This is the seventh and last installment of the article explaining the e-Discovery Team’s latest enhancements to electronic document review using Predictive Coding. Here are Parts One, Two, Three, Four, Five and Six. This series explains the nine insights behind the latest upgrade to version 4.0. It also explains slight revisions these insights triggered to the eight-step workflow. We have already covered the nine insights and the first three steps in our slightly revised eight-step workflow. We will now cover the remaining five steps.

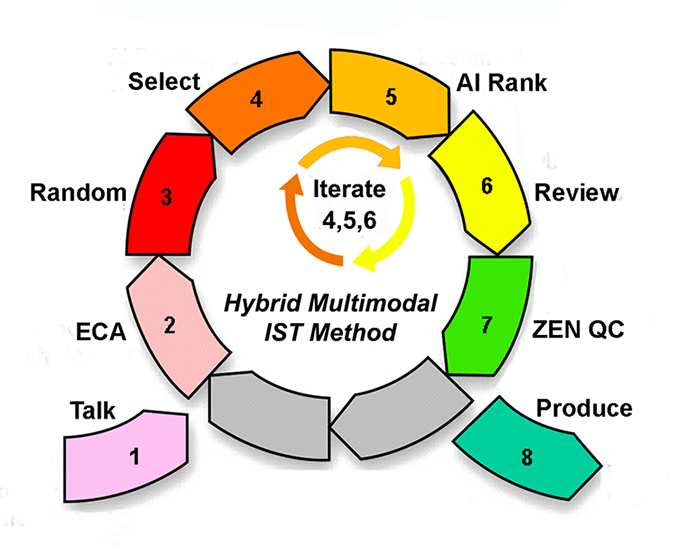
Steps Four, Five and Six – Training Select, AI Document Ranking and Multimodal Review
These are the three iterated steps that are the heart of our active machine learning process. The description of steps four, five and six constitutes the most significant change, although the content of what we actually do has not changed much. We have changed the iterated steps order by making a new step four – Training Select. We have also changed somewhat the descriptions in Predictive Coding Version 4.0. This was all done to better clarify and simplify what we are doing. This is our standard work flow. Our old description now seems somewhat confusing. As Steve Jobs famously said:
You have to work hard to get your thinking clean to make it simple. But it’s worth it in the end because once you get there, you can move mountains.
In our case it can help you to move mountains of data by proper use of active machine learning.

In version 3.0 we called these three iterated steps: AI Predictive Ranking (step 4), Document Review (step 5), and Hybrid Active Training (step 6). The AI Predictive Ranking step, now called AI Document Ranking, was moved from step four to step five. This is to clarify that the task of selecting documents for training always comes before the training itself. We also made Training Selection a separate step to emphasize the importance of this task. This is something that we have come to appreciate more fully over the past year.
 The AI Document ranking step is where the computer does its thing. It is where the algorithm goes into action and ranks all of the documents according to the training documents selected by the humans. It is the unique AI step. The black box. No human efforts in step five at all. All we do is wait on the machine analysis. When it is done, all documents have been ranked (first time) or reranked (all training rounds after the first). We slightly tweaked the name here to be AI Document Ranking, instead of AI Predictive Ranking, as that is, we think, a clearer description of what the machine is doing. It is ranking all documents according to probability of relevance, or whatever other binary training you are doing. For instance, we usually also rank all documents according to probable privilege too and also according to high relevance.
The AI Document ranking step is where the computer does its thing. It is where the algorithm goes into action and ranks all of the documents according to the training documents selected by the humans. It is the unique AI step. The black box. No human efforts in step five at all. All we do is wait on the machine analysis. When it is done, all documents have been ranked (first time) or reranked (all training rounds after the first). We slightly tweaked the name here to be AI Document Ranking, instead of AI Predictive Ranking, as that is, we think, a clearer description of what the machine is doing. It is ranking all documents according to probability of relevance, or whatever other binary training you are doing. For instance, we usually also rank all documents according to probable privilege too and also according to high relevance.
Our biggest change here in version 4.0 is to make this AI step number five, instead of four, and, as mentioned, to add a new step four called Training Select. The new step four – Training Select – is the human function of deciding what documents to use to train the machine. (This used to be included in iterated step six, which was, we now see, somewhat confusing.) Unlike other predictive coding methods, we empower humans to make this selection in step four, Training Select. We do not, like some methods, create automatic rules for selection of training documents. For example, the Grossman Cormack CAL method (their trademark) only uses a predetermined number of the top ranked documents for training. In our method, we could also select these top ranked documents, or we could include other documents we have found to be relevant from other methods.
 The freedom and choices that our method provides to the humans in charge is another reason our method is called Hybrid, in that it features natural human intelligence. It is not all machine controlled. In Predictive Coding 4.0 we use artificial intelligence to enhance or augment our own natural intelligence. The machine is our partner, our friend, not our competitor or enemy. We tell our tool, our computer algorithm, what documents to train on in step four, and when, and the machine implements in step five.
The freedom and choices that our method provides to the humans in charge is another reason our method is called Hybrid, in that it features natural human intelligence. It is not all machine controlled. In Predictive Coding 4.0 we use artificial intelligence to enhance or augment our own natural intelligence. The machine is our partner, our friend, not our competitor or enemy. We tell our tool, our computer algorithm, what documents to train on in step four, and when, and the machine implements in step five.
Typically in step four, Training Select, we will include all documents that we have previously coded as relevant as training documents, but not always. Sometimes, for instance, we may defer including very long relevant documents in the training, especially large spreadsheets, until the AI has a better grasp of our relevance intent. Skilled searchers rarely use all documents coded as training documents, but sometimes do. The same reasoning may apply to excluding a very short message, such as a one word message saying “call,” although we are more likely to leave that in. This selection process is where the art and experience of search come in. The concern is to avoid over-training on any one document type and thus lowering recall and missing a key black-swan document.
 Also, we now rarely include all irrelevant documents into training, but instead used a balanced approach. Otherwise we tend to see incorrectly low rankings cross the board. The 50% plus dividing line can be an inaccurate indicator of probable relevant. It may instead go down to 40%, or even lower. We also find the balanced approach allows the machine to learn faster. Information scientists we have spoken with on this topic say this is typical with most types of active machine learning algorithms. It is not unique to our Mr. EDR, an active machine learning algorithm that uses an logistic regression method.
Also, we now rarely include all irrelevant documents into training, but instead used a balanced approach. Otherwise we tend to see incorrectly low rankings cross the board. The 50% plus dividing line can be an inaccurate indicator of probable relevant. It may instead go down to 40%, or even lower. We also find the balanced approach allows the machine to learn faster. Information scientists we have spoken with on this topic say this is typical with most types of active machine learning algorithms. It is not unique to our Mr. EDR, an active machine learning algorithm that uses an logistic regression method.
