 Getting predictive coding software is just part of the answer to the high-cost of legal review. Much more important is how you use it, which in turn depends, at least in part, on which software you get. That is why I have been focusing on methods for using the new technologies. I have been advocating for what I call the hybrid multimodal method. I created this method on my own over many years of legal discovery. As it turns out, I was merely reinventing the wheel. These methods are already well-established in the scientific information retrieval community. (Thanks to information scientist Jeremy Pickens, an expert in collaborative search, who helped me to find the prior art.)
Getting predictive coding software is just part of the answer to the high-cost of legal review. Much more important is how you use it, which in turn depends, at least in part, on which software you get. That is why I have been focusing on methods for using the new technologies. I have been advocating for what I call the hybrid multimodal method. I created this method on my own over many years of legal discovery. As it turns out, I was merely reinventing the wheel. These methods are already well-established in the scientific information retrieval community. (Thanks to information scientist Jeremy Pickens, an expert in collaborative search, who helped me to find the prior art.)
In this blog I will share some of the classic information science research that supports hybrid multimodal. It includes the work of Gary Marchionini, Professor and Dean of the School of Information and Library Sciences of U.N.C. at Chapel Hill, and UCLA Professor Marcia J. Bates who has advocated for a multimodal approach to search since 1989. Study of their writings has enabled me to better understand and refine my methods. I hope you will also explore with me the literature in this field. I provide links to some of the books and literature in this area for your further study.
Advanced CARs Require Completely New Driving Methods
First I need to set the stage for this discussion by use of the eight-step diagram show below. This is one of the charts I created to teach the workflow I use in a typical computer assisted review (CAR) project. You have seen it here many times before. For a full description of the eight steps see the Electronic Discovery Best Practices page on predictive coding.
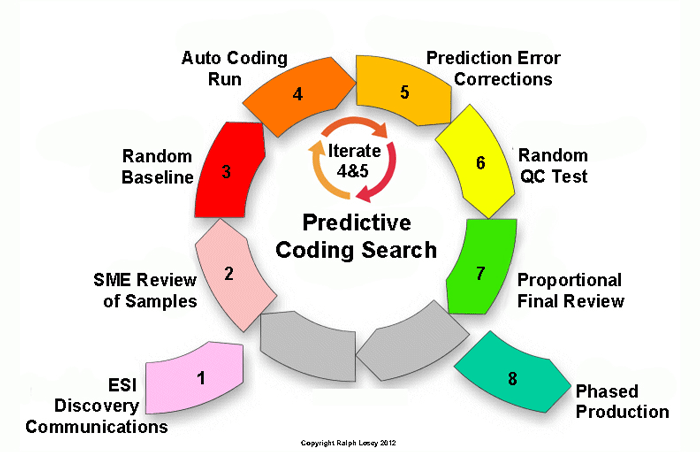
The iterated steps four and five in this work-flow are unique to predictive coding review. They are where active learning takes place. The Grossman-Cormack Glossary defines active learning as:
An Iterative Training regimen in which the Training Set is repeatedly augmented by additional Documents chosen by the Machine Learning Algorithm, and coded by one or more Subject Matter Expert(s).
The Grossman-Cormack Glossary of Technology-Assisted Review, 2013 Fed. Cts. L. Rev. 7 (2013). at pg.
Beware of any co-called advanced review software that does not include these steps; they are not bona-fide predictive coding search engines. My preferred active learning process is threefold:
1. The computer selects documents for review where the software classifier is uncertain of the correct classification. This helps the classifier algorithms to learn by adding diversity to the documents presented for review. This in turn helps to locate outliers of a type your initial judgmental searches in step two (and five) of the above diagram have missed. This is machine-selected sampling, and, according to a basic text in information retrieval engineering, a process is not a bona fide active learning search without this ability. Manning, Raghavan and Schutze, Introduction to Information Retrieval, (Cambridge, 2008) at pg. 309.
2. Some reasonable percentage of the documents presented for human review in step five are selected at random. This again helps maximize recall and premature focus on the relevant documents initially retrieved.
