 This is the fourth installment of the article explaining the e-Discovery Team’s latest enhancements to electronic document review using Predictive Coding. Here are Parts One, Two and Three. This series explains the nine insights behind the latest upgrade to version 4.0 and the slight revisions these insights triggered to the eight-step workflow. In Part Two we covered the premier search method, Active Machine Learning (aka Predictive Coding). In this installment we will cover our insights into the remaining four basic search methods: Concept Searches (Passive, Unsupervised Learning); Similarity Searches (Families and near Duplication); Keyword Searches (tested, Boolean, parametric); and Focused Linear Search (key dates & people). The five search types are all in our newly revised Search Pyramid shown below (last revised in 2012).
This is the fourth installment of the article explaining the e-Discovery Team’s latest enhancements to electronic document review using Predictive Coding. Here are Parts One, Two and Three. This series explains the nine insights behind the latest upgrade to version 4.0 and the slight revisions these insights triggered to the eight-step workflow. In Part Two we covered the premier search method, Active Machine Learning (aka Predictive Coding). In this installment we will cover our insights into the remaining four basic search methods: Concept Searches (Passive, Unsupervised Learning); Similarity Searches (Families and near Duplication); Keyword Searches (tested, Boolean, parametric); and Focused Linear Search (key dates & people). The five search types are all in our newly revised Search Pyramid shown below (last revised in 2012).

Concept Searches – aka Passive Learning
 As discussed inPart Two of this series, the e-discovery search software company, Engenium was one of the first to use Passive Machine Learning techniques. Shortly after the turn of the century, the early 2000s, Engenium began to market what later become known as Concept Searches. They were supposed to be a major improvement over then dominant Keyword Search. Kroll Ontrack bought Engenium in 2006 and acquired its patent rights to concept search. These software enhancements were taken out of the e-discovery market and removed from all competitor software, except Kroll Ontrack. The same thing happened in 2014 when Microsoft bought Equivio. See e-Discovery Industry Reaction to Microsoft’s Offer to Purchase Equivio for $200 Million – Part One and Part Two. We have yet to see what Microsoft will do with it. All we know for sure is its predictive coding add-on for Relativity is no longer available.
As discussed inPart Two of this series, the e-discovery search software company, Engenium was one of the first to use Passive Machine Learning techniques. Shortly after the turn of the century, the early 2000s, Engenium began to market what later become known as Concept Searches. They were supposed to be a major improvement over then dominant Keyword Search. Kroll Ontrack bought Engenium in 2006 and acquired its patent rights to concept search. These software enhancements were taken out of the e-discovery market and removed from all competitor software, except Kroll Ontrack. The same thing happened in 2014 when Microsoft bought Equivio. See e-Discovery Industry Reaction to Microsoft’s Offer to Purchase Equivio for $200 Million – Part One and Part Two. We have yet to see what Microsoft will do with it. All we know for sure is its predictive coding add-on for Relativity is no longer available.
 David Chaplin, who founded Engeniun in 1998, and sold it in 2006, became Kroll Ontrack’s VP of Advanced Search Technologies from 2006-2009. He is now the CEO of two Digital Marketing Service and Technology (SEO) companies, Atruik and SearchDex. Other vendors emerged at the time to try to stay competitive with the search capabilities of Kroll Ontrack’s document review platform. They included Clearwell, Cataphora, Autonomy, Equivio, Recommind, Ringtail, Catalyst, and Content Analyst. Most of these companies went the way of Equivo and are now ghosts, gone from the e-discovery market. There are a few notable exceptions, including Catalyst, who participated in TREC with us in 2015 and 2016.
David Chaplin, who founded Engeniun in 1998, and sold it in 2006, became Kroll Ontrack’s VP of Advanced Search Technologies from 2006-2009. He is now the CEO of two Digital Marketing Service and Technology (SEO) companies, Atruik and SearchDex. Other vendors emerged at the time to try to stay competitive with the search capabilities of Kroll Ontrack’s document review platform. They included Clearwell, Cataphora, Autonomy, Equivio, Recommind, Ringtail, Catalyst, and Content Analyst. Most of these companies went the way of Equivo and are now ghosts, gone from the e-discovery market. There are a few notable exceptions, including Catalyst, who participated in TREC with us in 2015 and 2016.
As described in Part Two of this series the so-called Concept Searches all relied on passive machine learning that did not depend on training or active instruction by any human (aka supervised learning). It was all done automatically by computer study and analysis of the data alone, including semantic analysis of the language contained in documents. That meant you did not have to rely on keywords alone, but could state your searches in conceptual terms. The below is a screen-shot of one example of concept search interface using Kroll Ontrack’s EDR software.

