Sixth Class: Balanced Hybrid and Intelligently Spaced Training
Going down into the weeds a little bit more brings us to our Insight Number Six, Balanced Hybrid – IST. This is critical knowledge that must be fully understood to operate Predictive Coding 4.0. Expect to spend considerable time to fully understand this class. It has five parts: Introduction; More on IST; Factors Influencing Hybrid Balance; IST v. CAL; and, Pro Human Approach to Hybrid Man-Machine Partnership.
Introduction

The active monitoring dual feedback approach means that we must adjust software settings so that new learning sessions are not created automatically. They only run when and if we click on the Initiate Session button shown in the EDR screenshot below (arrow and words were added).

We do not want the training to go on continuously in the background (typically meaning at periodic intervals of every thirty minutes or so.) We only want the learning sessions to occur when we say so. In that way we can know exactly what documents EDR is training on during a session. Then, when that training session is complete, we can see how the input of those documents has impacted the overall data ranking. For instance, are there now more documents in the 90% or higher probable relevance category and if so, how many? The screen shot above is of a completed TREC project. The probability rankings are on the far left with the number of documents shown in the adjacent column. Most of the documents in the 290,099 collection of Bush email were in the 0-5% probable relevant ranking not included in the screen shot.
This means that the e-Discovery Team’s active learning is not continuous, in the sense of always training. It is instead intelligently spaced. That is an essential aspect of our Balanced Hybrid approach to electronic document review. The machine training only begins when we click on the “Initiate Session” button in EDR that the arrow points to. It is only continuous in the sense that the training continues until all human review is completed. The spaced training, in the sense of staggered in time, is itself an ongoing process until the production is completed. We call this Intelligently Spaced Training or “IST”.

Such ongoing training improves efficiency and precision, and also improves Hybrid human-machine communications. Thus, in our team’s opinion, IST is a better process of electronic document review than training automatically without human participation. This is the so-called CAL (“continuous active training”) approach promoted (and recently trademarked) by search experts and professors, Maura Grossman and Gordon Cormack.

Exactly how we space out the timing of training in IST is a little more difficult to describe without going into the particulars of a case. A full, detailed description would require the reader to have intimate knowledge of the EDR software. Our IST process is, however, software neutral. You can follow the IST dual feedback method of active machine learning with any document review software that has active machine learning capacities and also allows you to decide when to initiate a training session. (By the way, a training session is the same thing as a learning session, but we like to say training, not learning, as that takes the human perspective and we are pro-human!) You cannot do that if the training is literally continuous and cannot be halted while you input a new batch of relevance determined documents for training.
The details of IST, such as when to initiate a training session, and what human coded documents to select next for training, is an ad hoc process. It depends on the data itself, the issues involved in the case, the progress made, the stage of the review project and time factors. This is the kind of thing you learn by doing. It is not rocket science, but it does help keep the project interesting. Hire one of our team members to guide your next review project and you will see it in action. It is easier than it sounds. With experience Hybrid Multimodal IST becomes an intuitive process, much like riding a bicycle.
 To recap and summarize what we have learned so far, active machine learning should be a dual feedback process with double-loop learning. The training should continue throughout a project, but it should be spaced in time so that you can actively monitor the progress, what we call IST. The software should learn from the trainer, of course, but the trainer should also learn from the software. This requires active monitoring by the teacher who reacts to what he or she sees and adjusts the training accordingly so as to maximize recall and precision.
To recap and summarize what we have learned so far, active machine learning should be a dual feedback process with double-loop learning. The training should continue throughout a project, but it should be spaced in time so that you can actively monitor the progress, what we call IST. The software should learn from the trainer, of course, but the trainer should also learn from the software. This requires active monitoring by the teacher who reacts to what he or she sees and adjusts the training accordingly so as to maximize recall and precision.
 This is really nothing more than a common sense approach to teaching. No teacher who just mails in their lessons, and does not pay attention to the students, is ever going to be effective. The same is true for active machine learning. That’s the essence of the insight. Simple really.
This is really nothing more than a common sense approach to teaching. No teacher who just mails in their lessons, and does not pay attention to the students, is ever going to be effective. The same is true for active machine learning. That’s the essence of the insight. Simple really.
More On Balanced Hybrid Using Intelligently Spaced Training – IST™
The Balanced Hybrid insight is complementary to Active Machine Learning. It has to do with the relationship between the human training the machine and the machine itself. The name itself says it all, namely that is it balanced. We rely on both software and skilled attorneys using the software.