3. Other relevant documents that a skilled reviewer can find using a variety of search techniques. This is called judgmental sampling. After the first round of training, a/k/a the seed set, judgmental sampling by a variety of search methods is used based on the machine selected or random selected documents presented for review. Sometimes the subject matter expert (“SME”) human reviewer may follow a new search idea unrelated to the documents presented. Any kind of searches can be used for judgmental sampling, which is why I call it a multimodal search. This may include some linear review of selected custodians or dates, parametric Boolean keyword searches, similarity searches of all kinds, concept searches, as well as several unique predictive coding probability searches.
The initial seed set generation, step two in the chart, should also use some random samples, plus judgmental multimodal searches. Steps three and six in the chart always use pure random samples and rely on statistical analysis. For more on the three types of sampling see my blog, Three-Cylinder Multimodal Approach To Predictive Coding.
My insistence on the use of multimodal judgmental sampling in steps two and five to locate relevant documents follows the consensus view of information scientists specializing in information retrieval, but is not followed by several prominent predictive coding vendors. They instead rely entirely on machine selected documents for training, or even worse, rely entirely on random selected documents to train the software. In my writings I call these processes the Borg approach, after the infamous villans in Star Trek, the Borg, an alien race that assimilates people. (I further differentiate between three types of Borg in Three-Cylinder Multimodal Approach To Predictive Coding.) Like the Borg, these approaches unnecessarily minimize the role of individuals, the SMEs. They exclude other types of search to supplement an active learning process. I advocate the use of all types of search, not just predictive coding.
Hybrid Human Computer Information Retrieval

In contradistinction to Borg approaches, where the machine controls the learning process, I advocate a hybrid approach where Man and Machine work together. In my hybrid CARs the expert reviewer remains in control of the process, and their expertise is leveraged for greater accuracy and speed. The human intelligence of the SME is a key part of the search process. In the scholarly literature of information science this hybrid approach is known as Human–computer information retrieval (HCIR).
The classic text in the area of HCIR, which I endorse, is Information Seeking in Electronic Environments (Cambridge 1995) by Gary Marchionini, Professor and Dean of the School of Information and Library Sciences of U.N.C. at Chapel Hill. Professor Marchionini speaks of three types of expertise needed for a successful information seeker:
1. Domain Expertise. This is equivalent to what we now call SME, subject matter expertise. It refers to a domain of knowledge. In the context of law the domain would refer to particular types of lawsuits or legal investigations, such as antitrust, patent, ERISA, discrimination, trade-secrets, breach of contract, Qui Tam, etc. The knowledge of the SME on the particular search goal is extrapolated by the software algorithms to guide the search. If the SME also has System Expertise, and Information Seeking Expertise, they can drive the CAR themselves. Otherwise, they will need a chauffeur with such expertise, one who is capable of learning enough from the SME to recognize the relevant documents.
2. System Expertise. This refers to expertise in the technology system used for the search. A system expert in predictive coding would have a deep and detailed knowledge of the software they are using, including the ability to customize the software and use all of its features. In computer circles a person with such skills is often called a power-user. Ideally a power-user would have expertise in several different software systems.
3. Information Seeking Expertise. This is a skill that is often overlooked in legal search. It refers to a general cognitive skill related to information seeking. It is based on both experience and innate talents. For instance, “capabilities such as superior memory and visual scanning abilities interact to support broader and more purposive examination of text.” Professor Marchionini goes on to say that: “One goal of human-computer interaction research is to apply computing power to amplify and augment these human abilities.” Some lawyers seem to have a gift for search, which they refine with experience, broaden with knowledge of different tools, and enhance with technologies. Others do not, or the gift is limited to interviews and depositions.
Id. at pgs.66-69, with the quotes from pg. 69.