For a good description of these admittedly powerful, albeit now somewhat dated search tools (at least compared to active machine learning), see the afore-cited article by D4’s Tom Groom, The Three Groups of Discovery Analytics and When to Apply Them. The article refers to Concept Search as Conceptual Analytics, and is described as follows:
Conceptual analytics takes a semantic approach to explore the conceptual content, or meaning of the content within the data. Approaches such as Clustering, Categorization, Conceptual Search, Keyword Expansion, Themes & Ideas, Intelligent Folders, etc. are dependent on technology that builds and then applies a conceptual index of the data for analysis.
Search experts and information scientists know that active machine learning, also called supervised machine learning, was the next big step in search after concept searches, including clustering, which are, in programming language, also known as passive or unsupervised machine learning. The below instructional chart by Hackbright Academy sets forth key difference between supervised learning (predictive coding) and unsupervised or passive learning (analytics, aka concept search).
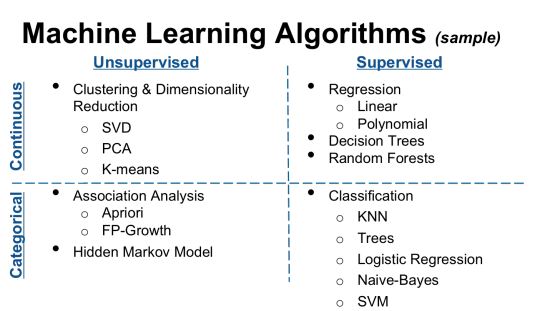
 It is usually worthwhile to spend some time using concept search to speed up the search and review of electronic documents. We have found it to be of only modest value in simple search projects, with greater value added in more complex projects, especially where data is very complex. Still, in all projects, simple or complex, the use of Concept Search features such as document Clustering, Categorization, Keyword Expansion, Themes & Ideas are at least somewhat helpful. They are especially helpful in finding new keywords to try out, including wild-card stemming searches with instant results and data groupings.
It is usually worthwhile to spend some time using concept search to speed up the search and review of electronic documents. We have found it to be of only modest value in simple search projects, with greater value added in more complex projects, especially where data is very complex. Still, in all projects, simple or complex, the use of Concept Search features such as document Clustering, Categorization, Keyword Expansion, Themes & Ideas are at least somewhat helpful. They are especially helpful in finding new keywords to try out, including wild-card stemming searches with instant results and data groupings.
In simple projects you may not need to spend much time with these kind of searches. We find that an expenditure of at least thirty minutes at the beginning of a search is cost-effective in all projects, even simple ones. In more complex projects it may be necessary to spend much more time on these kinds of features.
Passive, unsupervised machine learning is a good way to be introduced to the type of data you are dealing with, especially if you have not worked with the client data before. In TREC Total Recall 2015 and 2016, where we were working with the same datasets, our use of these searches diminished as our familiarity with the datasets grew. They can also help in projects where the search target in not well-defined. There the data itself helps focus the target. It is helpful in this kind of sloppy, I’ll know it when I see it type of approach. That usually indicates a failure of both target identification and SME guidance. Even with simple data you will want to use passive machine learning in those circumstances
Similarity Searches – Families and Near Duplication
 In Tom Groom‘s, article, The Three Groups of Discovery Analytics and When to Apply Them, he refers to Similarity Searches as Structured Analytics, which he explains as follows:
In Tom Groom‘s, article, The Three Groups of Discovery Analytics and When to Apply Them, he refers to Similarity Searches as Structured Analytics, which he explains as follows:
Structured analytics deals with textual similarity and is based on syntactic approaches that utilize character organization in the data as the foundation for the analysis. The goal is to provide better group identification and sorting. One primary example of structured analytics for eDiscovery is Email Thread detection where analytics organizes the various email messages between multiple people into one conversation. Another primary example is Near Duplicate detection where analytics identifies documents with like text that can be then used for various useful workflows.
These methods can always improve efficiency of a human reviewer’s efforts. It makes it easier and faster for human reviewers to put documents in context. It also helps a reviewer minimize repeat readings of the same language or same document. The near duplicate clustering of documents can significantly speed up review. In some corporate email collections the use of Email Thread detection can also be very useful. The idea is to read the last email first, or read in chronological order from the bottom of the email chain to the top. The ability to instantly see on demand the parents and children of email collections can also speed up review and improve context comprehension.

