 Legal Search Science is an interdisciplinary field concerned with the search, review, and classification of large collections of electronic documents to find information for use as evidence in legal proceedings, for compliance to avoid litigation, or for general business intelligence. See Computer Assisted Review. Legal Search Science as practiced today uses software with artificial intelligence features to help lawyers to find electronic evidence in a systematic, repeatable, and verifiable manner. See: TAR Training Course (sixteen class course teaches our latest insights and methods of Predictive Coding 4.0) and the over sixty or so articles on the subject that I have written since mid-2011. The hybrid search method of AI human computer interaction developed in this field that will inevitably have a dramatic impact on the future practice of law. Lawyers will never be replaced entirely by robots embodying AI search algorithms, but the productivity of some lawyers using AI will allow them to do the work of dozens, if not hundreds of lawyers.
Legal Search Science is an interdisciplinary field concerned with the search, review, and classification of large collections of electronic documents to find information for use as evidence in legal proceedings, for compliance to avoid litigation, or for general business intelligence. See Computer Assisted Review. Legal Search Science as practiced today uses software with artificial intelligence features to help lawyers to find electronic evidence in a systematic, repeatable, and verifiable manner. See: TAR Training Course (sixteen class course teaches our latest insights and methods of Predictive Coding 4.0) and the over sixty or so articles on the subject that I have written since mid-2011. The hybrid search method of AI human computer interaction developed in this field that will inevitably have a dramatic impact on the future practice of law. Lawyers will never be replaced entirely by robots embodying AI search algorithms, but the productivity of some lawyers using AI will allow them to do the work of dozens, if not hundreds of lawyers.
My own experience (Ralph Losey) provides an example. I participated in a study in 2013 where I searched and reviewed over 1.6 Millions documents by myself, with only the assistance of one computer – one robot, so to speak – running AI-enhanced software by Kroll Ontrack. I was able to do so more accurately and faster than large teams of lawyers working without artificial intelligence software. I was even able to work faster and more accurately than all other teams of lawyers and vendors that used AI-enhanced software, but did not use the science-based search methods described here. I do not attribute my success to my own intelligence, or any special gifts or talents. (They are very moderate.) I was able to succeed by applying the established scientific methods described here and in more detail in our TAR Training Course. They allowed me to augment my own small intelligence with that of the machine. If I have any special skills, it is in human-computer interaction, and legal search intuition. They are based on my long experience in the law with evidence (over 35 years), and in my experience in the last few years using predictive coding software.
 Legal Search Science as I understand it is a combination and subset of three fields of study: Information Science, the legal field of Electronic Discovery, and the engineering field concerned with the design and creation of Search Software. Its primary concern is with information retrieval and the unique problems faced by lawyers in the discovery of relevant evidence.
Legal Search Science as I understand it is a combination and subset of three fields of study: Information Science, the legal field of Electronic Discovery, and the engineering field concerned with the design and creation of Search Software. Its primary concern is with information retrieval and the unique problems faced by lawyers in the discovery of relevant evidence.
Most specialists in legal search science use a variety of search methods when searching large datasets. The use of multiple methods of search is referred to here as a multimodal approach. Although many search methods are used at the same time, the primary, or controlling search method in large projects is typically what is known as supervised or semi-supervised machine learning. Semi-supervised learning is a type of artificial intelligence (AI) that uses an active learning approach. I refer to this as AI-enhanced review or AI-enhanced search. In information science it is often referred to as active machine learning, and in legal circles as Predictive Coding.
For reliable introductory information on Legal Search Science see the works of attorney, Maura Grossman, and her information scientist partner, Professor Gordon Cormack, including:
- Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014, at pg. 9.
- Technology-Assisted Review in E-Discovery Can Be More Effective and More Efficient Than Exhaustive Manual Review, Richmond Journal of Law and Technology, Vol. XVII, Issue 3, Article 11 (2011);
- The Grossman-Cormack Glossary of Technology-Assisted Review, 2013 Fed. Cts. L. Rev. 7 (January 2013);
- Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery (SIGIR 2014).
