Eleventh Class: Step One – ESI Communications
 Good review projects begin with ESI Communications, they begin with talking. You need to understand and articulate the disputed issues of fact. If you do not know what you are looking for, you will never find it. That does not mean you know of specific documents. If you knew that, it would not be much of a search. It means you understand what needs to be proven at trial and what documents will have impact on judge and jury. It also means you know the legal bounds of relevance, including especially Rule 26(b)(1).
Good review projects begin with ESI Communications, they begin with talking. You need to understand and articulate the disputed issues of fact. If you do not know what you are looking for, you will never find it. That does not mean you know of specific documents. If you knew that, it would not be much of a search. It means you understand what needs to be proven at trial and what documents will have impact on judge and jury. It also means you know the legal bounds of relevance, including especially Rule 26(b)(1).

ESI Communications begin and end with the scope of the discovery, relevance and related review procedures. The communications are not only with opposing counsel or other requesting parties, but also with the client and the e-discovery team assigned to the case. These Talks should be facilitated by the lead e-Discovery specialist attorney assigned to the case. But they should include the active participation of the whole team, including all trial lawyers not otherwise very involved in the ESI review.
The purpose of all of this Talk is to give everyone an idea as to the documents sought and the confidentiality protections and other special issues involved. Good lines of communication are critical to that effort. This first step can sometimes be difficult, especially if there are many new members to the group. Still, a common understanding of relevance, the target searched, is critical to the successful outcome of the search. This includes the shared wisdom that the understanding of relevance will evolve and grow as the project progresses.
![]() We need to Talk to understand what we are looking for. What is the target? What is the information need? What documents are relevant? What would a hot document look like? A common understanding of relevance by a review team, of what you are looking for, requires a lot of communication. Silent review projects are doomed to failure. They tend to stagnate and do not enjoy the benefits of Concept Drift, where a team’s understanding of relevance is refined and evolves as the review progresses. Yes, the target may move, and that is a good thing. See: Concept Drift and Consistency: Two Keys To Document Review Quality – Parts One, Two and Three.
We need to Talk to understand what we are looking for. What is the target? What is the information need? What documents are relevant? What would a hot document look like? A common understanding of relevance by a review team, of what you are looking for, requires a lot of communication. Silent review projects are doomed to failure. They tend to stagnate and do not enjoy the benefits of Concept Drift, where a team’s understanding of relevance is refined and evolves as the review progresses. Yes, the target may move, and that is a good thing. See: Concept Drift and Consistency: Two Keys To Document Review Quality – Parts One, Two and Three.
 Review projects are also doomed where the communications are one way, lecture down projects where only the SME talks. The reviewers must talk back, must ask questions. The input of reviewers is key. Their questions and comments are very important. Dialogue and active listening are required for all review projects, including ones with predictive coding.
Review projects are also doomed where the communications are one way, lecture down projects where only the SME talks. The reviewers must talk back, must ask questions. The input of reviewers is key. Their questions and comments are very important. Dialogue and active listening are required for all review projects, including ones with predictive coding.
You begin with analysis and discussions with your client, your internal team, and then with opposing counsel, as to what it is you are looking for and what the requesting party is looking for. The point is to clarify the information sought, the target. You cannot just stumble around and hope you will know it when you find it (and yet this happens all too often). You must first know what you are looking for. The target of most searches is the information relevant to disputed issues of fact in a case or investigation. But what exactly does that mean? If you encounter unresolvable disputes with opposing counsel on the scope of relevance, which can happen during any stage of the review despite your best efforts up-front, you may have to include the Judge in these discussions and seek a ruling.
Here is my video explaining the first step of ESI Communications.
________
______
 “ESI Discovery Communications” is about talking to your review team, including your client, key witnesses; it is about talking to opposing counsel; and, eventually, if need be, talking to the judge at hearings. Friendly, informal talk is a good method to avoid the tendency to polarize and demonize “the other side,” to build walls and be distrustful and silent.
“ESI Discovery Communications” is about talking to your review team, including your client, key witnesses; it is about talking to opposing counsel; and, eventually, if need be, talking to the judge at hearings. Friendly, informal talk is a good method to avoid the tendency to polarize and demonize “the other side,” to build walls and be distrustful and silent.
