Fifth Class: 1st of the Nine Insights – Active Machine Learning
The fourth class is lengthy and may be difficult, but the machine learning insight discussed here is critical. It must be understood and applied correctly to attain consistent success with predictive coding. Is it broken down in four sections: Passive Analytics; e-Discovery Vendors; Maura Grossman’s Warnings; and, Double Loop Learning. The last subject is very advanced, but try it out anyway, even if you are a novice. Some people have a knack for this kind of thing, especially if they have experience in teaching situations.

Passive Analytic Methods Are Not Predictive Coding
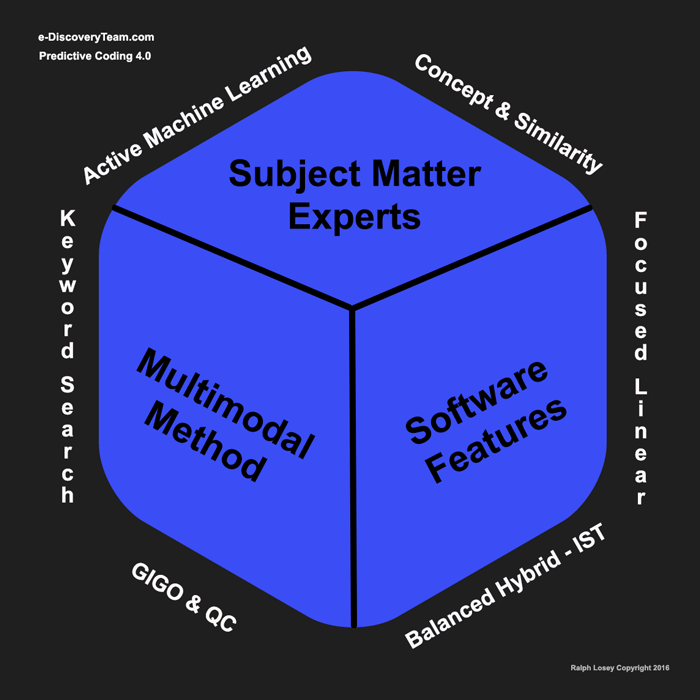
Even though our methods are multimodal and hybrid, the primary search method we rely on is Active Machine Learning. The overall name of our method is, after all, Predictive Coding. And, as any information retrieval expert will tell you, predictive coding means active machine learning. That is the only true AI method. The passive type of machine learning that some vendors use under the name Analytics is NOT the same thing as Predictive Coding. These passive Analytics have been around for years and are far less powerful than active machine learning.
 These search methods, that used to be called Concept Search, were a big improvement upon relying on keyword search alone. I remember talking about concepts search techniques in reverent terms when I did my first Legal Search webinar in 2006 with Jason Baron and Professor Doug Oard. That same year, Kroll Ontrack bought one of the original developers and patent holders of concept search, Engenium. For a short time in 2006 and 2007 Kroll Ontrack was the only vendor to have these concept search tools. The founder of Engenium, David Chaplin came with the purchase, and became Kroll Ontrack’s VP of Advanced Search Technologies for three years. (Here is an interesting interview of Chaplin that discusses what he and Kroll Ontrack were doing with advanced search analytic-type tools when he left in 2009.)
These search methods, that used to be called Concept Search, were a big improvement upon relying on keyword search alone. I remember talking about concepts search techniques in reverent terms when I did my first Legal Search webinar in 2006 with Jason Baron and Professor Doug Oard. That same year, Kroll Ontrack bought one of the original developers and patent holders of concept search, Engenium. For a short time in 2006 and 2007 Kroll Ontrack was the only vendor to have these concept search tools. The founder of Engenium, David Chaplin came with the purchase, and became Kroll Ontrack’s VP of Advanced Search Technologies for three years. (Here is an interesting interview of Chaplin that discusses what he and Kroll Ontrack were doing with advanced search analytic-type tools when he left in 2009.)
 But search was hot and soon boutique search firms like, Clearwell, Cataphora, Content Analyst (the company recently purchased by popular newcomer, kCura), and other e-discovery vendors developed their own concept search tools. Again, they were all using passive machine learning. It was a big deal ten years ago. For a good description of these admittedly powerful, albeit now dated search tools, see the concise, well-written article by D4’s Tom Groom, The Three Groups of Discovery Analytics and When to Apply Them.
