Fourth Class: Introduction to the Nine Insights Concerning the Use of Predictive Coding in Legal Document Review
The following diagram provides an overview of the nine fundamental discoveries derived from our scientific investigations conducted in 2015 and 2016. These are the essential ideas that we currently consider crucial to comprehend and apply.
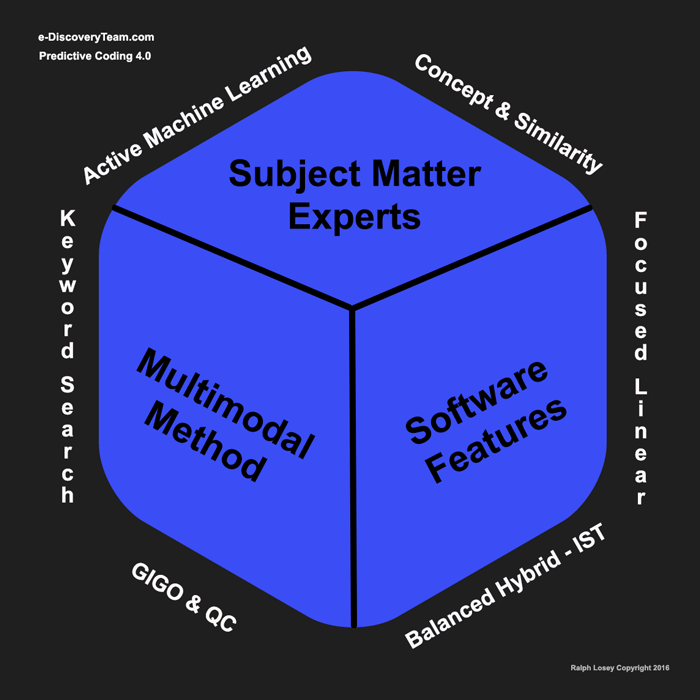
The nine insights are:
- Active Machine Learning (aka Predictive Coding)
- Concept & Similarity Searches (aka Passive Learning)
- Keyword Search (tested, Boolean, parametric)
- Focused Linear Search (key dates & people)
- GIGO & QC (Garbage In, Garbage Out) (Quality Control)
- Balanced Hybrid (man-machine balance with IST)
- SME (Subject Matter Expert, typically trial counsel)
- Method (for electronic document review)
- Software (for electronic document review)
The remaining part of this course will provide a detailed explanation of these concepts, as well as the revised 9-Step Workflow (different from the 9-insights). It is important to note that these ideas are not new, as some of them have been previously mentioned on my blog. I am confident that all readers will be able to comprehend the new insights we gained from TREC.
While the concepts may seem familiar, you may be surprised by our deepened understanding of them. We were also taken aback by some of the insights we discovered, leading to changes in our thinking. We encountered unexpected research results, but we remain committed to following the data. Our opinions are not set in stone; as a lawyer, I have argued both sides of a legal issue numerous times and know the dangers of falling into preconceived notions. Our thinking is guided by evidence, not preconceptions, as research demands.

While our insights and experiments were conducted using KrolLDiscovery EDR software, they could have been performed on several other software configurations available in early 2017. However, it is important to note that our methods necessitate a comprehensive document review platform with genuine active machine learning capabilities, also known as Predictive Coding. It is common knowledge among experts in this field that many popular document review platforms lack these features, even those claiming to utilize Analytics.
Active Machine Learning is significantly distinct and considerably more sophisticated compared to Analytics, which was initially referred to as Concept Search. Unlike predictive coding, this form of machine learning is passive and holds significance within multimodal systems like ours. Undoubtedly, it possesses the potential to enhance search and review as a powerful feature. However, incorporating active machine learning is essential to complete such software.

Consumers, the principle of “you get what you pay for” holds true. If you are uncertain, seek assistance from an unbiased expert advisor. It is crucial to do so before making significant investments in e-discovery software or selecting a vendor for a major project. Furthermore, if you have had a negative experience with predictive coding or what was marketed as advanced TAR, remember not to blame yourself. The issue could lie with the software itself or the method used. Unfortunately, there is a considerable amount of deceptive information in the market, particularly within the legal technology sector. It is possible that some may view lawyers as naive and easily swayed by technology. Don’t be deceived. Once again, rely on an independent consultant to navigate through vendor claims if you find yourself confused.

