This is the third installment of my lengthy article explaining the e-Discovery Team’s latest enhancements to electronic document review using Predictive Coding. Here are Parts One and Two. This series explains the nine insights (6+3) behind the latest upgrade to version 4.0 and the slight revisions these insights triggered to the eight-step workflow. This is all summarized by the diagram below, which you may freely copy and use if you make no changes.
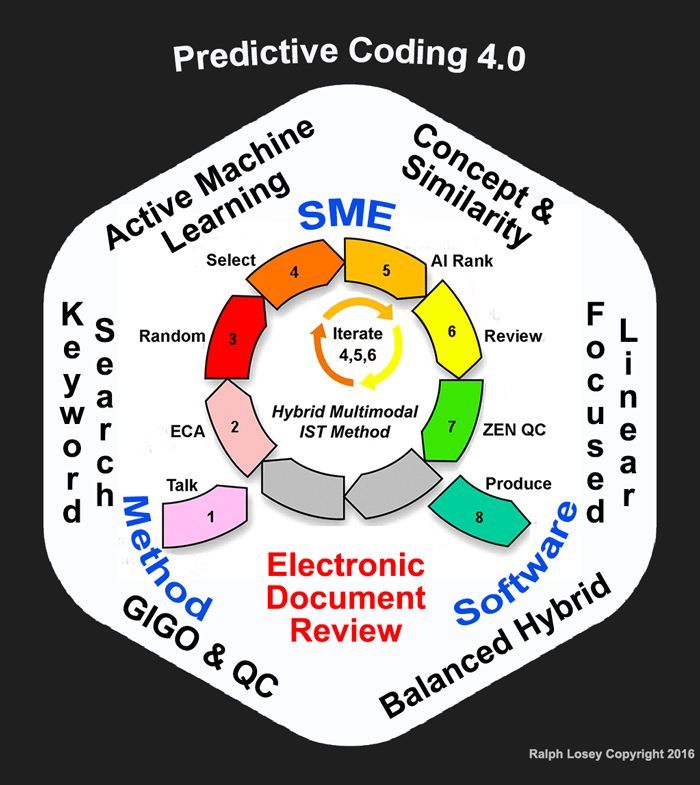
To summarize this series explains the seventeen points, listed below, where the first nine are insights and the last eight are workflow steps:
- Active Machine Learning (aka Predictive Coding)
- Concept & Similarity Searches (aka Passive Learning)
- Keyword Search (tested, Boolean, parametric)
- Focused Linear Search (key dates & people)
- GIGO & QC (Garbage In, Garbage Out) (Quality Control)
- Balanced Hybrid (man-machine balance with IST)
- SME (Subject Matter Expert, typically trial counsel)
- Method (for electronic document review)
- Software (for electronic document review)
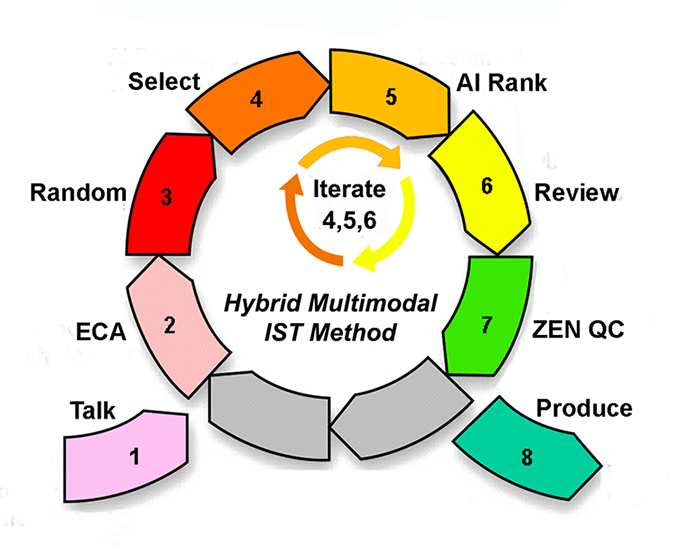
- Talk (step 1 – relevance dialogues)
- ECA (step 2 – early case assessment using all methods)
- Random (step 3 – prevalence range estimate, not control sets)
- Select (step 4 – choose documents for training machine)
- AI Rank (step 5 – machine ranks documents according to probabilities)
- Review (step 6 – attorneys review and code documents)
- Zen QC (step 7 – Zero Error Numerics Quality Control procedures)
- Produce (step 8 – production of relevant, non-privileged documents)
So far in Part One of this series we explained how these insights came about and provided other general background. In Part Two we explained the first of the nine insights, Active Machine Learning, including the method of double-loop learning. In the process we introduced three more insights, Balanced Hybrid, Concept & Similarity Searches, and Software. For continuity purposes we will address Balanced Hybrid next. (I had hoped to cover many more of the seventeen in this third installment, but turns out it all takes more words than I thought.)