The sixth step of Multimodal Review is where we find new relevant or irrelevant documents for the next round of training. This is the step where most of the actual document review is done, where the documents are seen and classified by human reviewers. It is thus like step two, multimodal ECA. But now in step six we can also performed ranking searches, such as find all documents ranked 90% probable relevant or higher. Usually we rely heavily on such ranking searches.
We then human review all of the documents, which can often include very fast skimming and bulk coding. In addition to these ranked searches for new documents to review and code, we can use any other type of search we deem appropriate. This is the multimodal approach. Typically keyword and concept searches are used less often after the first round of training, but similarity searches of all kinds are often used throughout a project to supplement ranking based searches. Sometimes we may even use a linear search, expert manual review at the base of the search pyramid, if a new hot document is found. For instance, it might be helpful to see all communications that a key witness had on a certain day. The two-word stand-alone call me email when seen in context can sometimes be invaluable to proving your case.

 Step six is much like step two, Multimodal ECA, except that now new types of document ranking search are possible. Since the documents are now all probability ranked in step five, you can use this ranking to select documents for the next round of document review (step four). For instance, the research of Professors Cormack and Grossman has shown that selection of the highest ranked documents can be a very effective method to continuously find and train relevant documents. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014, at pg. 9. Also see Latest Grossman and Cormack Study Proves Folly of Using Random Search for Machine Training – Parts One, Two, Three and Four. Another popular method, also tested and reported on by Grossman and Cormack, is to select mid-ranked documents, the ones the computer is uncertain about. They are less fond of that method, and we are too, but we will sometimes use it too.
Step six is much like step two, Multimodal ECA, except that now new types of document ranking search are possible. Since the documents are now all probability ranked in step five, you can use this ranking to select documents for the next round of document review (step four). For instance, the research of Professors Cormack and Grossman has shown that selection of the highest ranked documents can be a very effective method to continuously find and train relevant documents. Evaluation of Machine-Learning Protocols for Technology-Assisted Review in Electronic Discovery, SIGIR’14, July 6–11, 2014, at pg. 9. Also see Latest Grossman and Cormack Study Proves Folly of Using Random Search for Machine Training – Parts One, Two, Three and Four. Another popular method, also tested and reported on by Grossman and Cormack, is to select mid-ranked documents, the ones the computer is uncertain about. They are less fond of that method, and we are too, but we will sometimes use it too.
The e-Discovery team’s preferred active learning process in the iterative machine learning steps of Predictive Coding 4.0 is still four-fold, just as it was in version 3.0. It is multimodal. How you mix and match the search methods is a matter of personal preference and educated response to the data searched. Here are my team’s current preferences for most projects. Again, the weight for each depends upon the project. The only constant is that more that one method is always used.
 1. High Ranked Documents. My team will almost always look to see what the highest unreviewed ranked documents are after AI Ranking, step five. We agree with Cormack and Grossman that this is a very effective search. We may review them on a document by document basis, or only by spot-checking some of them. In the later spot-checking scenario, a quick review of a certain probable relevant range, say all documents ranked between 95% to 99.9% (Mr. EDR has no 100%), may show that they all seem obvious relevant. We may then bulk code all documents in that range as relevant without actually reviewing them. This is a very powerful and effective method with Mr. EDR, and other software, so long as care is used not to over-extend the probability range. In other situations, we may only select the 99%+ probable relevant set for checking and bulk coding with limited review. The safe range typically changes as the review evolves and your latest conception of relevance is successfully imprinted on the computer.
1. High Ranked Documents. My team will almost always look to see what the highest unreviewed ranked documents are after AI Ranking, step five. We agree with Cormack and Grossman that this is a very effective search. We may review them on a document by document basis, or only by spot-checking some of them. In the later spot-checking scenario, a quick review of a certain probable relevant range, say all documents ranked between 95% to 99.9% (Mr. EDR has no 100%), may show that they all seem obvious relevant. We may then bulk code all documents in that range as relevant without actually reviewing them. This is a very powerful and effective method with Mr. EDR, and other software, so long as care is used not to over-extend the probability range. In other situations, we may only select the 99%+ probable relevant set for checking and bulk coding with limited review. The safe range typically changes as the review evolves and your latest conception of relevance is successfully imprinted on the computer.
Note that when we say a document is selected without individual review – meaning no human actually read the document – that is only for purposes of training selection and identifying relevant documents for production. We sometimes call that first pass review. In real world projects for clients we always review each document found in steps four, five and six, that has not been previously reviewed by a human, before we produce the document. (This is not true in our academic or scientific studies for TREC or EDI/Oracle.) That takes place in the last step – step eight, Productions. To be clear, in legal practice we do not produce without human verification and review of each and every document produced. The stakes if an error is made are simply too high.
 In our cases the most enjoyable part of the review project comes when we see from this search method that Mr. EDR has understood our training and has started to go beyond us. He starts to see patterns that we cannot. He amazingly unearths documents that our team never thought to look for. The relevant documents he finds are sometimes dissimilar to any others found. They do not have the same key words, or even the same known concepts. Still, Mr. EDR sees patterns in these documents that we do not. He finds the hidden gems of relevance, even outliers and black swans. That is when we think of Mr. EDR as going into superhero mode. At least that is the way my e-Discovery Team likes to talk about him.
In our cases the most enjoyable part of the review project comes when we see from this search method that Mr. EDR has understood our training and has started to go beyond us. He starts to see patterns that we cannot. He amazingly unearths documents that our team never thought to look for. The relevant documents he finds are sometimes dissimilar to any others found. They do not have the same key words, or even the same known concepts. Still, Mr. EDR sees patterns in these documents that we do not. He finds the hidden gems of relevance, even outliers and black swans. That is when we think of Mr. EDR as going into superhero mode. At least that is the way my e-Discovery Team likes to talk about him.
By the end of most projects Mr. EDR attains a much higher intelligence and skill level than our own (at least on the task of finding the relevant evidence in the document collection). He is always lightening fast and inexhaustible, even untrained, but by the end of his education, he becomes a genius. Definitely smarter and faster than any human as to this one production review task. Mr. EDR in that kind of superhero mode is what makes Predictive Coding so much fun. See Why I Love Predictive Coding.