All of these Similarity Searches are less powerful than Concept Search, but tend to be of even more value than Concept Search in simple to intermediate complexity cases. In most simple or medium complex projects one to three hours are typically used with these kind of software features. Also, for this type of search the volume of documents is important. The larger the data set, especially the larger the number of relevant documents located, the greater the value of these searches.
Keyword Searches – Tested, Boolean, Parametric
 In my perspective as an attorney in private practice specializing in e-discovery and supervising the e-discovery work in a firm with 800 attorneys, almost all of whom do employment litigation, I have a good view of what is happening in the U.S.. We have over fifty offices and all of them at one point or another have some kind of e-discovery issue. All of them deal with opposing counsel who are sometimes mired in keywords, thinking it is the end-all and be-all of legal search. Moreover, they usually want to go about doing it without any testing. Instead, they think they are geniuses who can just dream up good searches out of thin air. They think because they know what their legal complaint is about, they know what keywords will be used by the witnesses in all relevant documents. I cannot tell you how many times I see the word “complaint” in their keyword list. The guessing involved reminds me of the child’s game of Go Fish.
In my perspective as an attorney in private practice specializing in e-discovery and supervising the e-discovery work in a firm with 800 attorneys, almost all of whom do employment litigation, I have a good view of what is happening in the U.S.. We have over fifty offices and all of them at one point or another have some kind of e-discovery issue. All of them deal with opposing counsel who are sometimes mired in keywords, thinking it is the end-all and be-all of legal search. Moreover, they usually want to go about doing it without any testing. Instead, they think they are geniuses who can just dream up good searches out of thin air. They think because they know what their legal complaint is about, they know what keywords will be used by the witnesses in all relevant documents. I cannot tell you how many times I see the word “complaint” in their keyword list. The guessing involved reminds me of the child’s game of Go Fish.
I wrote about this in 2009 and the phrase caught on after Judge Peck and others started citing to this article, which later became a chapter in my book, Adventures in Electronic Discovery, 209-211 (West 2011). The Go Fish analogy appears to be the third most popular reference in predictive coding case-law, after the huge, Da Silva Moore case in 2012 that Judge Peck and I are best known for.
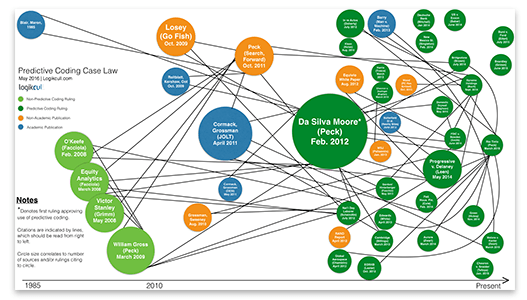
E-discovery Team members employed by Kroll Ontrack also see hundreds of document reviews for other law firms and corporate clients. They see them from all around the world. There is no doubt in our minds that keyword search is still the dominant search method used by most attorneys. It is especially true in small to medium-sized firms, but also in larger firms that have no e-discovery search expertise. Many attorneys and paralegals who use a sophisticated, full featured document review platforms such as Kroll Ontrack’s EDR, still only use keyword search. They do not use the many other powerful search techniques of EDR, even though they are readily available to them. The Search Pyramid to them looks more like this, which I call a Dunce Hat.

The AI at the top, standing for Predictive Coding, is, for average lawyers today, still just a far off remote mountain top; something they have heard about, but never tried. Even though this is my speciality, I am not worried about this. I am confident that this will all change soon. Our new, easier to use methods will help with that, so too will ever improving software by the few vendors left standing. God knows the judges are already doing their part. Plus, high-tech propagation is an inevitable result of the next generation of lawyers assuming leadership positions in law firms and legal departments.
The old-timey paper lawyers around the world are finally retiring in droves. The aging out of current leadership is a good thing. Their over-reliance on untested keyword search to find evidence is holding back our whole justice system. The law must keep up with technology and lawyers must not fear math, science and AI. They must learn to keep up with technology. This is what will allow the legal profession to remain a bedrock of contemporary culture. It will happen. Positive disruptive change is just under the horizon and will soon rise.