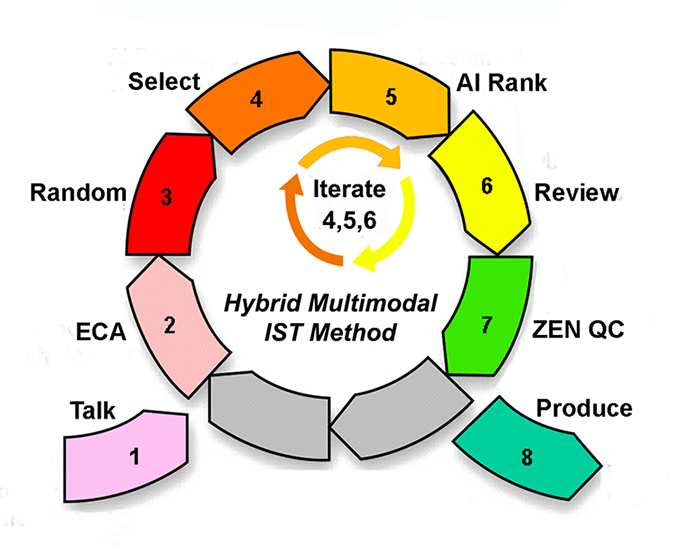
We advocate reliance on the machine after it become trained, after it starts to understand your conception of relevance. At that point we find it very helpful to rely on what the machine has determined to be the documents most likely to be relevant. We have found it is a good way to improve precision in the sixth step of our 8-step document review methodology shown below. We generally use a balanced approach where we start off relying more on human selections of documents for training based on their knowledge of the case and other search selection processes, such as keyword or passive machine learning, a/k/a concept search. See steps 2 and 4 of our 8-step method – ECA and Select. Then we switch to relying more on the machine as it’s understanding catches one. See steps 4 and 5 – Select and AI Rank. It is usually balanced throughout a project with equal weight given to the human trainer, typically a skilled attorney, and the machine, a predictive coding algorithm of some time, typically logistic regression or support vector.
{kind=link}
Unlike other methods of Active Machine Learning we do not completely turn over to the machine all decisions as to what documents to review next. We look to the machine for guidance as to what documents should be reviewed next, but it is always just guidance. We never completely abdicate control over to the machine. I have gone into this before at some length in my article Why the ‘Google Car’ Has No Place in Legal Search. In this article I cautioned against over reliance on fully automated methods of active machine learning. Our method is designed to empower the humans in control, the skilled attorneys. Thus although our Hybrid method is generally balanced, our scale tips slightly in favor of humans, the team of attorneys who run the document review. We favor humans. So while we like our software very much, and have even named it Mr. EDR, we have an unabashed favoritism for humans. More on this at the conclusion of the Balanced Hybrid section of this article.