 Watching AI with higher intelligence than your own, intelligence which you created by your training, is exciting. More than that, the AI you created empowers you to do things that would have been impossible before, absurd even. For instance, using Mr. EDR, my e-Discovery Team of three attorneys was able to do 30 review projects and classify 16,576,820 documents in 45 days. See TREC 2015 experiment summary at Mr. EDR. This was a very gratifying feeling of empowerment, speed and augmentation of our own abilities. The high-AI experience comes though very clearly in the ranking of Mr. EDR near the end of the project, or really anytime before that, when he catches on to what you want and starts to find the hidden gems. I urge you all to give Predictive Coding a try so you can have this same kind of advanced AI hybrid excitement.
Watching AI with higher intelligence than your own, intelligence which you created by your training, is exciting. More than that, the AI you created empowers you to do things that would have been impossible before, absurd even. For instance, using Mr. EDR, my e-Discovery Team of three attorneys was able to do 30 review projects and classify 16,576,820 documents in 45 days. See TREC 2015 experiment summary at Mr. EDR. This was a very gratifying feeling of empowerment, speed and augmentation of our own abilities. The high-AI experience comes though very clearly in the ranking of Mr. EDR near the end of the project, or really anytime before that, when he catches on to what you want and starts to find the hidden gems. I urge you all to give Predictive Coding a try so you can have this same kind of advanced AI hybrid excitement.
 2. Mid-Ranked Uncertain Documents. We sometimes choose to allow the machine, in our case Mr. EDR, to select the documents for review in the sense that we review some of the mid-range ranked documents. These are documents where the software classifier is uncertain of the correct classification. They are usually in the 40% to 60% probable relevant range. Human guidance on these documents as to their relevance will sometimes help the machine to learn by adding diversity to the documents presented for review. This in turn also helps to locate outliers of a type the initial judgmental searches in step two and six may have missed. If a project is going well, we may not need to use this type of search at all.
2. Mid-Ranked Uncertain Documents. We sometimes choose to allow the machine, in our case Mr. EDR, to select the documents for review in the sense that we review some of the mid-range ranked documents. These are documents where the software classifier is uncertain of the correct classification. They are usually in the 40% to 60% probable relevant range. Human guidance on these documents as to their relevance will sometimes help the machine to learn by adding diversity to the documents presented for review. This in turn also helps to locate outliers of a type the initial judgmental searches in step two and six may have missed. If a project is going well, we may not need to use this type of search at all.
 3. Random and Judgmental Sampling. We may also select some documents at random, either by proper computer random sampling or, more often, by informal random selection, including spot-checking. The later is sometimes called judgmental sampling. These sampling techniques can help maximize recall by avoidance of a premature focus on the relevant documents initially retrieved. Random samples taken in steps three and six are typically also all included for training, and, of course, are always very carefully reviewed. The use of random selection for training purposes alone was minimized in Predictive Coding 3.0 and remains of lower importance in version 4.0. With today’s software, and using the multimodal method, it is not necessary. We did all of our TREC research without random sampling. We very rarely see the high-ranking searches become myopic without it. Plus, our multimodal approach guards against such over-training throughout the process.
3. Random and Judgmental Sampling. We may also select some documents at random, either by proper computer random sampling or, more often, by informal random selection, including spot-checking. The later is sometimes called judgmental sampling. These sampling techniques can help maximize recall by avoidance of a premature focus on the relevant documents initially retrieved. Random samples taken in steps three and six are typically also all included for training, and, of course, are always very carefully reviewed. The use of random selection for training purposes alone was minimized in Predictive Coding 3.0 and remains of lower importance in version 4.0. With today’s software, and using the multimodal method, it is not necessary. We did all of our TREC research without random sampling. We very rarely see the high-ranking searches become myopic without it. Plus, our multimodal approach guards against such over-training throughout the process.
4. Ad Hoc Searches Not Based on Document Ranking. Most of the time we supplement the machine’s ranking-based-searches with additional search methods using non-AI based analytics. The particular search supplements we use depends on the relevant documents we find in the ranked document searches. The searches may include some linear review of selected custodians or dates, parametric Boolean keyword searches, similarity searches of all kinds, concept searches. We use every search tool available to us. Again, we call that a multimodal approach.
More on Step Six – Multimodal Review
 As seen all types of search may be conducted in step six to find and batch out documents for human review and machine training. This step thus parallels step two, ECA, except that documents are also found by ranking of probable relevance. This is not yet possible in step two because step five of AI Document Ranking has not yet occurred.
As seen all types of search may be conducted in step six to find and batch out documents for human review and machine training. This step thus parallels step two, ECA, except that documents are also found by ranking of probable relevance. This is not yet possible in step two because step five of AI Document Ranking has not yet occurred.
{kind=link}
It is important to emphasize that although we do searches in step six, steps six and eight are the steps where most of the actual document review is also done, where the documents are seen and classified by human reviewers. Search is used in step six to find the documents that human reviewers should review next. In my experience (and timed tests) the human document review can take as little as one-second per document, assuming your software is good and fast, and it is an obvious document, to as long as a half-hour. The lengthy time to review a document is very rare and only occurs where you have to fast-read a long document to be sure of its classification.
 Step six is the human time intensive part of Predictive Coding 4.0 and can take most of the time in a project. Although when our top team members do a review, such as in TREC, we often spend more than half of the time in the other steps, sometimes considerably more.
Step six is the human time intensive part of Predictive Coding 4.0 and can take most of the time in a project. Although when our top team members do a review, such as in TREC, we often spend more than half of the time in the other steps, sometimes considerably more.
Depending on the classifications during step six Multimodal Review, a document is either set for production, if relevant and not-privileged, or, if coded irrelevant, it is not set for production. If relevant and privileged, then it is logged but not produced. If relevant, not privileged, but confidential for some reason, then it is either redacted and/or specially labeled before production. The special labeling performed is typically to prominently affix the word CONFIDENTIAL on the Tiff image production, or the phrase CONFIDENTIAL – ATTORNEYS EYES ONLY. The actual wording of the legends depends upon the parties confidentiality agreement or court order.
When many redactions are required the total time to review a document can sometimes go way up. The same goes for double and triple checking of privileged documents that are sometimes found in document collections in large numbers. In our TREC and Oracle experiments redactions and privilege double-checking were not required. The time-consuming redactions are usually deferred to step eight – Productions. The equally as time-consuming privilege double-checking efforts can also be deferred to step seven – Quality Assurance, and again for a third-check in step eight.
When reviewing a document not already manually classified, the reviewer is usually presented with a document that the expert searcher running the project has determined is probably relevant. Typically this means that it has higher than a 50% probable relevance ranking. The reviewer may, or may not know the ranking. Whether you disclose that to a reviewer depends on a number of factors. Since I usually only use highly skilled reviewers, I trust them with disclosure. But sometimes you may not want to disclose the ranking.