The Grossman-Cormack Glossary explains that in machine learning:
Supervised Learning Algorithms (e.g., Support Vector Machines, Logistic Regression, Nearest Neighbor, and Bayesian Classifiers) are used to infer Relevance or Non-Relevance of Documents based on the Coding of Documents in a Training Set. In Electronic Discovery generally, Unsupervised Learning Algorithms are used for Clustering, Near-Duplicate Detection, and Concept Search.
For another perspective see the over sixty or so articles on the subject that I have written since mid-2011. They are listed in rough chronological order, with the most recent on top. The most important of these articles is Predictive Coding 4.0.
 Multimodal search uses both machine learning algorithms and unsupervised learning search tools (clustering, near-duplicates and concept), as well as keyword search and even some limited use of traditional linear search. This is further explained here in the section below entitled, Hybrid Multimodal Bottom Line Driven Review. The hybrid multimodal aspects described represent the consensus view among information search scientists. The bottom line driven aspects represent my legal overlay on the search methods. All of these components together make up what I call Legal Search Science. It represents a synthesis of knowledge and search methods from science, law, and software engineering.
Multimodal search uses both machine learning algorithms and unsupervised learning search tools (clustering, near-duplicates and concept), as well as keyword search and even some limited use of traditional linear search. This is further explained here in the section below entitled, Hybrid Multimodal Bottom Line Driven Review. The hybrid multimodal aspects described represent the consensus view among information search scientists. The bottom line driven aspects represent my legal overlay on the search methods. All of these components together make up what I call Legal Search Science. It represents a synthesis of knowledge and search methods from science, law, and software engineering.
The key definition of the Glossary is for Technology Assisted Review, their term for AI-enhanced review.
Technology-Assisted Review (TAR): A process for Prioritizing or Coding a Collection of Documents using a computerized system that harnesses human judgments of one or more Subject Matter Expert(s) on a smaller set of Documents and then extrapolates those judgments to the remaining Document Collection. Some TAR methods use Machine Learning Algorithms to distinguish Relevant from Non-Relevant Documents, based on Training Examples Coded as Relevant or Non-Relevant by the Subject Matter Experts(s), …. TAR processes generally incorporate Statistical Models and/or Sampling techniques to guide the process and to measure overall system effectiveness.
The Grossman-Cormack Glossary makes clear the importance of Subject Matter Experts (SMEs) by including their use as the document trainer into the very definition of TAR. Nevertheless, experts agree that good predictive coding software is able to tolerate some errors made in the training documents. For this reason experiments are being done on ways to minimize the central role of the SMEs, to see if lesser-qualified persons could also be used in document training, at least to some degree. See Webber & Pickens, Assessor Disagreement and Text Classifier Accuracy (SIGIR, 2013); John Tredennick, Subject Matter Experts: What Role Should They Play in TAR 2.0 Training? (2013). These experiments are of special concern to software developers and others who would like to increase the utilization of AI-enhanced software because, at the current time, very few SMEs in the law have the skills or time necessary to conduct AI-enhanced searches. This is one reason that predictive coding is still not widely used, even though it has been proven effective in multiple experiments and adopted by several courts.

Professor Oard
For in-depth information on key experiments already performed in the field of Legal Search Science, see the TREC Legal Track reports whose home page is maintained by a leader in the field, information scientist, Doug Oard. Professor Oard is a co-founder of the TREC Legal track. Also see the research and reports of Herb Rotiblat and the Electronic Discovery Institute, and my papers on TREC (and otherwise as listed below): Analysis of the Official Report on the 2011 TREC Legal Track – Part One, Part Two and Part Three; and Secrets of Search: Parts One, Two, and Three.
For general legal background on the field of Legal Search Science see the works of the attorney co-founder of TREC Legal Track, Jason R. Baron, including:
- Baron & Grossman, The Sedona Conference® Best Practices Commentary on the Use of Search and Information Retrieval Methods in E-Discovery (2013).pdf (December 2013).
- Baron & Borden, Finding the Signal in the Noise: Information Governance, Analytics and the Future of Legal Practice (2014).
- Baron & Freeman, Quick Peek at the Math Behind the Black Box of Predictive Coding (2013)
- Baron, DESI, Sedona and Barcelona (2013)
- Baron & Paul, Information Inflation: Can The Legal System Adapt? 13 Rich J.L. & Tech 10 (2007).