Factors Influencing the Hybrid Balance
The insights we gained in TREC 2016 into Hybrid machine/human interaction represent more of a deepening of understanding, rather than anything new. The Hybrid AI/Lawyer interaction is familiar to most document review experts who use active machine learning. Our 2016 TREC research improved our understanding of when and why the Balanced Hybrid approach should be tipped one way or another towards greater reliance on humans or machine.
On some projects we found that your precision and recall improves by putting greater reliance of the AI, on the machine. These are typically projects where one or more of the following conditions exist:
* the data itself is very complex and difficult to work with, such as specialized forum discussions; or,
* the search target is ill-defined, i.w. – no one is really sure what they are looking for; or,
* the Subject Matter Expert (SME) making final determinations on relevance has limited experience and expertise.
 On some projects your precision and recall improves by putting even greater reliance of the humans, on the skilled attorneys working with the machine. These are typically projects where the converse of one or more of the three criteria above are present:
On some projects your precision and recall improves by putting even greater reliance of the humans, on the skilled attorneys working with the machine. These are typically projects where the converse of one or more of the three criteria above are present:
* the data itself is fairly simple and easy to work with, such as a disciplined email user (note this has little or nothing to do with data volume) or,
* the search target is well-defined, i.w. there are clearly defined search requests and everyone is on the same page as to what they are looking for; or,
* the Subject Matter Expert (SME) making final determinations on relevance has extensive experience and expertise.
What was somewhat surprising in our 2016 TREC research is how one-sided you can go on the Human side of the equation and still attain near perfect recall and precision. The Jeb Bush email underlying all thirty-four of our topics in TREC Total Recall Track 2016 was, at that point, well-known to us. It is fairly simple and easy to work with. Although the spelling of the thousands of constituents who wrote to Jeb Bush was atrocious (far worse than general corporate email, except maybe construction company emails), Jeb’s use of the email was fairly disciplined and predictable. As a Florida native and lawyer who lived through the Jeb Bush era, and was generally familiar with all of the issues, and have become very familiar with his email, I became a pretty good SME, and, to a somewhat lesser extent, so has my whole team. (I did all ten of the Bush Topics in 2015 and another ten in 2016.) Also, we had fairly well-defined, simple search goals in most of the topics.
 For these reasons in many of these 2016 TREC document review projects the role of the machine and machine ranking became fairly small. In some that I handled it was reduced to a quality control, quality assurance method. The machine would pick up and catch a few documents that the lawyers alone had missed, but only a few. The machine thus had a slight impact on improved recall, but not much effect at all on precision, which was anyway very high. (More on this experience with easy search topics later in this essay when we talk about our Keyword Search insights.)
For these reasons in many of these 2016 TREC document review projects the role of the machine and machine ranking became fairly small. In some that I handled it was reduced to a quality control, quality assurance method. The machine would pick up and catch a few documents that the lawyers alone had missed, but only a few. The machine thus had a slight impact on improved recall, but not much effect at all on precision, which was anyway very high. (More on this experience with easy search topics later in this essay when we talk about our Keyword Search insights.)
On a few of the 2016 TREC Topics the search targets were not well-defined. On these Topics our SME skills were necessarily minimized. Thus in these few Topics, even though the data itself was simple, we had to put greater reliance on the machine (in our case Mr. EDR) than on the attorney reviewers.
It bears repeating that the volume of emails has nothing to do with the ease or difficulty of the review project. This is a secondary question and is not dispositive as to how much weight you need to give to machine ranking. (Volume size may, however, have a big impact on project duration.)
IST v. CAL
 Our Balanced Hybrid approach now uses what we call Intelligently Spaced Training, or IST™, not Grossman and Cormack’s CAL, for two reasons.
Our Balanced Hybrid approach now uses what we call Intelligently Spaced Training, or IST™, not Grossman and Cormack’s CAL, for two reasons.
1. Our previous use of the term CAL for version 3.0 was only to refer to the fact that our method of training was continuous, in that it continued and was ongoing throughout a document review project. The term CAL has come to mean much more than that, and thus our continued use of the term may cause confusion.
2. Trademark rights have recently been asserted by Professors Grossman and Cormack, who originated this acronym CAL. As they have refined the use of the mark it now not only stands for Continuous Active Learning throughout a project, but also stands for a particular method of training that only uses the highest ranked documents.
Under the Grossman-Cormack CAL method the machine training continues throughout the document review project, as it does under our IST method, but there the similarities end. Under their CAL method of predictive coding the machine trains automatically as soon as a new document is coded (or some other predefined interval). Further, the document or documents are selected by the software itself. The selection is a fully automated process. The only role of the human is to say yes or no as to relevance of the document. The human does not select which document or documents to review next to say yes or no to. That is controlled by the algorithm, the machine.
The CAL method is only hybrid, like the e-Discovery Team method, in the sense of man and machine working together. But, from our perspective, if used blindly, it is not balanced. In fact, from our perspective the fully automated CAL training document selection method improperly favors the machine. This may be the whole point of their method, to limit the human role as much as possible. The attorney has no role to play at all in selecting what document to review next. It does not matter if the attorney understands the training process. Personally, we do not like that. We want to be in charge and fully engaged throughout. We want the computer to be our tool, not our master.