 During the review many documents predicted to be relevant will not be. The reviewers will code them correctly, as they see them. Our reviewers can and do disagree with and overrule the computer’s predictions. The “Sorry Dave” phrase of the HAL 9000 computer in 2001 Space Odyssey is not possible.
During the review many documents predicted to be relevant will not be. The reviewers will code them correctly, as they see them. Our reviewers can and do disagree with and overrule the computer’s predictions. The “Sorry Dave” phrase of the HAL 9000 computer in 2001 Space Odyssey is not possible.
If a reviewer is in doubt, they consult the SME team. Furthermore, special quality controls in the form of second reviews may be imposed on Man Machine disagreements (the computer says a document should be relevant, but the human reviewer disagrees, and visa versa). They often involve close questions and the ultimate results of the resolved conflicts are typically used in the next round of training.
Sometimes the Machine will predict that a document is relevant, maybe even with 99.9% certainty, even though you have already coded the document as Irrelevant. It does so even though you have already told the Machine to train on it as irrelevant. The Machine does not care about your feelings! Or your authority as chief SME. It considers all of the input, all of your documents input in step four. If the cold, hard logic of its algorithms tells it that a document should be relevant, that is what it will report, in spite of how the document has already been coded. This is an excellent quality control tool.
 I cannot tell you how impressed I was when that first happened to me. I was skeptical, but I went ahead and reread the long document anyway, this time more carefully. Sure enough, I had missed a paragraph near the end that made the document relevant. That was an Eureka moment for me. I have been a strong proponent of predictive coding ever since. Software does not get tried like we do. If the software is good it reads the whole document and is not front-loaded like we usually are. That does not mean Mr. EDR is always right. He is not. Most of the time we reaffirm the original coding, but not without a careful double-check. Usually we can see where the algorithm went wrong. Sometimes that influences our next iteration of step four, selection of training documents.
I cannot tell you how impressed I was when that first happened to me. I was skeptical, but I went ahead and reread the long document anyway, this time more carefully. Sure enough, I had missed a paragraph near the end that made the document relevant. That was an Eureka moment for me. I have been a strong proponent of predictive coding ever since. Software does not get tried like we do. If the software is good it reads the whole document and is not front-loaded like we usually are. That does not mean Mr. EDR is always right. He is not. Most of the time we reaffirm the original coding, but not without a careful double-check. Usually we can see where the algorithm went wrong. Sometimes that influences our next iteration of step four, selection of training documents.
Prediction error type corrections such as this can be the focus of special searches in step six. Most quality version 4.0 software such as Mr. EDR have search functions built-in that are designed to locate all such conflicts between document ranking and classification. Reviewers then review and correct the computer errors by a variety of methods, or change their own prior decisions. This often requires SME team involvement, but only very rarely the senior level SME.
The predictive coding software learns from all of the corrections to its prior predictive rankings. Steps 4, 5 and 6 then repeat as shown in the diagram. This iterative process is a positive feedback loop that continues until the computer predictions are accurate enough to satisfy the proportional demands of the case. In almost all cases that means you have found more than enough of the relevant documents needed to fairly decide the case. In many cases it is far better than that. It is routine for us to attain recall levels of 90% or higher. In a few you may find almost all of the relevant documents.
General Note on Ease of Version 4.0 Methodology and Attorney Empowerment
The machine training process for document review has become easier over the last few years as we have tinkered with and refined the methods. (Tinkering is the original and still only true meaning of hacking. See: HackerLaw.org) At this point of the predictive coding life cycle it is, for example, easier to learn how to do predictive coding than to learn how to do a trial – bench or jury. Interestingly, the most effective instruction method for both legal tasks is similar – second chair apprenticeship, watch and learn. It is the way complex legal practices have always been taught. My team can teach it to any smart tech lawyer by having them second chair a couple of projects.
 It is interesting to note that medicine uses the same method to teach surgeons how to do complex robotic surgery, with a da Vinci surgical system, or the like. Whenever a master surgeon operates with robotics, there are always several doctors watching and assisting, more than are needed. In this photo they are the ones around the patient. The master surgeon who is actually controlling the tiny knifes in the patient is the guy on the far left sitting down with his head in the machine. He is looking at a magnified video picture of what is happening inside the patient’s body and moving the tiny knives around with a joystick.
It is interesting to note that medicine uses the same method to teach surgeons how to do complex robotic surgery, with a da Vinci surgical system, or the like. Whenever a master surgeon operates with robotics, there are always several doctors watching and assisting, more than are needed. In this photo they are the ones around the patient. The master surgeon who is actually controlling the tiny knifes in the patient is the guy on the far left sitting down with his head in the machine. He is looking at a magnified video picture of what is happening inside the patient’s body and moving the tiny knives around with a joystick.
 The hybrid human-robot system augments the human surgeon’s abilities. The surgeon has his hands on the wheel at all times. The other doctors may watch dozens, and if they are younger, maybe even hundreds of surgeries before they are allowed to take control of the joy stick and do the hard stuff themselves. The predictive coding steps four, five and six are far easier than this, besides, if you screw up, nobody dies.
The hybrid human-robot system augments the human surgeon’s abilities. The surgeon has his hands on the wheel at all times. The other doctors may watch dozens, and if they are younger, maybe even hundreds of surgeries before they are allowed to take control of the joy stick and do the hard stuff themselves. The predictive coding steps four, five and six are far easier than this, besides, if you screw up, nobody dies.
More on Step Five – AI Document Ranking
 More discussion on step five may help clarify all three iterated steps. Again, step five is the AI Document Ranking step where the machine takes over and does all of the work. We have also called this the Auto Coding Run because this is where the software’s predictive coding calculations are performed. The software we use is Kroll Ontrack’s Mr. EDR. In the fifth step the software applies all of the training documents we selected in step four to sort the data corpus. In step five the human trainers can take a coffee break while Mr. EDR ranks all of the documents according to probable relevance or other binary choices.
More discussion on step five may help clarify all three iterated steps. Again, step five is the AI Document Ranking step where the machine takes over and does all of the work. We have also called this the Auto Coding Run because this is where the software’s predictive coding calculations are performed. The software we use is Kroll Ontrack’s Mr. EDR. In the fifth step the software applies all of the training documents we selected in step four to sort the data corpus. In step five the human trainers can take a coffee break while Mr. EDR ranks all of the documents according to probable relevance or other binary choices.