 The amount of distrust today between attorneys is at an all-time high. This trend must be reversed. Mutually respectful talk is part of the solution. Slowing things down helps too. Do not respond to a provocative text or email until you calm down. Take your time to ponder any question, even if you are not upset. Take your time to research and consult with others first. This point is critical. The demand for instant answers is never justified, nor required under the rules of civil procedure. Think first and never respond out of anger. We are all entitled to mutual respect. You have a right to demand that. So do they.
The amount of distrust today between attorneys is at an all-time high. This trend must be reversed. Mutually respectful talk is part of the solution. Slowing things down helps too. Do not respond to a provocative text or email until you calm down. Take your time to ponder any question, even if you are not upset. Take your time to research and consult with others first. This point is critical. The demand for instant answers is never justified, nor required under the rules of civil procedure. Think first and never respond out of anger. We are all entitled to mutual respect. You have a right to demand that. So do they.
 This point about not actually speaking with people in realtime, in person, or by phone or video, is, to some extent, generational. Many younger attorneys seem to have an inherent loathing of the phone and speaking out loud. They let their thumbs do the talking. (This is especially true in e-discovery where the professionals involved tend to be very computer oriented, not people oriented. I know because I am like that.) Meeting in person in real-time is distasteful to many, not just Gen X. Many of us prefer to put everything in emails and texts and tweets and posts, etc. That may make it easier to pause to reflect, especially if you are loathe to say in person that you do not know and will need to get back to them on that. But real time talking is important to full communication. You may need to force yourself to real-time interpersonal interactions. Many people are better at real-time talk than others, just like many are better at fast comprehension of documents than others. It is often a good idea for a team to have a designated talker, especially when it comes to speaking with opposing counsel or the client.
This point about not actually speaking with people in realtime, in person, or by phone or video, is, to some extent, generational. Many younger attorneys seem to have an inherent loathing of the phone and speaking out loud. They let their thumbs do the talking. (This is especially true in e-discovery where the professionals involved tend to be very computer oriented, not people oriented. I know because I am like that.) Meeting in person in real-time is distasteful to many, not just Gen X. Many of us prefer to put everything in emails and texts and tweets and posts, etc. That may make it easier to pause to reflect, especially if you are loathe to say in person that you do not know and will need to get back to them on that. But real time talking is important to full communication. You may need to force yourself to real-time interpersonal interactions. Many people are better at real-time talk than others, just like many are better at fast comprehension of documents than others. It is often a good idea for a team to have a designated talker, especially when it comes to speaking with opposing counsel or the client.
In e-discovery, where the knowledge levels are often extremely different, with one side knowing more about the subject than the other, the fist step of ESI Communications or Talk usually requires patient explanations. ESI Communications often require some amount of educational efforts by the attorneys with greater expertise. The trick is to do that without being condescending or too pedantic, and, in my case at least, without losing your patience.
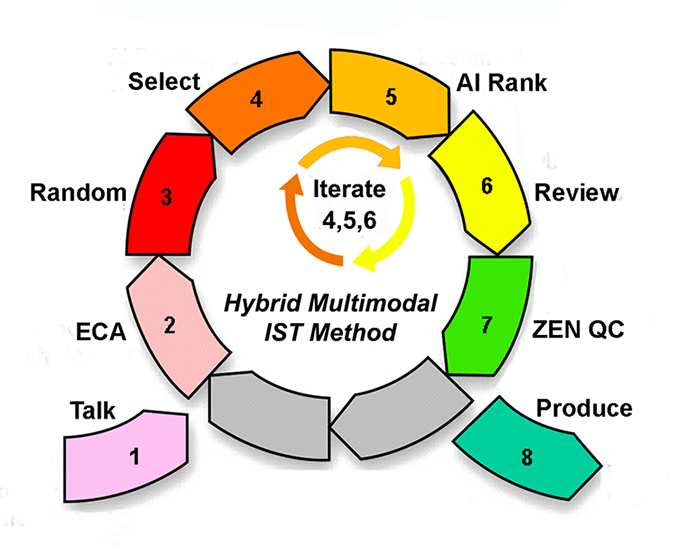
Some object to the whole idea of helping opposing counsel by educating them, but the truth is, this helps your clients too. You are going to have to explain everything when you take a dispute to the judge, so you might as well start upfront. It helps save money and moves the case along. Trust building is a process best facilitated by honest, open talk.
 I use of the term Talk to invoke the term listen as well. That is one reason we also refer to the first step as “Relevance Dialogues” because that is exactly what it should be, a back and forth exchange. Top down lecturing is not intended here. Even when a judge talks, where the relationship is truly top down, the judge always listens before rendering his or her decision. You are given the right to be heard at a hearing, to talk and be listened to. Judges listen a lot and usually ask many questions. Attorneys should do the same. Never just talk to hear the sound of your own voice. As Judge David Waxse likes to say, talk to opposing counsel as if the judge were listening.