Under our IST method the attorney chooses what documents to review next. We do not need the computer’s permission. We decide whether to accept a batch of high-ranking documents from the machine, or not. The attorney may instead find documents that they think are relevant from other methods. Even if the high ranked method of selection of training documents is used, the attorney decides the number of such documents to use and whether to supplement the machine selection with other training documents.
The one thing in common between IST and CAL is that both processes continue throughout the life of a document review project and both are concerned with the Stop decision (when to when to stop the training and project). Under both methods after the Stopping point no new documents are selected for review and production. Instead, quality assurance methods that include sampling reviews are begun. If the quality assurance tests affirm that the decision to stop review was reasonable, then the project concludes. If they fail, more training and review are initiated.
 Aside from the differences in document selection between CAL and IST, the primary difference is that under IST the attorney decides when to train. The training does not occur automatically after each document, or specified number of documents, or at certain arbitrary time periods, as is common with most software. In the e-Discovery Team method of IST, which, again, stands for Intelligently Spaced (or staggered) Training, the attorney in charge decide when to train. We control the clock, the clock does not control us. The machine does not decide. Attorneys use their own intelligence to decide when to train the machine.
Aside from the differences in document selection between CAL and IST, the primary difference is that under IST the attorney decides when to train. The training does not occur automatically after each document, or specified number of documents, or at certain arbitrary time periods, as is common with most software. In the e-Discovery Team method of IST, which, again, stands for Intelligently Spaced (or staggered) Training, the attorney in charge decide when to train. We control the clock, the clock does not control us. The machine does not decide. Attorneys use their own intelligence to decide when to train the machine.
This timing control allows the attorney to observe the impact of the training on the machine. It is designed to improve the communication between man and machine. That is the double-loop learning process described in the last Class as one of the insights into Active Machine Learning. The attorney trains the machine and the machine is observed so that the trainer can learn how well the machine is doing. The attorney can learn what aspects of the relevance rule have been understood and what aspects still need improvement. Based on this student to teacher feedback the teacher is able to customize the next rounds of training to fit the needs of the student. This maximizes efficiency and effectiveness and is the essence of double-loop learning.
As a result of our methods, and ever increasing familiarity with the advanced machine learning algorithms, the Hybrid experience is becoming more intense. The communications are improving, especially with IST and the double feedback loop.  Our relationship with the AI is improving, growing form a mere touch to something more intimate, deeper and more expansive. This is not only observed by the Team in TREC research, but also in everyday legal search projects. The result is that we are experiencing a new kind of deep intuition or sensitivity as to the workings of the machine. We are developing a sensitivity for the intelligence created artificially by the active machine learning process. I predict that in the very near future this kind of experience will become common place for many people and much more intense. This is just the beginning of a new kind of communication ability.
Our relationship with the AI is improving, growing form a mere touch to something more intimate, deeper and more expansive. This is not only observed by the Team in TREC research, but also in everyday legal search projects. The result is that we are experiencing a new kind of deep intuition or sensitivity as to the workings of the machine. We are developing a sensitivity for the intelligence created artificially by the active machine learning process. I predict that in the very near future this kind of experience will become common place for many people and much more intense. This is just the beginning of a new kind of communication ability.
 You could call this a new kind of super power if you wish, as I did humorously to answer the question posed to me in the video interview below by my friend Tom O’Connor (which, he did not know, I had expected and prepared for). This newfound human ability is just a natural extension of the Hybrid man-machine interaction. Anybody can attain this. To us it seems like an intuition or feeling that you get for the AI’s operations. You get a feel from the process as to the code’s evolving ability to understand your conception of relevance. You get a deep kind of robotic intuition.
You could call this a new kind of super power if you wish, as I did humorously to answer the question posed to me in the video interview below by my friend Tom O’Connor (which, he did not know, I had expected and prepared for). This newfound human ability is just a natural extension of the Hybrid man-machine interaction. Anybody can attain this. To us it seems like an intuition or feeling that you get for the AI’s operations. You get a feel from the process as to the code’s evolving ability to understand your conception of relevance. You get a deep kind of robotic intuition.
Sounds strange, I know – intuitive feel for an algorithm, an AI – but I do not know how else to describe the experience. That is why we like to personify our machine, our AI algorithms with the Mr. EDR robot image. It is all about making the AI your friend, developing a closer, more intuitive relationship with computers.