 The first time the document ranking algorithm executes is sometimes called the seed set run. The first repetition of the ranking step five is known as the second round of training, the next, the third round, etc. These iterations continue until the training is complete within the proportional constraints of the case. At that point the attorney in charge of the search may declare the search complete and ready for the next quality assurance test in Step Seven. That is called the Stop decision.
The first time the document ranking algorithm executes is sometimes called the seed set run. The first repetition of the ranking step five is known as the second round of training, the next, the third round, etc. These iterations continue until the training is complete within the proportional constraints of the case. At that point the attorney in charge of the search may declare the search complete and ready for the next quality assurance test in Step Seven. That is called the Stop decision.
It is important to understand that this entire eight-step workflow diagram is just a linear two-dimensional representation of Predictive Coding 4.0 for teaching purposes. These step descriptions are also a simplified explanation. Step Five can take place just a soon as a single document has been coded. You could have continuous, ongoing machine training at any time that the humans in charge decide to do so. That is the meaning of out team’s IST (Intelligently Spaced Training), as opposed to Grossman and Cormack’s trademarked CAL method, where the training always goes on without any human choice. This was discussed at length in Part Two of this series.
 We space the training times ourselves to improve our communication and understanding of the software ranking. It helps us to have a better intuitive grasp of the machine processes. (Yes, such a thing is possible.) It allows us to observe for ourselves how a particular document, or usually a particular group of documents, impact the overall ranking. This is an important part of the Hybrid aspects of the Predictive Coding 4.0 Hybrid IST Multimodal Method. We like to be in control and to tell the machine exactly when and if to train, not the other way around. We like to understand what is happening and not just delegate everything to the machine. That is one reason we like to say that although we promote a balanced hybrid-machine process, we are pro-human and tip the scales in our favor.
We space the training times ourselves to improve our communication and understanding of the software ranking. It helps us to have a better intuitive grasp of the machine processes. (Yes, such a thing is possible.) It allows us to observe for ourselves how a particular document, or usually a particular group of documents, impact the overall ranking. This is an important part of the Hybrid aspects of the Predictive Coding 4.0 Hybrid IST Multimodal Method. We like to be in control and to tell the machine exactly when and if to train, not the other way around. We like to understand what is happening and not just delegate everything to the machine. That is one reason we like to say that although we promote a balanced hybrid-machine process, we are pro-human and tip the scales in our favor.
As stated, step five in the eight-step workflow is a purely algorithmic function. The ranking of a few million documents may take as long as an hour, depending on the complexity, the number of documents, software and other factors. Or it might just take a few minutes. This depends on the circumstances and tasks presented.
 All documents selected for training in step four are included in step five computer processing. The software studies the documents marked for training, and then analyzes all of the data uploaded onto the review platform. It then ranks all of the documents according to probable relevance (and, as mentioned according to other binary categories too, such as Highly Relevant and Privilege, and does all of these categories at the same time, but for simplicity purposes here we will just speak of the relevance rankings). It essentially assigns a probable value of from 0.01% to 99.9% probable relevance to each document in the corpus. (Note, some software uses different ranking values, but this is essentially what it is doing.) A value of 99.9% represents the highest probability that the document matches the category trained, such as relevant, or highly relevant, or privileged. A value of 0.01% means no likelihood of matching. A probability ranking of 50% represents equal likelihood, unless there has been careless over-training on irrelevance documents or other errors have been made. In the middle probability rankings the machine is said to be uncertain as to the document classification.
All documents selected for training in step four are included in step five computer processing. The software studies the documents marked for training, and then analyzes all of the data uploaded onto the review platform. It then ranks all of the documents according to probable relevance (and, as mentioned according to other binary categories too, such as Highly Relevant and Privilege, and does all of these categories at the same time, but for simplicity purposes here we will just speak of the relevance rankings). It essentially assigns a probable value of from 0.01% to 99.9% probable relevance to each document in the corpus. (Note, some software uses different ranking values, but this is essentially what it is doing.) A value of 99.9% represents the highest probability that the document matches the category trained, such as relevant, or highly relevant, or privileged. A value of 0.01% means no likelihood of matching. A probability ranking of 50% represents equal likelihood, unless there has been careless over-training on irrelevance documents or other errors have been made. In the middle probability rankings the machine is said to be uncertain as to the document classification.
The first few times the AI-Ranking step is run the software predictions as to document categorization are often wrong, sometimes wildly so. It depends on the kind of search and data involved and on the number of documents already classified and included for training. That is why spot-checking and further training are always needed for predictive coding to work properly. That is why predictive coding is always an iterative process.
Step Seven: ZEN Quality Assurance Tests
There has been no change in this step from Version 3.0 to Version 4.0. If you already know 3.0 well, skip to the conclusion. ZEN here stands for Zero Error Numerics. Predictive Coding 4.0 requires quality control activities in all steps, but the efforts peak in this Step Seven. For more details than provided here on the ZEN approach to quality control in document review see ZeroErrorNumerics.com. In Step Seven a random sample is taken to try to evaluate the recall range attained in the project. The method currently favored is described in detail in Introducing “ei-Recall” – A New Gold Standard for Recall Calculations in Legal Search – Part One, Part Two and Part Three. Also see: In Legal Search Exact Recall Can Never Be Known.
In Step Seven a random sample is taken to try to evaluate the recall range attained in the project. The method currently favored is described in detail in Introducing “ei-Recall” – A New Gold Standard for Recall Calculations in Legal Search – Part One, Part Two and Part Three. Also see: In Legal Search Exact Recall Can Never Be Known.

 The ei-Recall test is based on a random sample of all documents to be excluded from the Final Review for possible production. Unlike the ill-fated control set of Predictive Coding 1.0 methodologies, the sample here is taken at the end of the project. At that time the final relevance conceptions have evolved to their final form and therefore much more accurate projections of recall can be made from the sample. The documents sampled can be based on documents excluded by category prediction (i.e. probable irrelevant) and/or by probable ranking of documents with proportionate cut-offs. The focus is on a search for any false negatives (i.e., relevant documents incorrectly predicted to be irrelevant) that are Highly Relevant or otherwise of significance.
The ei-Recall test is based on a random sample of all documents to be excluded from the Final Review for possible production. Unlike the ill-fated control set of Predictive Coding 1.0 methodologies, the sample here is taken at the end of the project. At that time the final relevance conceptions have evolved to their final form and therefore much more accurate projections of recall can be made from the sample. The documents sampled can be based on documents excluded by category prediction (i.e. probable irrelevant) and/or by probable ranking of documents with proportionate cut-offs. The focus is on a search for any false negatives (i.e., relevant documents incorrectly predicted to be irrelevant) that are Highly Relevant or otherwise of significance.