Balanced Hybrid
Using Intelligently Spaced Training – IST™
The Balanced Hybrid insight is complementary to Active Machine Learning. It has to do with the relationship between the human training the machine and the machine itself. The name itself says it all, namely that is it balanced. We rely on both software and skilled attorneys using the software.

We advocate reliance on the machine after it become trained, after it starts to understand your conception of relevance. At that point we find it very helpful to rely on what the machine has determined to be the documents most likely to be relevant. We have found it is a good way to improve precision in the sixth step of our 8-step document review methodology shown below. We generally use a balanced approach where we start off relying more on human selections of documents for training based on their knowledge of the case and other search selection processes, such as keyword or passive machine learning, a/k/a concept search. See steps 2 and 4 of our 8-step method – ECA and Select. Then we switch to relying more on the machine as it’s understanding catches one. See steps 4 and 5 – Select and AI Rank. It is usually balanced throughout a project with equal weight given to the human trainer, typically a skilled attorney, and the machine, a predictive coding algorithm of some time, typically logistic regression or support vector.
{kind=link}
Unlike other methods of Active Machine Learning we do not completely turn over to the machine all decisions as to what documents to review next. We look to the machine for guidance as to what documents should be reviewed next, but it is always just guidance. We never completely abdicate control over to the machine. I have gone into this before at some length in my article Why the ‘Google Car’ Has No Place in Legal Search. In this article I cautioned against over reliance on fully automated methods of active machine learning. Our method is designed to empower the humans in control, the skilled attorneys. Thus although our Hybrid method is generally balanced, our scale tips slightly in favor of humans, the team of attorneys who run the document review. We favor humans. So while we like our software very much, and have even named it Mr. EDR, we have an unabashed favoritism for humans. More on this at the conclusion of the Balanced Hybrid section of this article.

Three Factors That Influence the Hybrid Balance
We have shared the previously described hybrid insights before in earlier e-Discovery Team writings on predictive coding. The new insights on Balanced Hybrid are described in the rest of this segment. Again, they are not entirely new either. They represent more of a deepening of understanding and should be familiar to most document review experts. First, we have gained better insight into when and why the Balanced Hybrid approach should be tipped one way or another towards greater reliance on humans or machine. We see three factors that influence our decision.
- On some projects your precision and recall improves by putting greater reliance of the AI, on the machine. These are typically projects where one or more of the following conditions exist:
* the data itself is very complex and difficult to work with, such as specialized forum discussions; or,
* the search target is ill-defined, i.w. – no one is really sure what they are looking for; or,
* the Subject Matter Expert (SME) making final determinations on relevance has limited experience and expertise.
 2. On some projects your precision and recall improves by putting even greater reliance of the humans, on the skilled attorneys working with the machine. These are typically projects where the converse of one or more of the three criteria above are present:
2. On some projects your precision and recall improves by putting even greater reliance of the humans, on the skilled attorneys working with the machine. These are typically projects where the converse of one or more of the three criteria above are present:
* the data itself is fairly simple and easy to work with, such as a disciplined email user (note this has little or nothing to do with data volume) or,
* the search target is well-defined, i.w. there are clearly defined search requests and everyone is on the same page as to what they are looking for; or,
* the Subject Matter Expert (SME) making final determinations on relevance has extensive experience and expertise.