Ralph, Jason, Robot in TREC 2015
This may seem far out, and may well be impossible to describe to anyone who has not yet had the experience, but in the video interview excerpt below in 2017 Story Booth at U.F. Law, I give it a try:
Try our methods, especially the IST double-loop Hybrid training methods described in this class. They are designed to enhance and improve the human-machine connection. After a while you may have this experience yourself. Everyone needs a “superpower” and this one may be well within your reach.

Pro Human Approach to Hybrid Man-Machine Partnership
To wrap up the new Balanced Hybrid insights we would like to point out that our terminology speaks of Training– IST – rather than Learning – CAL. We do this intentionally because training is consistent with our human perspective. Mr. EDR is our friend, and we can develop an intuitive sense for the intelligence developing, but we are still the boss, still the teacher. That is our perspective whereas, that of the trainer, whereas the perspective of the machine is to learn. The attorney trains and the machine learns.
 We promote and aim for deep hybrid connections, but, in the process, we favor humans. Our goal is empowerment of attorney search experts to find the truth (relevance), the whole truth (recall) and nothing but the truth (precision). Our goal is to enhance human intelligence with artificial intelligence. Thus we prefer a Balanced Hybrid approach with IST (training) and not CAL (learning). This is a fundamental differentiator between our IST approach and CAL.
We promote and aim for deep hybrid connections, but, in the process, we favor humans. Our goal is empowerment of attorney search experts to find the truth (relevance), the whole truth (recall) and nothing but the truth (precision). Our goal is to enhance human intelligence with artificial intelligence. Thus we prefer a Balanced Hybrid approach with IST (training) and not CAL (learning). This is a fundamental differentiator between our IST approach and CAL.
This is not to say the CAL approach with machine controlled training document selection is not good and does not work. It appears to work fine. It is just too boring for us and often too slow and imprecise. Plus a deep level intuition is impossible with CAL, at least that has been our experience. Overall we think CAL is less efficient and less effective than our Hybrid Multimodal method. But, even though it is not for us, it may be well be good for many beginners. It is simple to operate, if you do not mind the trade-offs. From language in the Grossman Cormack patents that appears to be what they are going for – simplicity and ease of use. They have that and a growing body of evidence that it works.
We wish them well, and also their software and CAL methodology. It is just not for us, as we prefer to control the timing, the space, between our training. Yes, that adds to the complexity a bit, but it also allows for improved double loop communications. The extra control gives us a little more wiggle-room for human creativity and innovation.

Some experts in the pro-machine selection camp argue the advantages of simplicity, plus they also argue based on so called safety issues. They argue that it is safer to rely on AI because a machine is more reliable than a human, in the same way that Google’s self-driving car is safer and more reliable than a human driven car. Of course, unlike driving a car, they still need a human, an attorney, to decide yes or no on relevance, and so they are stuck with human reviewers. They are stuck with a least a partial Hybrid method, albeit one favoring as much as possible the machine side of the partnership. We do not think the pro-machine approach will work with attorneys, nor should it. We think that only an unabashedly pro-human approach like ours is likely to be widely adopted in the legal marketplace.
The goal of the pro-machine approach is to minimize human judgments, no matter how skilled, and thereby reduce as much as possible the influence of human error and outright fraud. This is a part of a larger debate in the technology world. We respectfully disagree with this approach, at least in so far as legal document review is concerned. (Personally I tend to agree with it in so far as the driving of automobiles is concerned.) We instead seek enhancement and empowerment of attorneys by technology, including quality controls and fraud detection. See Why the ‘Google Car’ Has No Place in Legal Search. New software will assist in fraud detection.