I use of the term Talk to invoke the term listen as well. That is one reason we also refer to the first step as “Relevance Dialogues” because that is exactly what it should be, a back and forth exchange. Top down lecturing is not intended here. Even when a judge talks, where the relationship is truly top down, the judge always listens before rendering his or her decision. You are given the right to be heard at a hearing, to talk and be listened to. Judges listen a lot and usually ask many questions. Attorneys should do the same. Never just talk to hear the sound of your own voice. As Judge David Waxse likes to say, talk to opposing counsel as if the judge were listening.
 The same rules apply when communicating about discovery with the judge. I personally prefer in-person hearings, or at least telephonic, as opposed to just throwing memos back and forth. This is especially true when the memorandums have very short page limits. Dear Judges: e-discovery issues are important and can quickly spiral out of control without your prompt attention. Please give us the hearings and time needed. Issuing easy orders that just split the baby will do nothing but pour gas on a fire.
The same rules apply when communicating about discovery with the judge. I personally prefer in-person hearings, or at least telephonic, as opposed to just throwing memos back and forth. This is especially true when the memorandums have very short page limits. Dear Judges: e-discovery issues are important and can quickly spiral out of control without your prompt attention. Please give us the hearings and time needed. Issuing easy orders that just split the baby will do nothing but pour gas on a fire.
In my many years of lawyering I have found that hearings and meetings are much more effective than exchanging papers. Dear brothers and sisters in the BAR: stop hating, stop distrusting and vilifying, and start talking to each other. That means listening too. Understand the other-side. Be professional. Try to cooperate. And stop taking extreme positions that assume the judge will just split the baby.
 It bears emphasis that by Talk in this first step we intend dialogue. A true back and forth. We do not intend argument, nor winners and losers. We do intend mutual respect. That includes respectful disagreement, but only after we have heard each other out and understood our respective positions. Then, if our talks with the other side have reached an impasse, at least on some issues, we request a hearing from the judge and set out the issues for the judge to decide. That is how our system of justice and discovery are designed to work. If you fail to talk, you not only doom the document review project, you doom the whole case to unnecessary expense and frustration.
It bears emphasis that by Talk in this first step we intend dialogue. A true back and forth. We do not intend argument, nor winners and losers. We do intend mutual respect. That includes respectful disagreement, but only after we have heard each other out and understood our respective positions. Then, if our talks with the other side have reached an impasse, at least on some issues, we request a hearing from the judge and set out the issues for the judge to decide. That is how our system of justice and discovery are designed to work. If you fail to talk, you not only doom the document review project, you doom the whole case to unnecessary expense and frustration.
 This dialogue method is based on a Cooperative approach to discovery that was promoted by the late, great Richard Braman of The Sedona Conference. Cooperation is not only a best practice, but is, to a certain extent, a minimum standard required by rules of professional ethics and civil procedure. The primary goal of these dialogues for document review purposes is to obtain a common understanding of the e-discovery requests and reach agreement on the scope of relevancy and production.
This dialogue method is based on a Cooperative approach to discovery that was promoted by the late, great Richard Braman of The Sedona Conference. Cooperation is not only a best practice, but is, to a certain extent, a minimum standard required by rules of professional ethics and civil procedure. The primary goal of these dialogues for document review purposes is to obtain a common understanding of the e-discovery requests and reach agreement on the scope of relevancy and production.
