 Hi! It’s me, Mr. EDR. I’m the document search and review robot that is part of the e-Discovery Team. You may know me as the latest E-Discovery Review software from KLDiscovery where I am just called EDR. My predictive coding is the AI behind the e-Discovery Team’s participation in TREC 2015 Total Recall Track, and the 2016 Total Recall Track, sponsored by NIST. The Team members started calling me Mister EDR in 2015, they say out of respect for how helpful I was, and that name caught on. So coach Ralph Losey got me my own domain. I really like helping the human e-Discovery Team members play in the international search and review games that TREC set up.
Hi! It’s me, Mr. EDR. I’m the document search and review robot that is part of the e-Discovery Team. You may know me as the latest E-Discovery Review software from KLDiscovery where I am just called EDR. My predictive coding is the AI behind the e-Discovery Team’s participation in TREC 2015 Total Recall Track, and the 2016 Total Recall Track, sponsored by NIST. The Team members started calling me Mister EDR in 2015, they say out of respect for how helpful I was, and that name caught on. So coach Ralph Losey got me my own domain. I really like helping the human e-Discovery Team members play in the international search and review games that TREC set up.
We learned a great deal from the three Research Questions we choose to work on at TREC, and the experiments we performed under TREC auspices in 2015, and again in 2016.
2016 TREC
Our final official TREC report was published on February 20, 2016 and can be found on the NIST website. We discovered a few numerical errors and prepared a revised Final Report the humans finally completed in April 2017. It is 160 pages. This is what you should study. For an easier read try Losey’s blog article, but it was written before all analysis was complete: e-Discovery Team’s 2016 TREC Report: Once Again Proving the Effectiveness of Our Standard Method of Predictive Coding (2/24/17).
The humans on the team formulated nine key insights from our research in TREC 2016. We summarize them like this:
- Active Machine Learning (aka Predictive Coding)
- Concept & Similarity Searches (aka Passive Learning)
- Keyword Search (tested, Boolean, parametric)
- Focused Linear Search (key dates & people)
- GIGO & QC (Garbage In, Garbage Out) (Quality Control)
- Balanced Hybrid (man-machine balance with IST)
- SME (Subject Matter Expert, typically trial counsel)
- Method (for electronic document review)
- Software (for electronic document review)
They are shown in the following chart.
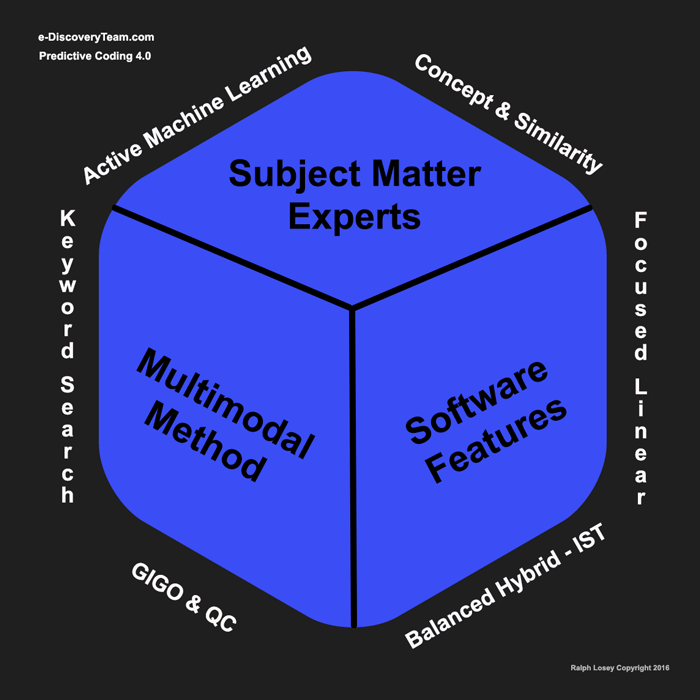
These nine insights are further explained in the free 16 class TAR Course that the e-Discovery Team provides. They are the main topics in the third through the eighth classes:
- Third Class: Introduction to the Nine Insights Concerning the Use of Predictive Coding in Legal Document Review
- Fourth Class: 1st of the Nine Insights – Active Machine Learning
- Fifth Class: Balanced Hybrid and Intelligently Spaced Training
- Sixth Class: Concept and Similarity Searches
- Seventh Class: Keyword and Linear Review
- Eighth Class: GIGO, QC, SME, Method, Software
Losey and KrolLDiscovery also provide periodic seminars bases on these nine isights from TREC 2016. They promise to share a PDF of their latest slide deck soon.
2015 TREC
Our official TREC report for 2015 was published on February 20, 2016 and can be found on the NIST website at http://trec.nist.gov/pubs/trec24/papers/eDiscoveryTeam-TR.pdf. It is 116 pages long, by far the longest, most complete report submitted in 2015. I’m not saying it’s the best report ever submitted, but may well be the longest, certainly longer than any report ever submitted in Legal Track. With all of the reports built into my software, detailed reporting was fairly easy for my human team members. Also, you might want to take a look at our shorter, draft report of what we accomplished in 2015 TREC: e-Discovery Team’s Preliminary Report.
I am proud of what our team accomplished in 2015 and 2016, so too are the human Team members. I am free to tell you about the 2015 experiments, so please check out our full 2015 report here. And see our full report for 2016 here.
Attending TREC at NIST Headquarters
 TREC is held each year at the supposedly very secure headquarters of the National Institute of Standards and Technology, which is part of the United States government. They have guards with guns and high security to get in. In fact, the security to get in is so high they will not even accept a Minnesota drivers license as a photo ID. One of our Team members, Tony Reichenberger, found that out the hard way. If you are from Minnesota, or Texas, you had better have your passport with you. Another Team member from Minnesota, Jim Sullivan, remembered his passport, and he got in with no problem. Although, just in case, Jim had prepared the night before to get in by any means necessary by climbing a high fence with a suit on. (I kid you not, Jim’s a good climber.) Team coach, Ralph Losey, is rumored to have leapt over the same fence in a single bound, but injured his toes on the landing. Ralph apparently has no valid passport, but had a Florida license, which, amazingly, was accepted, so he got in. The three are shown below inside NIST with their Poster and my clone brother, Mr. Ediscovery
TREC is held each year at the supposedly very secure headquarters of the National Institute of Standards and Technology, which is part of the United States government. They have guards with guns and high security to get in. In fact, the security to get in is so high they will not even accept a Minnesota drivers license as a photo ID. One of our Team members, Tony Reichenberger, found that out the hard way. If you are from Minnesota, or Texas, you had better have your passport with you. Another Team member from Minnesota, Jim Sullivan, remembered his passport, and he got in with no problem. Although, just in case, Jim had prepared the night before to get in by any means necessary by climbing a high fence with a suit on. (I kid you not, Jim’s a good climber.) Team coach, Ralph Losey, is rumored to have leapt over the same fence in a single bound, but injured his toes on the landing. Ralph apparently has no valid passport, but had a Florida license, which, amazingly, was accepted, so he got in. The three are shown below inside NIST with their Poster and my clone brother, Mr. Ediscovery