 This delegation to automated methods will not stop fraud as the full-automation side argues. The SMEs are still programing relevance input. But it will decrease precision and so drive up the costs of review. It will also result in too many lost black swans when a bad stop decision is made. There are other, more effective ways to guard against crooked attorneys. It is overkill and wrongheaded to try to remove all attorneys from the equation to guard against the fraud of a few. The system already has numerous safeguards in place to detect and punish fraud. Think sanctions and the inherent authority of the court. Besides, experienced e-discovery lawyers can already detect document omissions, especially when using ranking based searches. They can also sense the few rotten attorneys out there. Your reputation travels with you. I can just look at certain lawyers and know what they are made of. It is a kind of intuition arising from long experience.
This delegation to automated methods will not stop fraud as the full-automation side argues. The SMEs are still programing relevance input. But it will decrease precision and so drive up the costs of review. It will also result in too many lost black swans when a bad stop decision is made. There are other, more effective ways to guard against crooked attorneys. It is overkill and wrongheaded to try to remove all attorneys from the equation to guard against the fraud of a few. The system already has numerous safeguards in place to detect and punish fraud. Think sanctions and the inherent authority of the court. Besides, experienced e-discovery lawyers can already detect document omissions, especially when using ranking based searches. They can also sense the few rotten attorneys out there. Your reputation travels with you. I can just look at certain lawyers and know what they are made of. It is a kind of intuition arising from long experience.
I predict the attorney fraud issue will be further addressed soon by specialized software designed to look for fraud indicators in ESI productions. That will further empower attorneys to detect the few trying to rig the system, and many more just operating out of some level of negligence. The abusers of discovery must be stopped.
No doubt you will be hearing more about this interesting “Google Car” debate in the coming years. It may well have a significant impact on technology in the law, the quality of justice, and the future of lawyer employment. The way I see it, for professions like law and medicine, the focus should be on augmentation, not automation. These are personal services. Information, reason and logic are only a small part of what practicing attorneys and judges do. Lawyers’ Job Security in a Near Future World of AI, the Law’s “Reasonable Man Myth” and “Bagley Two.” Part One and Part Two. The same goes for physicians and medical services.
Or pause to do this suggested “homework” assignment for further study and analysis.
SUPPLEMENTAL READING: Read the article Why the ‘Google Car’ Has No Place in Legal Search. Also read Lawyers’ Job Security in a Near Future World of AI, the Law’s “Reasonable Man Myth” and “Bagley Two” – Part One and Part Two. Also read: Dean Gonsowski,
We suggest you also look at AI and the hybrid relationship from the perspective of the medical profession. Check out the New Yorker article, AI versus MD (April 3, 2017). The article will also help you to understand the limitations inherent in AI, and any training program, including this one. Humans and AI both learn by rules assimilation and by practice, experience. To truly understand and master Predictive Coding 4.0 you need to practice it, to use it, ideally under the supervision of someone who has already mastered it.
EXERCISES: Find and read the Grossman Cormack patents and trademarks pertaining to TAR and CAL. Study especially the comments in the patent applications regarding other TAR related legal search software now on the market. Note the dates of these comments and consider how the early 1.0 and 2.0 versions of predictive coding have since changed. Can you find any products underlying the Grossman and Cormack patents and trademark? (Do not spend too much time on this search.)
Search for other uses of the term “hybrid” in the general field of artificial intelligence. Read a few of these articles. Also look for use of the terms “automation” versus “augmentation” or “enhancement” in the AI field and read a few of these too.
Students are invited to leave a public comment below. Insights that might help other students are especially welcome. Let’s collaborate!
_
e-Discovery Team LLC COPYRIGHT 2017
ALL RIGHTS RESERVED
_