 In the meantime we encounter opposing counsel everyday who think e-discovery means to dream up keywords and demand that every document that contains their keywords be produced. The more sophisticated of this confederacy of dunces understand that we do not have to produce them, that they might not all be per se relevant, but they demand that we review them all and produce the relevant ones. Fortunately we have the revised rules to protect our clients from these kind of disproportionate, unskilled demands. All too often this is nothing more than discovery as abuse.
In the meantime we encounter opposing counsel everyday who think e-discovery means to dream up keywords and demand that every document that contains their keywords be produced. The more sophisticated of this confederacy of dunces understand that we do not have to produce them, that they might not all be per se relevant, but they demand that we review them all and produce the relevant ones. Fortunately we have the revised rules to protect our clients from these kind of disproportionate, unskilled demands. All too often this is nothing more than discovery as abuse.
This still dominant approach to litigation is really nothing more than an artifact of the old-timey paper lawyers’ use of discovery as a weapon. Let me speak plainly. This is nothing more than adversarial bullshit discovery with no real intent by the requesting party to find out what really happened. They just want to make the process as expensive and difficult as possible for the responding party because, well, that’s what they were trained to do. That is what they think smart, adversarial discovery is all about. Just another tool in their negotiate and settle, extortion approach to litigation. It is the opposite of the modern cooperative approach.
 I cannot wait until these dinosaurs retire so we can get back to the original intent of discovery, a cooperative pursuit of the facts. Fortunately, a growing number of our opposing counsel do get it. We are able to work very well with them to get things done quickly and effectively. That is what discovery is all about. Both sides save their powder for when it really matters, for the battles over the meaning of the facts, the governing law, and how the facts apply to this law for the result desired.
I cannot wait until these dinosaurs retire so we can get back to the original intent of discovery, a cooperative pursuit of the facts. Fortunately, a growing number of our opposing counsel do get it. We are able to work very well with them to get things done quickly and effectively. That is what discovery is all about. Both sides save their powder for when it really matters, for the battles over the meaning of the facts, the governing law, and how the facts apply to this law for the result desired.
Tested, Parametric Boolean Keyword Search

In some projects tested Keyword Search works great.
The biggest surprise for me in our latest research is just how amazingly good keyword search can perform under the right circumstances. I’m talking about hands-on, tested keyword search based on human document review and file scanning, sampling, and also based on strong keyword search software. When keyword search is done with skill and is based on the evidence seen, typically in a refined series of keyword searches, very high levels of Precision, Recall and F1 are attainable. Again, the dataset and other conditions must be just right for it to be that effective, as explained in the diagram: simple data, clear target and good SME. Sometimes keywords are the best way to find clear targets like names and dates.
In those circumstances the other search forms may not be needed to find the relevant documents, or at least to find almost all of the relevant documents. These are cases where the hybrid balance is tipped heavily towards the 400 pound man hacking away at the computer. All the AI does in these circumstances, when the human using keyword search is on a roll, is double-check and verify that it agrees that all relevant documents have been located. It is always nice to get a free second opinion from Mr. EDR. This is an excellent quality control and quality assurance application from our legal robot friends.

 We are not going to try to go through all of the ins and outs of keyword search. There are many variables and features available in most document review platforms today to make it easy to construct effective keyword searches and otherwise find similar documents. This is the kind of thing that KO and I teach to the e-discovery liaisons in my firm and other attorneys and paralegals handing electronic document reviews. The passive learning software features can be especially helpful, so too can simple indexing and clustering. Most software programs have important features to improve keyword search and make it more effective. All lawyers should learn the basic tested, keyword search skills.
We are not going to try to go through all of the ins and outs of keyword search. There are many variables and features available in most document review platforms today to make it easy to construct effective keyword searches and otherwise find similar documents. This is the kind of thing that KO and I teach to the e-discovery liaisons in my firm and other attorneys and paralegals handing electronic document reviews. The passive learning software features can be especially helpful, so too can simple indexing and clustering. Most software programs have important features to improve keyword search and make it more effective. All lawyers should learn the basic tested, keyword search skills.
There is far more to effective keyword search than a simple Google approach. (Google is concerned with finding websites, not recall of relevant evidence.) Still, in the right case, with the right data and easy targets, keywords can open the door to both high recall and precision. Keyword search, even tested and sophisticated, does not work well in complex cases or with dirty data. It certainly has its limits and there is a significant danger in over reliance on keyword search. It is typically very imprecise and can all to easily miss unexpected word usage and misspellings. That is one reason that the e-Discovery Team always supplements keyword search with a variety of other search methods, including predictive coding.
Focused Linear Search – Key Dates & People
 In Abraham Lincoln’s day all a lawyer had to do to prepare for a trial was talk to some witnesses, talk to his client and review all of the documents the clients had that could possibly be relevant. All of them. One right after the other. In a big case that might take an hour. Flash forward one hundred years to the post-photocopier era of the 1960s and document review, linear style reviewing them all, might take a day. By the 1990s it might take weeks. With the data volume of today such a review would take years.
In Abraham Lincoln’s day all a lawyer had to do to prepare for a trial was talk to some witnesses, talk to his client and review all of the documents the clients had that could possibly be relevant. All of them. One right after the other. In a big case that might take an hour. Flash forward one hundred years to the post-photocopier era of the 1960s and document review, linear style reviewing them all, might take a day. By the 1990s it might take weeks. With the data volume of today such a review would take years.
All document review was linear up until the 1990s. Until that time almost all documents and evidence were paper, not electronic. The records were filed in accordance with an organization wide filing system. They were combinations of chronological files and alphabetical ordering. If the filing was by subject then the linear review conducted by the attorney would be by subject, usually in alphabetical order. Otherwise, without subject files, you would probably take the data and read it in chronological order. You would certainly do this with the correspondence file. This was done by lawyers for centuries to look for a coherent story for the case. If you found no evidence of value in the papers, then you would smile knowing that your client’s testimony could not be contradicted by letters, contracts and other paperwork.