What was somewhat surprising from our 2016 TREC research is how one-sided you can go on the Human side of the equation and still attain near perfect recall and precision. The Jeb Bush email underlying all thirty of our topics in TREC Total Recall Track 2016 is, at this point, well-known to us. It is fairly simple and easy to work with. Although the spelling of the thousands of constituents who wrote to Jeb Bush was atrocious (far worse than general corporate email, except maybe construction company emails), Jeb’s use of the email was fairly disciplined and predictable. As a Florida native and lawyer who lived through the Jeb Bush era, and was generally familiar with all of the issues, and have become very familiar with his email, I have become a good SME, and, to a somewhat lesser extent, so has my whole team. (I did all ten of the Bush Topics in 2015 and another ten in 2016.) Also, we had fairly well-defined, simple search goals in most of the topics.
 For these reasons in many of these 2016 TREC document review projects the role of the machine and machine ranking became fairly small. In some that I handled it was reduced to a quality control, quality assurance method. The machine would pick up and catch a few documents that the lawyers alone had missed, but only a few. The machine thus had a slight impact on improved recall, but not much effect at all on precision, which was anyway very high. (More on this experience with easy search topics later in this essay when we talk about our Keyword Search insights.)
For these reasons in many of these 2016 TREC document review projects the role of the machine and machine ranking became fairly small. In some that I handled it was reduced to a quality control, quality assurance method. The machine would pick up and catch a few documents that the lawyers alone had missed, but only a few. The machine thus had a slight impact on improved recall, but not much effect at all on precision, which was anyway very high. (More on this experience with easy search topics later in this essay when we talk about our Keyword Search insights.)
On a few of the 2016 TREC Topics the search targets were not well-defined. On these Topics our SME skills were necessarily minimized. Thus in these few Topics, even though the data itself was simple, we had to put greater reliance on the machine (in our case Mr. EDR) than on the attorney reviewers.
It bears repeating that the volume of emails has nothing to do with the ease or difficulty of the review project. This is a secondary question and is not dispositive as to how much weight you need to give to machine ranking. (Volume size may, however, have a big impact on project duration.)
We use IST, Not CAL
 Another insight in Balanced Hybrid in our new version 4.0 of Predictive Coding is what we call Intelligently Spaced Training, or IST™. See Part Two of this series for more detail on IST. We now use the term IST, instead of CAL, for two reasons:
Another insight in Balanced Hybrid in our new version 4.0 of Predictive Coding is what we call Intelligently Spaced Training, or IST™. See Part Two of this series for more detail on IST. We now use the term IST, instead of CAL, for two reasons:
1. Our previous use of the term CAL was only to refer to the fact that our method of training was continuous, in that it continued and was ongoing throughout a document review project. The term CAL has come to mean much more than that, as will be explained, and thus our continued use of the term may cause confusion.
2. Trademark rights have recently been asserted by Professors Grossman and Cormack, who originated this acronym CAL. As they have refined the use of the mark it now not only stands for Continuous Active Learning throughout a project, but also stands for a particular method of training that only uses the highest ranked documents.
Under the Grossman-Cormack CAL method the machine training continues throughout the document review project, as it does under our IST method, but there the similarities end. Under their CAL method of predictive coding the machine trains automatically as soon as a new document is coded. Further, the document or documents are selected by the software itself. It is a fully automatic process. The only role of the human is to say yes or no as to relevance of the document. The human does not select which document or documents to review next to say yes or no to. That is controlled by the algorithm, the machine. Their software always selects and presents for review the document or documents that it considers to have the highest probability of relevance, which have, of course, not already been coded.