 As explained in Baron and Freeman’s Quick Peek at the Math, and my blog introduction thereto, the supervised learning algorithms behind predictive coding utilize a hyper-dimensional space. Each each document in the dataset, including its metadata, represent a different dimension mapped in trans-Cartesian space, called hyper-planes. Each document is placed according to a multi-dimensional dividing line of relevant and irrelevant. The important document ranking feature of predictive coding is performed by measure as to how far from the dividing line a particular document lies. Each time a training session is run the line moves and the ranking fluctuates in accordance with the new information provided. The below diagram attempts to portray this hyperplane division and document placement. The points shown in red designate irrelevant documents and the blue points relevant documents. The dividing line would run through multiple dimensions, not just the usual two of a Cartesian graph. This is depicted in this diagram by folding fields. For more read the entire Quick Peek article.
As explained in Baron and Freeman’s Quick Peek at the Math, and my blog introduction thereto, the supervised learning algorithms behind predictive coding utilize a hyper-dimensional space. Each each document in the dataset, including its metadata, represent a different dimension mapped in trans-Cartesian space, called hyper-planes. Each document is placed according to a multi-dimensional dividing line of relevant and irrelevant. The important document ranking feature of predictive coding is performed by measure as to how far from the dividing line a particular document lies. Each time a training session is run the line moves and the ranking fluctuates in accordance with the new information provided. The below diagram attempts to portray this hyperplane division and document placement. The points shown in red designate irrelevant documents and the blue points relevant documents. The dividing line would run through multiple dimensions, not just the usual two of a Cartesian graph. This is depicted in this diagram by folding fields. For more read the entire Quick Peek article.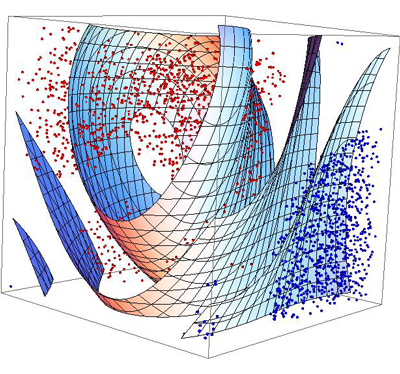
For a scientific and statistical view of Legal Search Science that is often at least somewhat intelligible to lawyers and other non-scientists, see the blog of information scientist and consultant, William Webber, Evaluating e-Discovery. Also see the many judicial opinions approving and encouraging the use of predictive coding.
AI-Enhanced Search Methods
AI-enhanced search represents an entirely new method of legal search, which requires a completely new approach to large document reviews. Below is the diagram of the latest Predictive Coding 4.0 workflow I use in a typical predictive coding project.

For a full description of the eight steps take our free sixteen class online training program. See: TAR Training Course.
I have found that proper AI-enhanced review is the most interesting and exciting activity in electronic discovery law. Predictive Coding version 3.0 is The tool that we have all been waiting for. When used properly, i.w. Version 4.0, good AI-enhanced software such as Mr.EDR, allows attorneys to find the information they need in vast stores of ESI, and to do so in an effective and affordable manner.
Hybrid Human Computer Information Retrieval

Further, in contradistinction to Borg approaches, where the machine controls the learning process, I advocate a hybrid approach where Man and Machine work together. In my hybrid search and review projects the expert reviewer remains in control of the process, and their expertise is leveraged for greater accuracy and speed. The human intelligence of the SME is a key part of the search process. In the scholarly literature of information science this hybrid approach is known as Human–computer information retrieval (HCIR). (My thanks to information scientist Jeremy Pickens for pointing out this literature to me.)
The classic text in the area of HCIR, which I endorse, is Information Seeking in Electronic Environments (Cambridge 1995) by Gary Marchionini, Professor and Dean of the School of Information and Library Sciences of U.N.C. at Chapel Hill. Professor Marchionini speaks of three types of expertise needed for a successful information seeker:
- Domain Expertise. This is equivalent to what we now call SME, subject matter expertise. It refers to a domain of knowledge. In the context of law the domain would refer to the particular type of lawsuit or legal investigation, such as antitrust, patent, ERISA, discrimination, trade-secrets, breach of contract, Qui Tam, etc. The knowledge of the SME on the particular search goal is extrapolated by the software algorithms to guide the search. If the SME also has the next described System Expertise and Information Seeking Expertise, they can run the search project themselves. That is what I like to call the Army of One approach. Otherwise, they will need a chauffeur or surrogate with such expertise, one who is capable of learning enough from the SME to recognize the relevant documents.