This kind of investigative, linear review still goes on today. But with today’s electronic document volumes the task is carried out in warehouses by relatively low paid, document review contract lawyers. By itself it is a fool’s errand, but it is still an important part of a multimodal approach.

There is nothing wrong with Focused Linear Search when used in moderation. And there is nothing wrong with document review contract-lawyers, except that they are underpaid for their services, especially the really good ones. I am a big fan of document review specialists.
 Large linear review projects can be expensive and difficult to manage. Moreover, it typically has only limited use. It breaks down entirely when large teams are used because human review is so inconsistent in document analysis. Losey, R., Less Is More: When it comes to predictive coding training, the “fewer reviewers the better” (parts One, Two and three) (December 8, 2013, e-Discovery Team). When review of large numbers of documents are involved the consistency rate among multiple human reviewers is dismal. Also see: Roitblat, Predictive Coding with Multiple Reviewers Can Be Problematic: And What You Can Do About It (4/12/16).
Large linear review projects can be expensive and difficult to manage. Moreover, it typically has only limited use. It breaks down entirely when large teams are used because human review is so inconsistent in document analysis. Losey, R., Less Is More: When it comes to predictive coding training, the “fewer reviewers the better” (parts One, Two and three) (December 8, 2013, e-Discovery Team). When review of large numbers of documents are involved the consistency rate among multiple human reviewers is dismal. Also see: Roitblat, Predictive Coding with Multiple Reviewers Can Be Problematic: And What You Can Do About It (4/12/16).
Still, linear review can be very helpful in limited time spans and in reconstruction of a quick series of events, especially communications. Knowing what happened one day in the life of a key custodian can sometimes give you a great defense or great problem. Either are rare. Most of the time Expert Manual Review is helpful, but not critical. That is why Expert Manual Review is at the base of the Search Pyramid that illustrates our multimodal approach.
An attorney’s knowledge, wisdom and skill are the foundation of all that we do, with or without AI. The information that an attorney holds is also of value, especially information about the latest technology, but the human information roles are diminishing. Instead the trend is to delegate mere information level services to automated systems. The legal robots would not be permitted to go beyond information fulfillment roles and provide legal advice based on human knowledge and wisdom. Their function would be constrained to Information processing and reports. The metrics and technology tools they provide can make it easier for the human attorneys to build a solid evidentiary foundation for trial.
To be continued …
[…] Predictive Coding 4.0 – Nine Key Points of Legal Document Review and an Updated Statement of Our W… – Passive, unsupervised machine learning is a good way to be introduced to … The AI at the … […]
[…] to electronic document review using Predictive Coding. Here are Parts One, Two, Three and Four. This series explains the nine insights behind the latest upgrade to version 4.0 and the slight […]
[…] to electronic document review using Predictive Coding. Here are Parts One, Two, Three, Four and Five. This series explains the nine insights behind the latest upgrade to version 4.0 and the […]
[…] to electronic document review using Predictive Coding. Here are Parts One, Two, Three, Four, Five and Six. This series explains the nine insights behind the latest upgrade to version 4.0. […]