at Ralph.Losey at gmail dot com if you have any questions.
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] C.A.R. […]
[…] C.A.R. […]
[…] C.A.R. […]
[…] C.A.R. […]
[…] hacker focus on impact and led to my development of Bottom Line Driven Proportional Review and multimodal predictive coding search methods. Other hacker-oriented lawyers and technologists have developed their own methods to give clients […]
[…] a half. (They are listed at the end of this short essay as a convenient reference. Also see the new CAR page above that I recently added to my […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] means building new aggressive culling methods, such as Bottom Line Driven Proportional Review and multimodal predictive coding assisted review. SIRI and Pandora are the way of the future, not legions of low priced lawyers. The study of […]
[…] hacker focus on impact and led to my development of Bottom Line Driven Proportional Review and multimodal predictive coding search methods. Other hacker oriented lawyers and technologists have developed their own methods to give clients […]
[…] means building new aggressive culling methods, such as Bottom Line Driven Proportional Review and multimodal predictive coding assisted review. SIRI and Pandora are the way of the future, not legions of low priced lawyers. The study of […]
[…] CAR […]
[…] CAR […]
[…] to find better methods of predictive coding, and have uncovered an efficient approach with my multimodal CAL method. But I was still not satisfied with my recall validation approach, I wanted to find a better […]
[…] to avoid litigation, or for general business intelligence. See PreSuit.com and Computer Assisted Review. Legal Search Science as practiced today uses software with artificial intelligence features to […]
[…] this multimodal method many times here, and you will find summaries of it elsewhere, including my CAR page, and Legal Search Science, and the work in progress, the EDBP outlining best practices for lawyers […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]
[…] CAR […]