But search was hot and soon boutique search firms like, Clearwell, Cataphora, Content Analyst (the company recently purchased by popular newcomer, kCura), and other e-discovery vendors developed their own concept search tools. Again, they were all using passive machine learning. It was a big deal ten years ago. For a good description of these admittedly powerful, albeit now dated search tools, see the concise, well-written article by D4’s Tom Groom, The Three Groups of Discovery Analytics and When to Apply Them.
Search experts and information scientists know that active machine learning, also called supervised machine learning, was the next big step in search after concept searches, which are, in programming language, also known as passive or unsupervised machine learning. I am getting out of my area of expertise here, and so am unable go into any details, other than present the below instructional chart by Hackbright Academy that sets forth key difference between supervised learning (predictive coding) and unsupervised (analytics, aka concept search).

What I do know is that the bonafide active machine learning software in the market today all use either a form of Logistic Regression, including Kroll Ontrack, or SVM, which means Support Vector Machine.
e-Discovery Vendors Have Been Market Leaders in Active Machine Learning Software
 After Kroll Ontrack absorbed the Engenium purchase, and its founder Chaplin completed his contract with Kroll Ontrack and moved on, Kroll Ontrack focused their efforts on the next big step, active machine learning, aka predictive coding. They have always been that kind of cutting edge company, especially when it comes to search, which is one reason they are one of my personal favorites. A few of the other, then leading e-discovery vendors did too, including especially Recommind and the Israeli based search company, Equivo. Do not get me wrong, the concept search methods, now being sold under the name of TAR Analytics, are powerful search tools. They are a part of our multimodal tool-kit and should be part of yours. But they are not predictive coding. They do not rank documents according to your external input, your supervision. They do not rely on human feedback. They group documents according to passive analytics of the data. It is automatic, unsupervised. These passive analytic algorithms can be good tools for efficient document review, but they not active machine learning and are nowhere near as powerful.
After Kroll Ontrack absorbed the Engenium purchase, and its founder Chaplin completed his contract with Kroll Ontrack and moved on, Kroll Ontrack focused their efforts on the next big step, active machine learning, aka predictive coding. They have always been that kind of cutting edge company, especially when it comes to search, which is one reason they are one of my personal favorites. A few of the other, then leading e-discovery vendors did too, including especially Recommind and the Israeli based search company, Equivo. Do not get me wrong, the concept search methods, now being sold under the name of TAR Analytics, are powerful search tools. They are a part of our multimodal tool-kit and should be part of yours. But they are not predictive coding. They do not rank documents according to your external input, your supervision. They do not rely on human feedback. They group documents according to passive analytics of the data. It is automatic, unsupervised. These passive analytic algorithms can be good tools for efficient document review, but they not active machine learning and are nowhere near as powerful.

Search Software Ghosts
Many of the software companies that made the multi-million dollar investments necessary to go to the next step and build document review platforms with active machine learning algorithms have since been bought out by big-tech and repurposed out of the e-discovery market. They are the ghosts of legal search past. Clearwell was purchased by Symantec and has since disappeared. Autonomy was purchased by Hewlett Packard and has since disappeared. Equivio was purchased by Microsoft and has since disappeared. See e-Discovery Industry Reaction to Microsoft’s Offer to Purchase Equivio for $200 Million – Part One and Part Two. Recommind was recently purchased by OpenText and, although it is too early to tell for sure, may also soon disappear from e-Discovery.
Slightly outside of this pattern, but with the same ghosting result, e-discovery search company, Cataphora, was bought by Ernst & Young, and has since disappeared. The year after the acquisition, Ernst & Young added predictive coding features from Cataphora to its internal discovery services. At this point, all of the Big Four Accounting Firms, claim to have their own proprietary software with predictive coding. Along the same lines, at about the time of the Cataphora buy-out, consulting giant FTI purchased another e-discovery document review company, Ringtail Solutions (known for its petri dish like visualizations). Although not exactly ghosted by FTI from the e-discovery world after the purchase, they have been absorbed by the giant FTI.