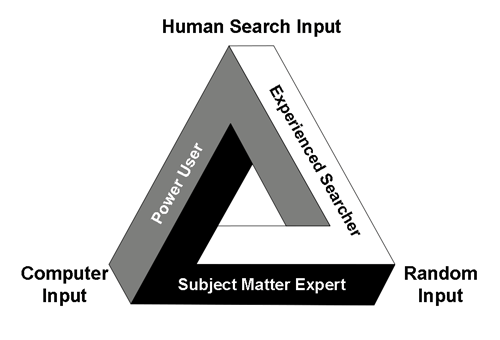
All three of these skills are required for an attorney to attain expertise in legal search today, which is one reason I find this new area of legal practice so challenging. It is difficult, but not impossible like this Penrose triangle.

It is not enough to be an SME, or a power-user, or have a special knack for search. You have to be able to do it all. However, studies have shown that of the three skill-sets, System Expertise, which in legal search primarily means mastery of the particular software used, is the least important. Id. at 67. The SMEs are more important, those who have mastered a domain of knowledge. In Professor Marchionini’s words:
Thus, experts in a domain have greater facility and experience related to information-seeking factors specific to the domain and are able to execute the subprocesses of information seeking with speed, confidence, and accuracy.
Id. That is one reason that the Grossman Cormack glossary builds in the role of SMEs as part of their base definition of computer assisted review:
A process for Prioritizing or Coding a Collection of electronic Documents using a computerized system that harnesses human judgments of one or more Subject Matter Expert(s) on a smaller set of Documents and then extrapolates those judgments to the remaining Document Collection.
Grossman-Cormack Glossary at pg. 21 defining TAR.
According to Marchionini, Information Seeking Expertise, much like Subject Matter Expertise, is also more important than specific software mastery. Id. This may seem counter-intuitive in the age of Google, where an illusion of simplicity is created by typing in words to find websites. But legal search of user-created data is a completely different type of search task than looking for information from popular websites. In the search for evidence in a litigation, or as part of a legal investigation, special expertise in information seeking is critical, including especially knowledge of multiple search techniques and methods. Again quoting Professor Marchionini:
Expert information seekers possess substantial knowledge related to the factors of information seeking, have developed distinct patterns of searching, and use a variety of strategies, tactics and moves.
Id. at 70.
In the field of law this kind of information seeking expertise includes the ability to understand and clarify what the information need is, in other words, to know what you are looking for, and articulate the need into specific search topics. This important step precedes the actual search, but should thereafter continue as an integral part of the process. As one of the basic texts on information retrieval written by Gordon Cormack, et al, explains:
Before conducting a search, a user has an information need, which underlies and drives the search process. We sometimes refer to this information need as a topic …
Buttcher, Clarke & Cormack, Information Retrieval: Implementation and Evaluation of Search Engines (MIT Press, 2010) at pg. 5.
The importance of pre-search refining of the information need is stressed in the first step of the above diagram of my methods, ESI Discovery Communications. It seems very basic, but is often under appreciated, or overlooked entirely in the litigation context. In legal discovery information needs are often vague and ill-defined, lost in overly long requests for production and adversarial hostility. In addition to concerted activity up front to define relevance, the issue of information need should be kept in mind throughout the project. Typically our understanding of relevance evolves as our understanding of what really happened in a dispute emerges and grows.
At the start of an e-discovery project we are almost never searching for specific known documents. We never know for sure what information we will discover. That is why the phrase information seeking is actually more appropriate for legal search than information retrieval. Retrieval implies that particular facts exist and are already known; we just need to look them up. Legal search is not like that at all. It is a process of seeking and discovery. Again quoting Professor Marchionini:
The term information seeking is preferred to information retrieval because it is more human oriented and open ended. Retrieval implies that the object must have been “known” at some point; most often, those people who “knew” it organized it for later “knowing” by themselves or someone else. Seeking connotes the process of acquiring knowledge; it is more problem oriented as the solution may or may not be found.
Information Seeking in Electronic Environments, supra at 5-6.
Legal search is a process of seeking information, not retrieving information. It is a process of discovery, not simple look-up of known facts. More often than not in legal search you find the unexpected, and your search evolves as it progresses. Concept shift happens. Or you find nothing at all. You discover that the requesting party has sent you hunting for Unicorns, for evidence that simply does not exist. For example, the plaintiff alleges discrimination, but a search through tens of thousands of defendant’s emails shows no signs of it.