Total 100% recall of all relevant documents is said by the professors to be scientifically impossible (unless you produce all documents, 0% precision), a myth that the e-Discovery Team shattered in TREC 2015 and again in 2016 in our Total Recall Track experiments. Still, it is very rare, and only happens in relatively simple search and review projects, akin to a straightforward single plaintiff employment case with clear relevance. In any event, total recall of all relevant document is legally unnecessary. Perfection – zero error – is a good goal, but never a legal requirement. The legal requirement is reasonable, proportional efforts to find the ESI that is important to resolve the key disputed issues of fact in the case. The goal is to avoid all false negatives of Highly Relevant documents. If this error is encountered, one or more additional iterations of Steps 4, 5 and 6 are required.
In step seven you also test the decision made at the end of step six to stop the training. This decision is evaluated by the random sample, but determined by a complex variety of factors that can be case specific. Typically it is determined by when the software has attained a highly stratified distribution of documents. See License to Kull: Two-Filter Document Culling and Visualizing Data in a Predictive Coding Project – Part One, Part Two and Part Three, and Introducing a New Website, a New Legal Service, and a New Way of Life / Work; Plus a Postscript on Software Visualization.
When the stratification has stabilized you will see very few new documents found as predicted relevant that have not already been human reviewed and coded as relevant. You essentially run out of documents for step six review. Put another way, your step six no longer uncovers new relevant documents. This exhaustion marker may, in many projects, mean that the rate of newly found documents has slowed, but not stopped entirely. I have written about this quite a bit, primarily in Visualizing Data in a Predictive Coding Project –Part One, Part Two and Part Three. The distribution ranking of documents in a mature project, one that has likely found all relevant documents of interest, will typically look something like the diagram below. We call this the upside down champagne glass with red relevant documents on top and irrelevant on the bottom.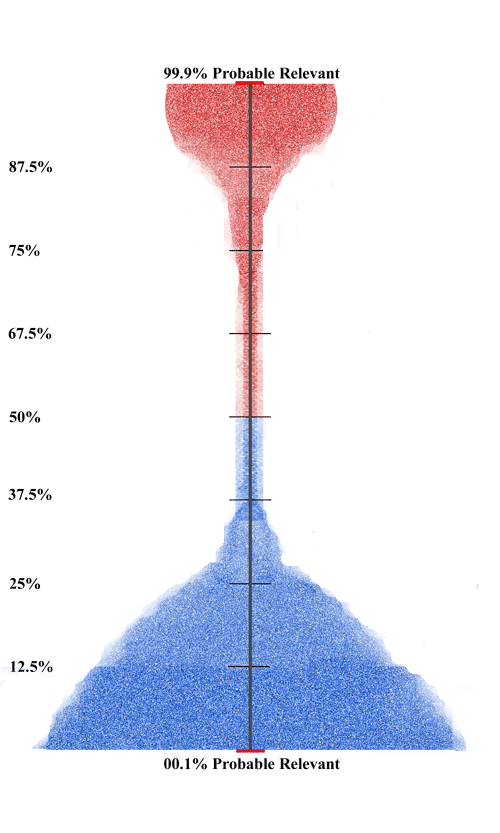
Also see Postscript on Software Visualization where even more dramatic stratifications are encountered and shown.
Another key determinant of when to stop is the cost of further review. Is it worth it to continue on with more iterations of steps four, five and six? See Predictive Coding and the Proportionality Doctrine: a Marriage Made in Big Data, 26 Regent U. Law Review 1 (2013-2014) (note article was based on earlier version 2.0 of our methods where the training was not necessarily continuous). Another criteria in the stop decision is whether you have found the information needed. If so, what is the purpose of continuing a search? Again, the law never requires finding all relevant, only reasonable efforts to find the relevant documents needed to decide the important fact issues in the case. This last point is often overlooked by inexperienced lawyers.
Another important quality control technique, one used throughout a project, is the avoidance of all dual tasking, and learned, focused concentration, a flow-state, like an all-absorbing video game, movie, or a meditation. Here is a short video I did on the importanced of focus in document review.
________
____
 Speaking of relaxed, thought free, flow state, did you know that United States Supreme Court Justice Stephen Breyer is a regular meditator? In a CNN reporter interview in 2011 he said:
Speaking of relaxed, thought free, flow state, did you know that United States Supreme Court Justice Stephen Breyer is a regular meditator? In a CNN reporter interview in 2011 he said:
For 10 or 15 minutes twice a day I sit peacefully. I relax and think about nothing or as little as possible. … And really I started because it’s good for my health. My wife said this would be good for your blood pressure and she was right. It really works. I read once that the practice of law is like attempting to drink water from a fire hose. And if you are under stress, meditation – or whatever you choose to call it – helps. Very often I find myself in circumstances that may be considered stressful, say in oral arguments where I have to concentrate very hard for extended periods. If I come back at lunchtime, I sit for 15 minutes and perhaps another 15 minutes later. Doing this makes me feel more peaceful, focused and better able to do my work.”
 Apparently Steve Breyer also sometimes meditates with friends, including legendary Public Interest Lawyer, Professor and meditation promoter, Charles Halpern. Also see Halpern, Making Waves and Riding the Currents (2008) (his interesting autobiography); Charles Halpern on Empathy, Meditation, Barack Obama, Justice and Law (YouTube Interview in 2011 with interesting thoughts on judicial selection).
Apparently Steve Breyer also sometimes meditates with friends, including legendary Public Interest Lawyer, Professor and meditation promoter, Charles Halpern. Also see Halpern, Making Waves and Riding the Currents (2008) (his interesting autobiography); Charles Halpern on Empathy, Meditation, Barack Obama, Justice and Law (YouTube Interview in 2011 with interesting thoughts on judicial selection).
Document review is not as stressful as a Supreme Court oral argument, but it does go on far longer. Everybody needs to relax with a clear mind, and with focused attention, to attain their peak level of performance. That is the key to all quality control. How you get there is your business. Me, in addition to frequent breaks, I like headphones with music to help me there and help me to stay undistracted, focused. So, sit comfortably, spine erect, and enjoy this moment of ZEN.
_________
For more details on step seven see ZeroErrorNumericcs.com.
____
Step Eight: Phased Production
 There has been no change in this step from Version 3.0 to Version 4.0. If you already know 3.0 well, skip to the conclusion. This last step is where the relevant documents are reviewed again and actually produced. This step is also sometimes referred to as Second Pass Review. Technically, it has nothing to do with a predictive coding protocol, but for completeness sake, we needed to include it in the work flow. This final step may also include document redaction, document labeling, and a host of privilege review issues, including double-checking, triple checking of privilege protocols. These are tedious functions where contract lawyers can be a big help. The actual identification of privileged documents from the relevant should have been part of the prior seven steps.