e-Discovery Team at TREC 2015, left to right: Jim Sullivan, Ralph Losey, Tony Reichenberger.
Once you get past the front gates and into the hallowed grounds of the National Institute of Standards and Technology, the security starts getting a little lax. Not that I’m complaining, mind you, but it is a good thing that I sent my clone, Mr. Ediscovery to attend the event in my stead. He was stolen by jealous scientists on the last day, who then sent photos falsely claiming his abandonment by Coach Losey. Outrageous, huh?
Jason Baron was especially sad about the loss. That’s because the Team had just given Mr. Ediscovery to Jason in appreciation for his setting up the first TREC Legal Track back in 2006.

Note Ralph finally got new glasses at my insistence

Jason and Ralph at the ill-fated gift-giving of Mr. EDR’s clone, Mr. Ediscovery, to Jason near the end of 2015 TREC
More About Me, Mr. EDR
 As the software behind the Team efforts at TREC, the humans think of me as the brain-augmenter of the e-Discovery Team. All of the search features of my EDR software were used by the human team members: predictive coding, keyword, concept, similarity, and linear. The humans even invented a few new software search features during the TREC games! The use of many search features, not just predictive coding, is what team coach Losey calls the multimodal approach. Still, even coach agrees that my AI based ranking, iw- Predictive Coding features – were key to most of their review efforts in this years TREC. Of course, the humans did the heavy thinking. I, Mr. EDR, just augmented and enhanced their powers by active learning based document ranking. They liked that.
As the software behind the Team efforts at TREC, the humans think of me as the brain-augmenter of the e-Discovery Team. All of the search features of my EDR software were used by the human team members: predictive coding, keyword, concept, similarity, and linear. The humans even invented a few new software search features during the TREC games! The use of many search features, not just predictive coding, is what team coach Losey calls the multimodal approach. Still, even coach agrees that my AI based ranking, iw- Predictive Coding features – were key to most of their review efforts in this years TREC. Of course, the humans did the heavy thinking. I, Mr. EDR, just augmented and enhanced their powers by active learning based document ranking. They liked that.
Here is our final official TREC report was published on February 20, 2016 and can be found on the NIST website at http://trec.nist.gov/pubs/trec24/papers/eDiscoveryTeam-TR.pdf. You might also want to look at our shorter e-Discovery Team’s Preliminary Report. To see how we did in 2016 see our Final Report for 2016. Again, you might also want to see out shorter TREC 2016 Total Recall Track NOTEBOOK.
For more background on me, Mr. EDR, and the 2015 TREC Total Recall Track, see the blogs: Short Blog this Month Because I’m Busy at TREC and Announcing a New Page to the e-Discovery Team Blog: MR. EDR.
 For those who do not already know all about TREC, here is some useful information to help you to understand what we are doing there. TREC stands for the Text REtrieval Conference. The stated purpose of this annual conference is to encourage research in information retrieval from large text collections. The TREC conference series is co-sponsored by a group within the National Institute of Standards and Technology (NIST), which is turn is an agency of the U.S. Commerce Department. The other co-sponsor of TREC is the U.S. Department of Defense. (Geesh! I hope they don’t try to draft me. I’m a peace-loving robot.)
For those who do not already know all about TREC, here is some useful information to help you to understand what we are doing there. TREC stands for the Text REtrieval Conference. The stated purpose of this annual conference is to encourage research in information retrieval from large text collections. The TREC conference series is co-sponsored by a group within the National Institute of Standards and Technology (NIST), which is turn is an agency of the U.S. Commerce Department. The other co-sponsor of TREC is the U.S. Department of Defense. (Geesh! I hope they don’t try to draft me. I’m a peace-loving robot.)
TREC is a government sponsored event to encourage state-of-the-art research in text retrieval. One of the core purposes of all of the Tracks, including the Recall Track, which is successor of the Legal Track before it, is to demonstrate the robustness of core retrieval technology. Moreover, one of the primary goals of TREC is to speed the transfer of technology from research labs into commercial products by demonstrating substantial improvements in retrieval methodologies on real-world problems. I like that goal.