 Outside of consulting/accountancy, in the general service e-discovery industry for lawyers, there are, at this point (late 2016) just a few document review platforms left that have real active machine learning. Some of the most popular ones left behind certainly do not. They only have passive learning analytics. Again, those are good features, but they are not active machine learning, one of the nine basic insights of Predictive Coding 4.0 and a key component of the e-Discovery Team’s document review capabilities.
Outside of consulting/accountancy, in the general service e-discovery industry for lawyers, there are, at this point (late 2016) just a few document review platforms left that have real active machine learning. Some of the most popular ones left behind certainly do not. They only have passive learning analytics. Again, those are good features, but they are not active machine learning, one of the nine basic insights of Predictive Coding 4.0 and a key component of the e-Discovery Team’s document review capabilities.
The power of the advanced, active learning technologies that have been developed for e-discovery is the reason for all of these acquisitions by big-tech and the big-4 or 5. It is not just about wild overspending, although that may well have been the case for Hewlett Packard payment of $10.3 Billion to buy Autonomy. The ability to do AI-enhanced document search and review is a very valuable skill, one that will only increase in value as our data volumes continue to explode. The tools used for such document review are also quite valuable, both inside the legal profession and, as the ghostings prove, well beyond into big business. See e-Discovery Industry Reaction to Microsoft’s Offer to Purchase Equivio for $200 Million, Part Two.
The indisputable fact that so many big-tech companies have bought up the e-discovery companies with active machine learning software should tell you a lot. It is a testimony to the advanced technologies that the e-discovery industry has spawned. When it comes to advanced search and document retrieval, we in the e-discovery world are the best in the world my friends, primarily because we have (or can easily get) the best tools. Smile.

Search is king of our modern Information Age culture. See Information → Knowledge → Wisdom: Progression of Society in the Age of Computers. The search for evidence to peacefully resolve disputes is, in my most biased opinion, the most important search of all. It sure beats selling sugar water. Without truth and justice all of the petty business quests for fame and fortune would crumble into anarchy, or worse, dictatorship.
With this background it is easy to understand why some of the e-discovery vendors left standing are not being completely candid about the capabilities of their document review software. (It is called puffing and is not illegal.) The industry is unregulated and, alas, most of our expert commentators are paid by vendors. They are not independent. As a result, many of the lawyers who have tried what they thought was predictive coding, and had disappointing results, have never really tried predictive coding at all. They have just used slightly updated concept search.
 Alternatively, some of the disappointed lawyers may have used one of the many now-ghosted vendor tools. They were all early version 1.0 type tools. For example, Clearwell’s active machine learning was only on the market for a few months with this feature before they were bought and ghosted by Symantec. (I think Jason Baron and I were the first people to see an almost completed demo of their product at a breakfast meeting a few months before it was released.) Recommind’s predictive coding software was well-developed at the time of their sell-out, but not its methods of use. Most of its customers can testify as to how difficult it is to operate. That is one reason that OpenText was able to buy them so cheaply, which, we now see, was part of their larger acquisition plan culminating in the purchase of Dell’s EMC document management software.
Alternatively, some of the disappointed lawyers may have used one of the many now-ghosted vendor tools. They were all early version 1.0 type tools. For example, Clearwell’s active machine learning was only on the market for a few months with this feature before they were bought and ghosted by Symantec. (I think Jason Baron and I were the first people to see an almost completed demo of their product at a breakfast meeting a few months before it was released.) Recommind’s predictive coding software was well-developed at the time of their sell-out, but not its methods of use. Most of its customers can testify as to how difficult it is to operate. That is one reason that OpenText was able to buy them so cheaply, which, we now see, was part of their larger acquisition plan culminating in the purchase of Dell’s EMC document management software.
All software still using early methods, what we call version 1.0 and 2.0 methods based on control sets, are cumbersome and hard to operate, not just Recommind’s system. This was discussed in the First Class. Some vendors with predictive coding would only let you use predictive coding for search. It was, in effect, mono-modal. That is also a mistake. All types of search must be used – multimodal – for the predictive coding type of search to work efficiently and effectively. More on that point later.