Information scientists have been talking about the distinction between machine oriented retrieval and human oriented seeking for decades. The type of discovery search that lawyers do is referred to in the literature (without any specific mention of law or legal search) as exploratory search. See: White & Roth, Exploratory Search: Beyond the Query-Response Paradigm (Morgan & Claypool, 2009). Ryen W. White, Ph.D., a senior researcher at Microsoft Research, builds on the work of Marchionini and gives this formal definition of exploratory search:
Exploratory search can be used to describe an information-seeking problem context that is open-ended, persistent, and multi-faceted; and to describe information-seeking processes that are opportunistic, iterative, and multi-tactical. In the first sense, exploratory search is commonly used in scientific discovery, learning, and decision-making contexts. In the second sense, exploratory tactics are used in all manner of information seeking and reflect seeker preferences and experience as much as the goal.
Id. at 6. He could easily have added legal discovery to this list, but like most information scientists, seems unacquainted with the law and legal search.
White and Roth point out that exploratory search typically uses a multimodal (berrypicking) approach to information needs that begin as vague notions. A many-methods-approach helps the information need to evolve and become more distinct and meaningful over time. They contend that the information-seeking strategies need to be supported by system features and user interface designs, bringing humans more actively into the search process. Id. at 15. That is exactly what I mean by a hybrid process where lawyers are actively involved in the search process.
The fully Borg approach has it all wrong. They use a look-up approach to legal search that relies as much as possible on fully automated systems. The user interface for this type of information retrieval software is designed to keep humans out of the search, all in the name of ease of use and impartiality. The software designers of these programs, typically engineers working without adequate input from lawyers, erroneously assume that e-discovery is just a retrieval task. They erroneously assume that predictive coding always starts with well-defined information needs that do not evolve with time. Some engineers and lit-support techs may fall for this myth, but all practicing lawyers know better. They know that legal discovery is an open-ended, persistent, and multi-faceted process of seeking.
Hybrid Multimodal Computer Assisted Review
Professor Marchionini notes that information seeking experts develop their own search strategies, tactics and moves. The descriptive name for the strategies, tactics and moves that I have developed for legal search is Hybrid Multimodal Computer Assisted Review Bottom Line Driven Proportional Strategy. See eg. Bottom Line Driven Proportional Review (2013). For a recent federal opinion approving this type of hybrid multimodal search and review see: In Re: Biomet M2a Maagnum Hip Implant Products Liability Litigation (MDL 2391), Case No. 3:12-MD-2391, (N.D. Ind., April 18, 2013); also see: Indiana District Court Approves Multimodal Computer Assisted Review.
I refer to this method as a multimodal because, although the predictive coding type of searches predominate (shown on the below diagram as Intelligent Review or IR), other modes of search are also employed. As described, I do not rely entirely on random documents, or computer selected documents. The other types of methods used in a multimodal process are shown in this search pyramid.
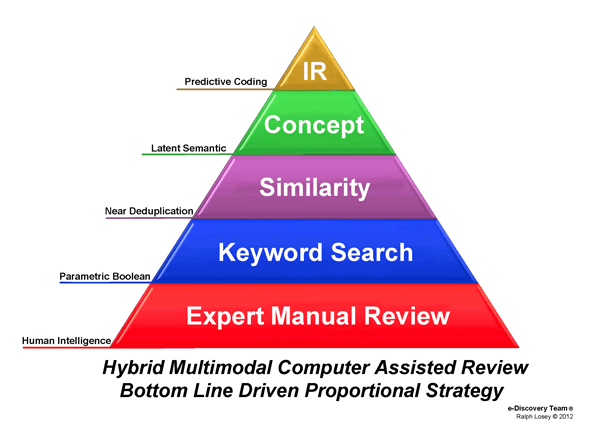
Most information scientists I have spoken to agree that it makes sense to use multiple methods in legal search and not just rely on any single method. UCLA Professor Marcia J. Bates first advocated for using multiple search methods back in 1989, which she called berrypicking. Bates, Marcia J., The Design of Browsing and Berrypicking Techniques for the Online Search Interface, Online Review 13 (October 1989): 407-424. As Professor Bates explained in 2011 in Quora:
An important thing we learned early on is that successful searching requires what I called “berrypicking.” … Berrypicking involves 1) searching many different places/sources, 2) using different search techniques in different places, and 3) changing your search goal as you go along and learn things along the way. This may seem fairly obvious when stated this way, but, in fact, many searchers erroneously think they will find everything they want in just one place, and second, many information systems have been designed to permit only one kind of searching, and inhibit the searcher from using the more effective berrypicking technique.