- System Expertise. This refers to expertise in the technology system used for the search. A system expert in predictive coding would have a deep and detailed knowledge of the software they are using, including the ability to customize the software and use all of its features. In computer circles a person with such skills is often called a power-user. Ideally a power-user would have expertise in several different software systems. They would also be an expert in one or more particular method of search.
- Information Seeking Expertise. This is a skill that is often overlooked in legal search. It refers to a general cognitive skills related to information seeking. It is based on both experience and innate talents. For instance, “capabilities such as superior memory and visual scanning abilities interact to support broader and more purposive examination of text.” Professor Marchionini goes on to say that: “One goal of human-computer interaction research is to apply computing power to amplify and augment these human abilities.” Some lawyers seem to have a gift for search, which they refine with experience, broaden with knowledge of different tools, and enhance with technologies. Others do not.
Id. at pgs.66-69, with the quotes from pg. 69.
All three of these skills are required for an legal team to have the expertise in legal search today, which is one reason I find this new area of legal practice so interesting and exciting. See: TAR Training Course.
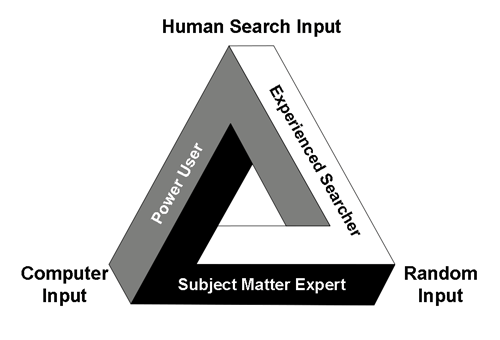
It is not enough to be an SME, or a power-user, or have a special knack for search. You need a team that has it all, and great software. However, studies have shown that of the three skill-sets, System Expertise, which in legal search primarily means mastery of the particular software used (Power User), is the least important. Id. at 67. The SMEs are more important, those who have mastered a domain of knowledge. In Professor Marchionini’s words:
Thus, experts in a domain have greater facility and experience related to information-seeking factors specific to the domain and are able to execute the subprocesses of information seeking with speed, confidence, and accuracy.
Id. That is one reason that the Grossman Cormack glossary quoted before builds in the role of SMEs as part of their base definition of technology assisted review. Glossary at pg. 21 defining TAR.
According to Marchionini, Information Seeking Expertise, much like Subject Matter Expertise, is also more important than specific software mastery. Id. This may seem counter-intuitive in the age of Google, where an illusion of simplicity is created by typing in words to find websites. But legal search of user-created data is a completely different type of search task than looking for information from popular websites. In the search for evidence in a litigation, or as part of a legal investigation, special expertise in information seeking is critical, including especially knowledge of multiple search techniques and methods. Again quoting Professor Marchionini:
Expert information seekers possess substantial knowledge related to the factors of information seeking, have developed distinct patterns of searching, and use a variety of strategies, tactics and moves.
Id. at 70.
In the field of law this kind of information seeking expertise includes the ability to understand and clarify what the information need is, in other words, to know what you are looking for, and articulate the need into specific search topics. This important step precedes the actual search, but is an integral part of the process. As one of the basic texts on information retrieval written by Gordon Cormack, et al, explains:
Before conducting a search, a user has an information need, which underlies and drives the search process. We sometimes refer to this information need as a topic …
Buttcher, Clarke & Cormack, Information Retrieval: Implementation and Evaluation of Search Engines (MIT Press, 2010) at pg. 5. The importance of pre-search refining of the information need is stressed in the first step of the above diagram of my methods, ESI Discovery Communications. It seems very basic, but is often under appreciated, or overlooked entirely in the litigation context where information needs are often vague and ill-defined, lost in overly long requests for production and adversarial hostility.