The Only Other Attorney at TREC, Maura Grossman, Also Blows the Whistle on Ineffective “TAR tools” 
Maura Grossman, who is now an independent expert in this field, made many of these same points in an interview with Artificial Lawyer, a periodical dedicated to AI and the Law. AI and the Future of E-Discovery: AL Interview with Maura Grossman (Sept. 16, 2016). When asked about the viability of the “over 200 businesses offering e-discovery services” Maura said, among other things:
In the long run, I am not sure that the market can support so many e-discovery providers …
… many vendors and service providers were quick to label their existing software solutions as “TAR,” without providing any evidence that they were effective or efficient. Many overpromised, overcharged, and underdelivered. Sadly, the net result was a hype cycle with its peak of inflated expectations and its trough of disillusionment. E-discovery is still far too inefficient and costly, either because ineffective so-called “TAR tools” are being used, or because, having observed the ineffectiveness of these tools, consumers have reverted back to the stone-age methods of keyword culling and manual review.
 Now that Maura is no longer with the law firm of Wachtell Lipton, she has more freedom to speak her mind about caveman lawyers. It is refreshing and, as you can see, echoes much of what I have been saying. But wait, there is still more that you need to hear from the interview of new Professor Grossman:
Now that Maura is no longer with the law firm of Wachtell Lipton, she has more freedom to speak her mind about caveman lawyers. It is refreshing and, as you can see, echoes much of what I have been saying. But wait, there is still more that you need to hear from the interview of new Professor Grossman:
It is difficult to know how often TAR is used given confusion over what “TAR” is (and is not), and inconsistencies in the results of published surveys. As I noted earlier, “Predictive Coding”—a term which actually pre-dates TAR—and TAR itself have been oversold. Many of the commercial offerings are nowhere near state of the art; with the unfortunate consequence that consumers have generalised their poor experiences (e.g., excessive complexity, poor effectiveness and efficiency, high cost) to all forms of TAR. In my opinion, these disappointing experiences, among other things, have impeded the adoption of this technology for e-discovery. …
 Not all products with a “TAR” label are equally effective or efficient. There is no Consumer Reports or Underwriters Laboratories (“UL”) that evaluates TAR systems. Users should not assume that a so-called “market leading” vendor’s tool will necessarily be satisfactory, and if they try one TAR tool and find it to be unsatisfactory, they should keep evaluating tools until they find one that works well. To evaluate a tool, users can try it on a dataset that they have previously reviewed, or on a public dataset that has previously been labelled; for example, one of the datasets prepared for the TREC 2015 or 2016 Total Recall tracks. …
Not all products with a “TAR” label are equally effective or efficient. There is no Consumer Reports or Underwriters Laboratories (“UL”) that evaluates TAR systems. Users should not assume that a so-called “market leading” vendor’s tool will necessarily be satisfactory, and if they try one TAR tool and find it to be unsatisfactory, they should keep evaluating tools until they find one that works well. To evaluate a tool, users can try it on a dataset that they have previously reviewed, or on a public dataset that has previously been labelled; for example, one of the datasets prepared for the TREC 2015 or 2016 Total Recall tracks. …
She was then asked by the Artificial Lawyer interviewer (name never identified), which is apparently based in the UK, another popular question:
As is often the case, many lawyers are fearful about any new technology that they don’t understand. There has already been some debate in the UK about the ‘black box’ effect, i.e., barristers not knowing how their predictive coding process actually worked. But does it really matter if a lawyer can’t understand how algorithms work?
 The following is an excerpt of Maura’s answer. Suggest you consult the full article for a complete picture. AI and the Future of E-Discovery: AL Interview with Maura Grossman (Sept. 16, 2016). I am not sure whether she put on her Google Glasses to answer (probably not), but anyway, I rather like it.
The following is an excerpt of Maura’s answer. Suggest you consult the full article for a complete picture. AI and the Future of E-Discovery: AL Interview with Maura Grossman (Sept. 16, 2016). I am not sure whether she put on her Google Glasses to answer (probably not), but anyway, I rather like it.