This berrypicking approach, combined with HCIR exploratory search, is what I have found from practical experience works best with legal search. They are the Hybrid Multimodal aspects of my Computer Assisted Review Bottom Line Driven Method.
Conclusion
 Now that we have shown that courts are very open to predictive coding, we need to move on to a different, more sophisticated discussion. We need to focus on analysis of different predictive coding search methods, the strategies, tactics and moves. We also need to understand and discuss what skill-sets and personnel are required to do it properly. Finally, we need to begin to discuss the different types of predictive coding software.
Now that we have shown that courts are very open to predictive coding, we need to move on to a different, more sophisticated discussion. We need to focus on analysis of different predictive coding search methods, the strategies, tactics and moves. We also need to understand and discuss what skill-sets and personnel are required to do it properly. Finally, we need to begin to discuss the different types of predictive coding software.
There is much more to discuss concerning the use predictive coding than whether or not to make disclosure of seed sets or irrelevant training documents. Although that, and court approval, are the only things most expert panels have talked about so far. The discussion on disclosure and work-product should continue, but let us also discuss the methods and skills, and, yes, even the competing software.
We cannot look to vendors alone for the discussion and analysis of predictive coding software and competing methods of use. Obviously they must focus on their own software. This is where independent practitioners have an important role to play in the advancement of this powerful new technology.
Join with me in this discussion by your comments below or send me ideas for proposed guest blogs. Vendors are of course welcome to join in the discussion, and they make great hosts for search SME forums. Vendors are an important part of any successful e-discovery team. You cannot do predictive coding review without their predictive coding software, and, as with any other IT product, some software is much better than others.
Discover more from e-Discovery Team
Subscribe to get the latest posts sent to your email.
[…] here answers my call for critical papers on predictive coding, a call I made just last week in Reinventing the Wheel: My Discovery of Scientific Support for “Hybrid Multimodal” Search. Although Bill Speros keeps a lower profile than other experts in the field, most insiders know […]
[…] Reinventing the Wheel: My Discovery of Scientific Support for “Hybrid Multimodal” Search – http://bit.ly/11x65De (@RalphLosey) […]
[…] Reinventing the Wheel: My Discovery of Scientific Support for “Hybrid Multimodal” Search; […]
[…] [23] See David Cowen, Job Market Heating Up for e-Discovery Technologists, Managers, and Attorneys; Losey, R., Reinventing the Wheel: My Discovery of Scientific Support for “Hybrid Multimodal” Search found at http://e-discoveryteam.com/2013/04/21/reinventing-the-wheel-my-discovery-of-scientific-support-for-h…. […]
[…] [23] See David Cowen, Job Market Heating Up for e-Discovery Technologists, Managers, and Attorneys; Losey, R., Reinventing the Wheel: My Discovery of Scientific Support for “Hybrid Multimodal” Search found at http://e-discoveryteam.com/2013/04/21/reinventing-the-wheel-my-discovery-of-scientific-support-for-h…. […]
[…] Reinventing the Wheel: My Discovery of Scientific Support for “Hybrid Multimodal” Search. […]
[…] should be driven by the unique nature of the case and the production involved. In other words, as Ralph Losey has put it before, we should be approaching it in a “multimodal search” […]
[…] HCIR process (Human Computer Information Retrieval). See search of my blog of HCIR, and especially Reinventing the Wheel: My Discovery of Scientific Support for “Hybrid Multimodal” Search. They are the drivers of […]