There has been no change in this step from Version 3.0 to Version 4.0. If you already know 3.0 well, skip to the conclusion. This last step is where the relevant documents are reviewed again and actually produced. This step is also sometimes referred to as Second Pass Review. Technically, it has nothing to do with a predictive coding protocol, but for completeness sake, we needed to include it in the work flow. This final step may also include document redaction, document labeling, and a host of privilege review issues, including double-checking, triple checking of privilege protocols. These are tedious functions where contract lawyers can be a big help. The actual identification of privileged documents from the relevant should have been part of the prior seven steps.
 Always think of production in e-discovery as phased production. Do not think of making one big document dump. That is old-school paper production style. Start with a small test document production after you have a few documents ready. That will get the bugs out of the system for both you, the producer, and also for the receiving party. Make sure it is in the format they need and they know how to open it. Little mistakes and re-dos in a small test production are easy and inexpensive to fix. Getting some documents to the requesting party also gives them something to look at right away. It can buy you time and patience for the remaining productions. It is not uncommon for a large production to be done in five or more smaller stages. There is no limit so long as the time delay is not overly burdensome.
Always think of production in e-discovery as phased production. Do not think of making one big document dump. That is old-school paper production style. Start with a small test document production after you have a few documents ready. That will get the bugs out of the system for both you, the producer, and also for the receiving party. Make sure it is in the format they need and they know how to open it. Little mistakes and re-dos in a small test production are easy and inexpensive to fix. Getting some documents to the requesting party also gives them something to look at right away. It can buy you time and patience for the remaining productions. It is not uncommon for a large production to be done in five or more smaller stages. There is no limit so long as the time delay is not overly burdensome.
Multiple productions are normal and usually welcome by the receiving party. Just be sure to keep them informed of your progress and what remains to be done. Again, step one – Talk – is supposed to continue throughout a project. Furthermore, production of at least some documents can begin very early in the process. It does not have to wait until the last step. It can, for instance, begin while you are still in the iterated steps four, five and six. Just make sure you apply your quality controls and final second pass reviews to all documents produced. Very early productions during the intensive document training stages may help placate a still distrustful requesting party. It allows them to see for themselves that you are in fact using good relevant documents for training and they need not fear GIGO.
 The format of the production should always be a non-issue. This is supposed to be discussed at the initial Rule 26(f) conference. Still, you might want to check again with the requesting party before you select the production format and metadata fields. More and more we see requesting parties that want a PDF format. That should not be a problem. Remember, cooperation should be your benchmark. Courtesy to opposing counsel on these small issues can go a long way. The existence of a clawback agreement and order, including a Rule 502(d) Order, and also a confidentiality agreement and order in some cases, should also be routinely verified before any production is made. This is critical and we cannot over-state its importance. You should never make a production with a 502(d) Order in place, or at least requested from the court. Again, this should be a non-issue. The forms used should be worked out as part of the initial 26(f) meet and greet.
The format of the production should always be a non-issue. This is supposed to be discussed at the initial Rule 26(f) conference. Still, you might want to check again with the requesting party before you select the production format and metadata fields. More and more we see requesting parties that want a PDF format. That should not be a problem. Remember, cooperation should be your benchmark. Courtesy to opposing counsel on these small issues can go a long way. The existence of a clawback agreement and order, including a Rule 502(d) Order, and also a confidentiality agreement and order in some cases, should also be routinely verified before any production is made. This is critical and we cannot over-state its importance. You should never make a production with a 502(d) Order in place, or at least requested from the court. Again, this should be a non-issue. The forms used should be worked out as part of the initial 26(f) meet and greet.
Here is my short, five-minute video summary of this step.
_________
____
After the second pass review is completed there is still one more inspection, a short third pass. Before delivery of electronic documents we perform yet another quality control check. We inspect the media on which the production is made, typically CDs or DVDs, and do a third review of a few of the files themselves. This is an important quality control check, the last one, done just before the documents are delivered to the requesting party. You do not inspect every document, of course, but you do a very limited spot check based on judgmental sampling. You especially want to verify that critical privileged documents you previously identified as privileged have in fact been removed, and that redactions have been properly made. Trust but verify. Also check to verify the order of production is what you expected. You also verify little things that you would do for any paper production, like verify that the document legends and Bates stamping are done the way you wanted. Even the best vendors sometimes make mistakes, and so too does your team.
You need to be very diligent in protecting your client’s confidential information. It is an ethical duty of all lawyers. It weighs heavily in what we consider a properly balanced, proportional approach. That is why you must take time to do the Production step correctly and should never let yourself be rushed. Here is a short video on my philosophy of proportional balance in legal services, including a discussion of the mentioned final spot check of production CDs.
______
____
The final work included here is to prepare a privilege log. All good vendor review software should make this into a semi-automated process, and thus slightly less tedious. The logging is typically delayed until after production. Check with local rules on this and talk to the requesting party to let them know it is coming.
 One final comment on the e-Discovery Team’s methods. We are very hyper about time management throughout a project, but especially in the last step. Never put yourself in a time bind. Be Proactive. Stay ahead of the curve. This is important for the entire project, but especially in the last step. Mistakes are made when you have to rush to meet tight production deadlines. You must avoid this. Ask for an extension and motion the court if you have to. Better that than make a serious error. Again, produce what you have ready and come back for the rest.
One final comment on the e-Discovery Team’s methods. We are very hyper about time management throughout a project, but especially in the last step. Never put yourself in a time bind. Be Proactive. Stay ahead of the curve. This is important for the entire project, but especially in the last step. Mistakes are made when you have to rush to meet tight production deadlines. You must avoid this. Ask for an extension and motion the court if you have to. Better that than make a serious error. Again, produce what you have ready and come back for the rest.
Here is a video I prepared on the importance of good time management to any document review project.
__________
____
Conclusion
 Every search expert I have ever talked to agrees that it is just good common sense to find relevant information by using every search method that you can. It makes no sense to limit yourself to any one search method. They agree that multimodal is the way to go, even if they do not use that language (after all, I did make up the term), and even if they do not publicly promote that protocol (they may be promoting software or a method that does not use all methods). All of the scientists I have spoken with about search also all agree that effective text retrieval should use some type of active machine learning (what we in the legal world calls predictive coding), and not just rely on the old search methods of keyword, similarity and concept type analytics. The combined multimodal use of the old and new methods is the way to go. This hybrid approach exemplifies man and machine working together in an active partnership, a union where the machine augments human search abilities, not replaces them.