Many TAR offerings have a long way to go in achieving predictability, reliability, and comprehensibility. But, the truth that many attorneys fail to acknowledge is that so do most non-TAR offerings, including the brains of the little black boxes we call contract attorneys or junior associates. It is really hard to predict how any reviewer will code a document, or whether a keyword search will do an effective job of finding substantially all relevant documents. But we are familiar with these older approaches (and we think we understand their mechanisms), so we tend to be lulled into overlooking their limitations.
The brains of the little black boxes we call contract attorneys or junior associates. So true. We will go into that more thoroughly in our discussion of the GIGO & QC insight.
Recent Team Insights: Double Loop Learning
To summarize what we have said so far in the Fourth Class, in the field of legal search, only active machine learning:
- effectively enhances human intelligence with artificial intelligence;
- qualifies for the term Predictive Coding.
 I want to close this class on active machine learning with one more insight. This one is slightly technical, and again, if I explain it correctly, should seem perfectly obvious. It is certainly not new, and most search scientists and other experts will already know this to some degree. Still, even for them, there might be some new nuances to this insight. It can be summarized as follows: active machine learning should have a double feedback loop with active monitoring by the attorney trainers. This is yet again a new Man-Machine variation to the team concept, e-Discovery Team of the future already here now for some.
I want to close this class on active machine learning with one more insight. This one is slightly technical, and again, if I explain it correctly, should seem perfectly obvious. It is certainly not new, and most search scientists and other experts will already know this to some degree. Still, even for them, there might be some new nuances to this insight. It can be summarized as follows: active machine learning should have a double feedback loop with active monitoring by the attorney trainers. This is yet again a new Man-Machine variation to the team concept, e-Discovery Team of the future already here now for some.

Active machine learning should create feedback for both the algorithm (the data classified) AND the human managing the training. Both should learn, not just the robot. They should, so to speak, be friendly team members. They should get to know each other.
Many predictive coding methods that I have read about, or heard described, including how I first used active machine learning, did not sufficiently include the human trainer in the feedback loop. They were static types of training using single a feedback loop. These methods are, so to speak, very stand-offish, aloof. Under these methods the attorney trainer does not even try to understand what is going on with the robot. The information flow was one-way, from attorney to machine.
![]() As I grew more experienced with the EDR software I started to realize that it is possible to start to understand, at least a little, what the black box is doing. It takes close observation, but becomes an interesting game in tiself, a very worhtwhile game. becuase the more you play it the better you become at selecting the best documents for training.
As I grew more experienced with the EDR software I started to realize that it is possible to start to understand, at least a little, what the black box is doing. It takes close observation, but becomes an interesting game in tiself, a very worhtwhile game. becuase the more you play it the better you become at selecting the best documents for training.
Logistic based AI is a foreign intelligence, and fairly low level at this point, but it is an intelligence. After a while you start to understand it. So although I started just using one-sided machine training, I slowly gained the ability to read how EDR was learning. I was thereby adding another dimension, another feedback loop, to the machine training process. This was a very interesting new aspect to the program. Now I not only trained and provided feedback to the AI as to whether the predictions of relevance were correct, or not, but I also received training from the AI as to how well, or not, it was learning. That in turn led to the light-hearted personification of the Kroll software that we now call Mr. EDR. See MrEDR.com. When we reached this level, machine training became a fully active, two-way process.
We now understand that to fully supervise a predictive coding process you to have a good understanding of what is happening. How else can you supervise it? You do not have to know exactly how the engine works, but you at least need to know how fast it is going. You need a speedometer. You also need to pay attention to how the engine is operating, whether it is over-heating, needs oil or gas, etc. The same holds true to teaching humans. Their brains are indeed mysterious black boxes. You do not need to know exactly how each student’s brain works in order to teach them. You find out if your teaching is getting through by questions.
For us supervised learning means that the human attorney has an active role in the process. A role where the attorney trainer learns by observing the trainee, the AI in creation. I want to know as much as possible, so long as it does not slow me down significantly.