The CAL method is only hybrid, like the e-Discovery Team method, in the sense of man and machine working together. But, from our perspective, it is not balanced. In fact, from our perspective the CAL method is way out of balance in favor of the machine. This may be the whole point of their method, to limit the human role as much as possible. The attorney has no role to play at all in selecting what document to review next and it does not matter if the attorney understands the training process. Personally, we do not like that. We want to be in charge and fully engaged throughout. We want the computer to be our tool, not our master.

Under our IST method the attorney chooses what documents to review next. We do not need the computer’s permission. We decide whether to accept a batch of high-ranking documents from the machine, or not. The attorney may instead find documents that they think are relevant from other methods. Even if the high ranked method of selection of training documents is used, the attorney decides the number of such documents to use and whether to supplement the machine selection with other training documents.
In fact, the only thing in common between IST and CAL is that both process continue throughout the life of a document review project and both are concerned with the Stop decision (when to when to stop the training and project). Under both methods after the Stopping point no new documents are selected for review and production. Instead, quality assurance methods that include sampling reviews are begun. If the quality assurance tests affirm that the decision to stop review was reasonable, then the project concludes. If they fail, more training and review are initiated.
 Aside from the differences in document selection between CAL and IST, the primary difference is that under IST the attorney decides when to train. The training does not occur automatically after each document, or specified number of documents, as in CAL, or at certain arbitrary time periods, as is common with other software. In the e-Discovery Team method of IST, which, again, stands for Intelligently Spaced (or staggered) Training, the attorney in charge decide when to train. We control the clock, the clock does not control us. The machine does not decide. Attorneys use their own intelligence to decide when to train the machine.
Aside from the differences in document selection between CAL and IST, the primary difference is that under IST the attorney decides when to train. The training does not occur automatically after each document, or specified number of documents, as in CAL, or at certain arbitrary time periods, as is common with other software. In the e-Discovery Team method of IST, which, again, stands for Intelligently Spaced (or staggered) Training, the attorney in charge decide when to train. We control the clock, the clock does not control us. The machine does not decide. Attorneys use their own intelligence to decide when to train the machine.
This timing control allows the attorney to observe the impact of the training on the machine. It is designed to improve the communication between man and machine. That is the double-loop learning process described in Part Two as part of the insights into Active Machine Learning. The attorney trains the machine and the machine is observed so that the trainer can learn how well the machine is doing. The attorney can learn what aspects of the relevance rule have been understood and what aspects still need improvement. Based on this student to teacher feedback the teacher is able to custom the next rounds of training to fit the needs of the student. This maximizes efficiency and effectiveness and is the essence of double-loop learning.
Pro Human Approach to Hybrid Man-Machine Partnership
 To wrap up the new Balanced Hybrid insights we would like to point out that our terminology speaks of Training– IST – rather than Learning – CAL. We do this intentionally because training is consistent with our human perspective. That is our perspective whereas the perspective of the machine is to learn. The attorney trains and the machine learns. We favor humans. Our goal is empowerment of attorney search experts to find the truth (relevance), the whole truth (recall) and nothing but the truth (precision). Our goal is to enhance human intelligence with artificial intelligence. Thus we prefer a Balanced Hybrid approach with IST and not CAL.
To wrap up the new Balanced Hybrid insights we would like to point out that our terminology speaks of Training– IST – rather than Learning – CAL. We do this intentionally because training is consistent with our human perspective. That is our perspective whereas the perspective of the machine is to learn. The attorney trains and the machine learns. We favor humans. Our goal is empowerment of attorney search experts to find the truth (relevance), the whole truth (recall) and nothing but the truth (precision). Our goal is to enhance human intelligence with artificial intelligence. Thus we prefer a Balanced Hybrid approach with IST and not CAL.
This is not to say the CAL approach of Grossman and Cormack is not good and does not work. It appears to work fine. It is just a tad too boring for us and sometimes too slow. Overall we think it is less efficient and may sometimes even be less effective than our Hybrid Multimodal method. But, even though it is not for us, it may be well be great for many beginners. It is very easy and simple to operate. From language in the Grossman Cormack patents that appears to be what they are going for – simplicity and ease of use. They have that and a growing body of evidence that it works. We wish them well, and also their software and CAL methodology.