Hybrid Multimodal Bottom Line Driven Review
I have a long name for what Marchionini calls the variety of strategies, tactics and moves that I have developed for legal search: Hybrid Multimodal. See: TAR Training Course. This sixteen class course teaches our latest insights and methods of Predictive Coding 4.0.. I refer to it as a multimodal method because, although the predictive coding type of searches predominate (shown on the below diagram as AI-enhanced review – AI), I also use the other modes of search, including the mentioned Unsupervised Learning Algorithms (clustering and concept), keyword search, and even some traditional linear review (although usually very limited). As described, I do not rely entirely on random documents, or computer selected documents for the AI-enhanced searches, but use a three-cylinder approach that includes human judgment sampling and AI document ranking. The various types of legal search methods used in a multimodal process are shown in this search pyramid.

Most information scientists I have spoken to agree that it makes sense to use multiple methods in legal search and not just rely on any single method, even the best AI method. UCLA Professor Marcia J. Bates first advocated for using multiple search methods back in 1989, which she called it berrypicking. Bates, Marcia J. The Design of Browsing and Berrypicking Techniques for the Online Search Interface, Online Review 13 (October 1989): 407-424. As Professor Bates explained in 2011 in Quora:
An important thing we learned early on is that successful searching requires what I called “berrypicking.” … Berrypicking involves 1) searching many different places/sources, 2) using different search techniques in different places, and 3) changing your search goal as you go along and learn things along the way. This may seem fairly obvious when stated this way, but, in fact, many searchers erroneously think they will find everything they want in just one place, and second, many information systems have been designed to permit only one kind of searching, and inhibit the searcher from using the more effective berrypicking technique.
This berrypicking approach, combined with HCIR, is what I have found from practical experience works best with legal search. They are the Hybrid Multimodal aspects of my AI-Enhanced Review Bottom Line Driven Review method.
Why AI-Enhanced Search and Review Is Important
I focus on this sub-niche area of e-discovery because I am convinced that it is critical to advancement of the law in the 21st Century. The new search and review methods that I have developed from my studies and experiments in legal search science allow a skilled attorney using readily available predictive coding type software to review at remarkable rates of speed and cost. Review rates are more than 250-times faster than traditional linear review, and costs less than a tenth as much. See eg Predictive Coding Narrative: Searching for Relevance in the Ashes of Enron, and the report by the Rand Corporation, Where The Money Goes: Understanding Litigant Expenditures for Producing Electronic Discovery.
Thanks to the new software and methods, what was considered impossible, even absurd, just a few short years ago, namely one attorney accurately reviewing over a million documents by him or herself in 14-days, is attainable by many experts. I have done it. That is when I came up with the Army of One motto and realized that we were at a John Henry moment in Legal Search. Maura tells me that she once did a seven-million document review by herself. Maura and Gordon were correct to refer to TAR as a disruptive technology in the Preface to their Glossary. Technology that can empower one skilled lawyer to do the work of hundreds of unskilled attorneys is certainly a big deal, one for which we have Legal Search Science to thank.

More Information On Legal Search Science
For further information on Legal Search Science see all of the articles cited above, along with the over sixty or so articles on the subject that I have written since mid-2011. Also enroll in our free 16 class TAR Training Course. This course teaches our latest insights and methods of Predictive Coding 4.0. Most of my articles were written for the general reader, some are highly technical but still accessible with study. All have been peer-reviewed in my blog by most of the founders of this field who are regular readers and thousands of other readers.
I am especially proud of the legal search experiments I have done using AI-enhanced search software provided to me by Kroll Ontrack to review the 699,083 public Enron documents and my reports on these reviews. Comparative Efficacy of Two Predictive Coding Reviews of 699,082 Enron Documents. (Part Two); A Modest Contribution to the Science of Search: Report and Analysis of Inconsistent Classifications in Two Predictive Coding Reviews of 699,082 Enron Documents. (Part One). I have been told by scientists in the field that my over 100 hours of search, consisting of two fifty-hour search projects using different methods, is the largest search project by a single reviewer that has ever been undertaken, not only in Legal Search, but in any kind of search. I do not expect this record will last for long, as others begin to understand the importance of Information Science in general, and Legal Search Science in particular.