Despite the claims of certain vendors, who usually lack advanced active machine learning capabilities, it is important to note that predictive coding 3.0 and 4.0 methods are not overly complex. You don’t need to possess expert knowledge in technology-assisted review (TAR) or solely focus on searching, like my highly skilled team for TREC. With the right software, it can be quite straightforward.
However, it is important to note that these methods necessitate the involvement of an attorney who possesses extensive knowledge in e-discovery and is comfortable utilizing software. It is not suitable for individuals without prior experience. Nevertheless, it is advisable for every law firm to have attorneys who have received specialized training and possess expertise in technology and e-discovery. This is particularly relevant in the Northern District of California, and other locations like it, where most cases require the presence of an e-discovery liaison with such proficiency. See Guidelines for the Discovery of Electronically Stored Information. Almost half of the Bar Associations in the U.S. require basic technology competence as an ethical imperative. See eg. ABA Model Rule 1.1, Comment [8] and Robert Ambrogi’s list. More than half of the Bar Associations in the U.S. consider basic technology competence to be an ethical obligation, as stated in the ABA Model Rule 1.1, Comment [8], and supported by Robert Ambrogi’s now somewhat dated list.
So no, you do not have to be a full-time specialist, like the members of my TREC e-Discovery team were, to successfully use our method of AI-enhanced review. This is especially true when you work with top vendors that have teams of special consultants to guide you. You just have to pick your vendors wisely.
The nine insights are derived from our extensive experience and research. Certain insights, particularly our primary insight on Active Machine Learning and IST (Intelligently Spaced Training), may appear intricate. However, we regard IST as an intelligent and empowering substitute for CAL. If we present these insights accurately, their simplicity should become apparent. The chart below provides a partial summary of the insights and techniques utilized in Predictive Coding 4.0 document review.

Our approach is characterized as Multimodal as we employ various document search tools. While active machine learning is a significant aspect, it is not the sole method we rely on. Additionally, our method is Hybrid as it incorporates both machine judgments and human (lawyer) judgments. Furthermore, in our approach, the lawyer always assumes control. Although we may allow the machine to take the lead temporarily under our versions of Predictive Coding, we closely monitor the process. We are prepared to intervene immediately if necessary. Our methodology does not favor one cognitive capacity over the other. See eg. Why the ‘Google Car’ Has No Place in Legal Search (caution against over reliance on fully automated methods of active machine learning).
Certainly, the opposite is valid as well – we do not solely depend on our human brain due to its various constraints. Instead, we bolster our cognitive abilities by incorporating predictive coding algorithms. Furthermore, we supplement our innate intelligence with artificial intelligence. Later on, we will delve into the concept of the Balanced Hybrid, which signifies the ideal equilibrium between these two realms.
Or pause to do this suggested “homework” assignment for further study and analysis.
SUPPLEMENTAL READING: Read the Predictive Coding 3.0 article in full, both part one and part two. Part one describes the history and part two describes the method. This is still good background, especially for understanding the why so many attorneys who used the old 1.0 and 2.0 methods ended up not liking predictive coding. Many vendors are still stuck in these old, inefficient methods. Still, most are probably able to use the latest 4.0 methods with some minor modifications to the software’s built in work-flows. Also be sure to read the Google Car article referenced in this class. As general advice. you should try to take time to read all articles and other materials that are hyper-linked in any of our classes. That is why we linked them.
EXERCISES: Multiple suggested exercises for you:
- Search and find some online articles, including vendor papers, that discuss document review software analytics, but do not use the term predictive coding. Why do you think that is? (Hint – there are several reasons, not just one.)
- Search for other articles that specifically explain that TAR is active machine learning. Any idea why there are so few, relatively speaking?
- TAR seems to be the acronym that has caught on. Ideas why? What other terms were popular? Any ideas why it is that TAR won out?
- This class suggests getting help of an independent expert advisor before deciding upon predictive coding software. Aside from Losey, what other experts can you find that fit the bill?
Students are invited to leave a public comment below. Insights that might help other students are especially welcome. Let’s collaborate!
_
Ralph Losey COPYRIGHT 2017, 2023
ALL RIGHTS RESERVED
_