I expect Grossman and Cormack, and others in the pro-machine camp, to move beyond the advantages of simplicity and also argue safety issues. I expect them to argue that it is safer to rely on AI because a machine is more reliable than a human, in the same way that Google’s self-driving car is safer and more reliable than a human driven car. Of course, unlike driving a car, they still need a human, an attorney, to decide yes or no on relevance, and so they are stuck with human reviewers. They are stuck with a least a partial Hybrid method, albeit one favoring as much as possible the machine side of the partnership. We do not think the pro-machine approach will work with attorneys, nor should it. We think that only an unabashedly pro-human approach like ours is likely to be widely adopted in the legal marketplace.
The goal of the pro-machine approach of Professors Cormack and Grossman, and others, is to minimize human judgments, no matter how skilled, and thereby reduce as much as possible the influence of human error and outright fraud. This is a part of a larger debate in the technology world. We respectfully disagree with this approach, at least in so far as legal document review is concerned. (Personally I tend to agree with it in so far as the driving of automobiles is concerned.) We instead seek enhancement and empowerment of attorneys by technology, including quality controls and fraud detection. See Why the ‘Google Car’ Has No Place in Legal Search. No doubt you will be hearing more about this interesting debate in the coming years. It may well have a significant impact on technology in the law, the quality of justice, and the future of lawyer employment.

To be continued …
Discover more from eDiscovery Team
Subscribe to get the latest posts sent to your email.
Ralph,
Our CAL method permits the various kinds of human input that you advocate in your blogpost. CAL is available in standard transmission, automatic, and autopilot models. It is only the autopilot model, “AutoTAR,” that is featured in our on-line demo at cormack.uwaterloo.ca/cal. Those who prefer to shift gears or disable cruise control can certainly do so and still use CAL.
The method you describe in your post is remarkably similar to the original method we first demonstrated in 2009, and named “CAL” in 2013 to distinguish it from other forms of TAR. See Gordon V. Cormack and Mona Mojdeh, Machine Learning for Information Retrieval: TREC 2009 Web, Relevance Feedback and Legal Tracks, at https://goo.gl/XZWdTU:
“The logistic regression spam filter yields an estimate of the log-odds that each document is relevant. We constructed a very efficient user interface to review documents selected by this relevance score. The primary approach was to examine unjudged documents in decreasing order of score [ . . . ] We also examined documents in different orders; in particular, we examined documents with high scores that were marked ‘not relevant’ and documents with low scores that were marked ‘relevant’. From time to time we recomputed the scores by running training the filter on the augmented relevance assessments. From time to time we revisited the interactive search and judging system, to augment or correct the relevance assessments as new information came to light.”
GVC
Your description sounds like Hybrid Multimodal to me. It also sounds like you intelligently designed your own training points and thus were more like my current method – IST – and not like what you are currently calling CAL. So not so very different is an encouraging reaction for me. Thank you for your comments.
[…] enhancements to electronic document review using Predictive Coding. Here are Parts One, Two and Three. This series explains the nine insights behind the latest upgrade to version 4.0 and the slight […]
[…] enhancements to electronic document review using Predictive Coding. Here are Parts One, Two, Three and Four. This series explains the nine insights behind the latest upgrade to version 4.0 and the […]
[…] enhancements to electronic document review using Predictive Coding. Here are Parts One, Two, Three, Four and Five. This series explains the nine insights behind the latest upgrade to version 4.0 […]
[…] enhancements to electronic document review using Predictive Coding. Here are Parts One, Two, Three, Four, Five and Six. This series explains the nine insights behind the latest upgrade to version […]
[…] enhancements to electronic document review using Predictive Coding. Here are Parts One, Two, Three, Four, Five and Six. This series explains the nine insights behind the latest upgrade to version […]