In other methods of using predictive coding that we have used or seen described the only role of the human trainer is to say yes or no as to the relevance of a document. The decision as to what documents to select for training has already been predetermined. Typically it is the highest ranked documents, but sometimes also some mid-ranked “uncertain documents” or some “random documents” are added in the mix. The attorney has no say in what documents to look at. They are all fed to him or her according to predetermined rules. These decision making rules are set in advance and do not change. These active machine learning methods work, but they are slow, and less precise, not to mention boring as hell. A smart human can really move things along and make training go faster. We have proven that many times. It is one reason why our precision scores at TREC were so high.
The recall of a single-loop passive supervision methods may also not be as good. The jury is still out on that question. We are trying to run experiments on that now, although it can be hard to stop yawning. See an earlier experiment on this topic testing the single loop teaching method of random selection: Borg Challenge: Report of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodology.
These mere yes or no, limited participation methods are hybrid Man-Machine methods, but, in our opinion, they are imbalanced towards the Machine. (Again, more on the question of Hybrid Balance will be covered in the next installment of this article.) This single versus dual feedback approach seems to be the basic idea behind the Double Loop Learning approach to human education depicted in the diagram below. Also see Graham Attwell, Double Loop Learning and Learning Analytics (Pontydysgu, May 4, 2016).

To quote Wikipedia:
The double loop learning system entails the modification of goals or decision-making rules in the light of experience. The first loop uses the goals or decision-making rules, the second loop enables their modification, hence “double-loop.” …
Double-loop learning is contrasted with “single-loop learning”: the repeated attempt at the same problem, with no variation of method and without ever questioning the goal. …
Double-loop learning is used when it is necessary to change the mental model on which a decision depends. Unlike single loops, this model includes a shift in understanding, from simple and static to broader and more dynamic, such as taking into account the changes in the surroundings and the need for expression changes in mental models.

The method of active machine learning that we use in Predictive Coding 4.0 is a type of double loop learning system. As such it is ideal for legal search, which is inherently ad hoc, where even the understanding of relevance evolves as the project develops. As Maura noted near the end of the Artificial Lawyer interview:
… e-discovery tends to be more ad hoc, in that the criteria applied are typically very different for every review effort, so each review generally begins from a nearly zero knowledge base.
The driving impetus behind our double feedback look system is to allow for training document selection to vary according to the circumstances encountered. Attorneys select documents for training and then observe how these documents impact the AI’s overall ranking of the documents. Based on this information decisions are then made by the attorney as to which documents to next submit for training. A single fixed mental model is not used, such as only submitting the ten highest ranked documents for training.
The human stays involved and engaged and selects the next documents to add to the training based on what she sees. This makes the whole process much more interesting. For example, if I find a group of relevant spreadsheets by some other means, such as a keyword search, then, when I add these document to the training, I observe how these documents impact the overall ranking of the data-set. For instance, did this training result in an increase of relevance ranking of other spreadsheets? Was the increase nominal or major? How did it impact the ranking of other documents? For instance, were emails with a lot of numbers in them suddenly much higher ranked? Overall, was this training effective? Were the documents in fact relevant as predicted that moved up in rank to the top, or near top of probable relevance? What was the precision rate like for these documents? Does the AI now have a good understanding of relevance of spreadsheets, or need more training on that type of document? Should we focus our search on other kinds of documents?
You see all kinds of variations on that. If the spreadsheet understanding (ranking) is good, how does it compare to its understanding (correct ranking) of Word Docs or emails? Where should I next focus my multimodal searches? What documents should I next assign to my reviewers to read and make a relevancy determination? These kind of considerations keep the search interesting, fun even. Work as play is the best kind. Typically we simply assign the documents for attorney review that have the highest ranking (which is the essence of what Grossman and Cormack call CAL), but not always. We are flexible. We, the human attorneys, are the second positive feedback loop.
 We like to remain in charge of teaching the classifier, the AI. We do not just turn it over to the classifier to teach itself. Although sometimes, when we are out of ideas and are not sure what to do next, we will do exactly that. We will turn over to the computer the decision of what documents to review next. We just go with his top predictions and use those documents to train. Mr. EDR has come through for us many times when we have done that. But this is more of an exception, than the rule. After all, the classifier is a tabula rasa. As Maura put it: each review generally begins from a nearly zero knowledge base. Before the training starts, it knows nothing about document relevance. The computer does not come with built-in knowledge of the law or relevance. You know what you are looking for. You know what is relevant, even if you do not know how to find it, or even whether it exists at all. The computer does not know what you are looking for, aside from what you have told it by your yes-no judgments on particular documents. But, after you teach it, it knows how to find more documents that probably have the same meaning.