Every search expert I have ever talked to agrees that it is just good common sense to find relevant information by using every search method that you can. It makes no sense to limit yourself to any one search method. They agree that multimodal is the way to go, even if they do not use that language (after all, I did make up the term), and even if they do not publicly promote that protocol (they may be promoting software or a method that does not use all methods). All of the scientists I have spoken with about search also all agree that effective text retrieval should use some type of active machine learning (what we in the legal world calls predictive coding), and not just rely on the old search methods of keyword, similarity and concept type analytics. The combined multimodal use of the old and new methods is the way to go. This hybrid approach exemplifies man and machine working together in an active partnership, a union where the machine augments human search abilities, not replaces them.
The Hybrid IST Multimodal Predictive Coding 4.0 approach described here is still not followed by most e-discovery vendors, including several prominent software vendors. Instead, they rely on just one or two methods to the exclusion of the others. For instance, they may rely entirely on machine selected documents for training, or even worse, rely entirely on random selected documents. They do so to try to keep it simple they say. It may be simple, but the power and speed given up for that simplicity is not worth it. Others have all types of search, including concept search and related analytics, but they still do not have active machine learning. You probably know who they are by now. This problem will probably be solved soon, so I will not belabor the point.
 The users of the old software and old-fashioned methods will never know the genuine thrill known by most search lawyers using AI enhanced methods like Predictive Coding 4.0. The good times roll when you see that the AI you have been training has absorbed your lessons. When you see the advanced intelligence that you helped create kick-in to complete the project for you. When you see your work finished in record time and with record results. It is sometimes amazing to see the AI find documents that you know you would never have found on your own. Predictive coding AI in superhero mode can be exciting to watch.
The users of the old software and old-fashioned methods will never know the genuine thrill known by most search lawyers using AI enhanced methods like Predictive Coding 4.0. The good times roll when you see that the AI you have been training has absorbed your lessons. When you see the advanced intelligence that you helped create kick-in to complete the project for you. When you see your work finished in record time and with record results. It is sometimes amazing to see the AI find documents that you know you would never have found on your own. Predictive coding AI in superhero mode can be exciting to watch.
My entire e-Discovery Team had a great time watching Mr. EDR do his thing in the thirty Recall Track TREC Topics in 2015. We would sometimes be lost, and not even understand what the search was for anymore. But Mr. EDR knew, he saw the patterns hidden to us mere mortals. In those cases we would just sit back and let him do the driving, occasionally cheering him on. That is when my Team decided to give Mr. EDR a cape and superhero status. He never let us down. It is a great feeling to see your own intelligence augmented and save you like that. It was truly a hybrid human-machine partnership at its best. I hope you get the opportunity soon to see this in action for yourself.
 Our experience in TREC 2016 was very different, but still made us glad to have Mr. EDR around. This time most of the search projects were simple enough to find the relevant documents without his predictive coding superpowers. As mentioned, we verified in test conditions that the skilled use of Tested, Parametric Boolean Keyword Search is very powerful. Keyword search, when done by experts using hands-on testing, and not simply blind Go Fish keyword guessing, is very effective. We proved that in the 2016 TREC search projects. As explained in Part Four of this series, the keyword appropriate projects are those where the data is simple, the target is clear and the SME is good. Still, even then, Mr. EDR was helpful as a quality control assistant. He verified that we had found all of the relevant documents.
Our experience in TREC 2016 was very different, but still made us glad to have Mr. EDR around. This time most of the search projects were simple enough to find the relevant documents without his predictive coding superpowers. As mentioned, we verified in test conditions that the skilled use of Tested, Parametric Boolean Keyword Search is very powerful. Keyword search, when done by experts using hands-on testing, and not simply blind Go Fish keyword guessing, is very effective. We proved that in the 2016 TREC search projects. As explained in Part Four of this series, the keyword appropriate projects are those where the data is simple, the target is clear and the SME is good. Still, even then, Mr. EDR was helpful as a quality control assistant. He verified that we had found all of the relevant documents.
Bottom line for the e-Discovery Team at this time is that the use of all methods is appropriate in all projects, even in simple searches where predictive coding is not needed to find all relevant documents. You can still use active machine learning in simple projects as a way to verify the effectiveness of your keyword and other searches. It may not be necessary in the simple cases, but it is still a good search to add to your tool chest. When the added expense is justified and proportional, the use of predictive coding can help assure you, and the other side, that a high quality effort has been made.
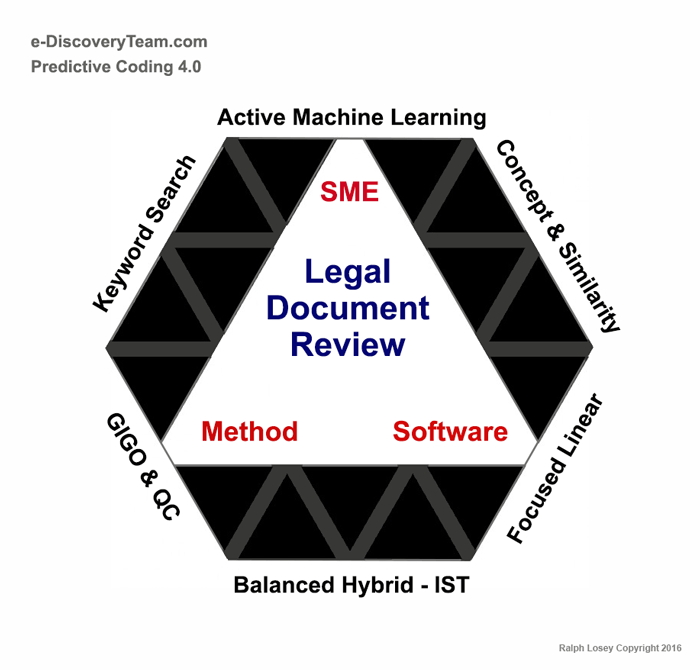
The multimodal approach is the most effective method of search. All search tools should be used, not only Balanced Hybrid – IST active machine learning searches, but also concept and similarity searches, keyword search and, in some instances, even focused linear review. By using some or all search methods, depending on the project and challenges presented, you can maximize recall (the truth, the whole truth) and precision (nothing but the truth). That is the goal of search: effective and efficient. Along the way we must exercise caution to avoid the errors of Garbage in, Garbage Out, that can be caused by poor SMEs. We must also guard against the errors and omissions, low recall and low precision, that can arise from substandard software and methods. In our view the software must be capable of all search methods, including active machine learning, and the methods used should too.
Discover more from eDiscovery Team
Subscribe to get the latest posts sent to your email.