We like to remain in charge of teaching the classifier, the AI. We do not just turn it over to the classifier to teach itself. Although sometimes, when we are out of ideas and are not sure what to do next, we will do exactly that. We will turn over to the computer the decision of what documents to review next. We just go with his top predictions and use those documents to train. Mr. EDR has come through for us many times when we have done that. But this is more of an exception, than the rule. After all, the classifier is a tabula rasa. As Maura put it: each review generally begins from a nearly zero knowledge base. Before the training starts, it knows nothing about document relevance. The computer does not come with built-in knowledge of the law or relevance. You know what you are looking for. You know what is relevant, even if you do not know how to find it, or even whether it exists at all. The computer does not know what you are looking for, aside from what you have told it by your yes-no judgments on particular documents. But, after you teach it, it knows how to find more documents that probably have the same meaning.
 By observation you can see for yourself, first hand, how your training is working, or not working. It is like a teacher talking to their students to find out what they learned from the last assigned reading materials. You may be surprised by how much, or how little they learned. If the last approach did not work, you change the approach. That is double-loop learning. In that sense our active monitoring approach it is like continuous dialogue. You learn how and if the AI is learning. This in turn helps you to plan your next lessons. What has the student learned? Where does the AI need more help to understand the conception of relevance that you are trying to teach it.
By observation you can see for yourself, first hand, how your training is working, or not working. It is like a teacher talking to their students to find out what they learned from the last assigned reading materials. You may be surprised by how much, or how little they learned. If the last approach did not work, you change the approach. That is double-loop learning. In that sense our active monitoring approach it is like continuous dialogue. You learn how and if the AI is learning. This in turn helps you to plan your next lessons. What has the student learned? Where does the AI need more help to understand the conception of relevance that you are trying to teach it.
 This monitoring of the AI’s learning is one of the most interesting aspects of active machine learning. It is also a great opportunity for human creativity and value. The inevitable advance of AI in the law can mean more jobs for lawyers overall, but only for those able step up and change their methods. The lawyers able to play the second loop game of active machine learning will have plenty of employment opportunities. See eg. Thomas H. Davenport, Julia Kirby, Only Humans Need Apply:Winners and Losers in the Age of Smart Machines (Harper 2016).
This monitoring of the AI’s learning is one of the most interesting aspects of active machine learning. It is also a great opportunity for human creativity and value. The inevitable advance of AI in the law can mean more jobs for lawyers overall, but only for those able step up and change their methods. The lawyers able to play the second loop game of active machine learning will have plenty of employment opportunities. See eg. Thomas H. Davenport, Julia Kirby, Only Humans Need Apply:Winners and Losers in the Age of Smart Machines (Harper 2016).
Or pause to do this suggested “homework” assignment for further study and analysis.
SUPPLEMENTAL READING: Review the Grossman Cormack TAR Glossary, noting especially the definition of TAR. Be sure to click on all of the many links on this page and at least give these webs a glance. Study carefully Tom Groom’s short article, The Three Groups of Discovery Analytics and When to Apply Them and also take your time studying AI and the Future of E-Discovery: AL Interview with Maura Grossman (Sept. 16, 2016). It is also a good idea to dig a little deeper into the general Double Loop Learning approach to education.
EXERCISES: As we learned in this class to fully supervise a machine learning process you need to understand what is happening. How else can you supervise it? The class uses the analogy of the automobile: “You do not have to know exactly how the search engine works, but you at least need to know how fast it is going. You need a speedometer. You also need to pay attention to how the engine is operating, whether it is over-heating, needs oil or gas, etc.” What other analogies can you think of to convey this idea?
Students are invited to leave a public comment below. Insights that might help other students are especially welcome. Let’s collaborate!
_
e-Discovery Team LLC COPYRIGHT 2017
ALL RIGHTS RESERVED
_