ESI Communications in this first step may, in some cases, require disclosure of the actual search techniques used, which is traditionally protected by work product. The disclosures may also sometimes include limited disclosure of some of the training documents used, typically just the relevant documents. S ee Judge Andrew Peck’s 2015 ruling on predictive coding, Rio Tinto v. Vale, 2015 WL 872294 (March 2, 2015, SDNY). In Rio Tinto Judge Peck wisely modified somewhat his original views stated in Da Silva on the issue of disclosure. Moore v. Publicis Groupe, 2012 WL 607412 (S.D.N.Y. Feb. 24, 2012) (approved and adopted in Da Silva Moore v. Publicis Groupe, 2012 WL 1446534, at *2 (S.D.N.Y. Apr. 26, 2012)). Judge Peck no longer thinks that parties should necessarily disclose any training documents, and may instead:
ee Judge Andrew Peck’s 2015 ruling on predictive coding, Rio Tinto v. Vale, 2015 WL 872294 (March 2, 2015, SDNY). In Rio Tinto Judge Peck wisely modified somewhat his original views stated in Da Silva on the issue of disclosure. Moore v. Publicis Groupe, 2012 WL 607412 (S.D.N.Y. Feb. 24, 2012) (approved and adopted in Da Silva Moore v. Publicis Groupe, 2012 WL 1446534, at *2 (S.D.N.Y. Apr. 26, 2012)). Judge Peck no longer thinks that parties should necessarily disclose any training documents, and may instead:
… insure that training and review was done appropriately by other means, such as statistical estimation of recall at the conclusion of the review as well as by whether there are gaps in the production, and quality control review of samples from the documents categorized as non-responsive. See generally Grossman & Cormack, Comments, supra, 7 Fed. Cts. L.Rev. at 301-12.
The Court, however, need not rule on the need for seed set transparency in this case, because the parties agreed to a protocol that discloses all non-privileged documents in the control sets. (Attached Protocol, ¶¶ 4(b)-(c).) One point must be stressed — it is inappropriate to hold TAR to a higher standard than keywords or manual review. Doing so discourages parties from using TAR for fear of spending more in motion practice than the savings from using TAR for review.
Id. at *3. Also see Rio Tinto v. Vale, Stipulation and Order Re: Revised Validation and Audit Protocols for the use of Predictive Coding in Discovery, 14 Civ. 3042 (RMB) (AJP), (order dated 9/2/15 by Maura Grossman, Special Master, and adopted and ordered by Judge Peck on 9/8/15).
Judge Peck here follows the current prevailing view on disclosure that I also endorse. Disclose the relevant documents used in active machine learning, but not the irrelevant documents used in training. If there are borderline, grey area documents classified as irrelevant, you may need to disclose these type of documents by description, not actual production. Again, talk to the requesting party on where you are drawing the line. Talk about the grey area documents that you encounter. If they disagree, ask for a ruling before your training is complete.

The goals of Rule 1 of the Federal Rules of Civil Procedure (just, speedy and inexpensive) are impossible in all phases of litigation, not just discovery, unless attorneys communicate with each other. The parties may hate each other and refuse to talk. That sometimes happens. But the attorneys must be above the fray. That is a key purpose and function of an attorney in a dispute. It is sad that so many attorneys do not seem to understand that. If you are faced with such an attorney, my best advice is to lead by example, document the belligerence and seek the help of your presiding judge.
 Although Talk to opposing counsel is important, even more important is talking within the team. It is an important method of quality control and efficient project management. Everyone needs to be on the same page of relevance and discoverability. Work needs to be coordinated. Internal team Talk needs to be very close. Although a Vulcan mind meld might be ideal, it is not really necessary. Still, during a project a steady flow of talk, usually in the form of emails or chats, is normal and efficient. Clients should never complain about time spent communicating to manage a document review project. It can save a tremendous amount of money in the long run, so long as it is focused on the task at hand.
Although Talk to opposing counsel is important, even more important is talking within the team. It is an important method of quality control and efficient project management. Everyone needs to be on the same page of relevance and discoverability. Work needs to be coordinated. Internal team Talk needs to be very close. Although a Vulcan mind meld might be ideal, it is not really necessary. Still, during a project a steady flow of talk, usually in the form of emails or chats, is normal and efficient. Clients should never complain about time spent communicating to manage a document review project. It can save a tremendous amount of money in the long run, so long as it is focused on the task at hand.
Or pause to do this suggested “homework” assignment for further study and analysis.
SUPPLEMENTAL READING: To master document review, including especially the Predictive Coding 4.0 method taught here, you must have a complete and deep understanding of relevance under Rule 26(b)(1). You must understand the impact of this rule, and Rule 1, on relevance, especially on the grey area documents where you are unsure of probative value. There are many articles on relevance and Rule 26(b)(1), but focus on those that were written about or after the December 2015 FRCP revisions. Pay special attention to the many judicial opinions written after 2015 where the revised rule is interpreted and applied.
We recommend that you read all of the articles, web-links and cases cited in this class that you have not previously studied, including Concept Drift and Consistency: Two Keys To Document Review Quality –Parts One, Two and Three.
EXERCISES: Have you ever considered the difference between argument and dialogue? The Sedona Conference is, of course, well-known for promoting dialogue and discouraging arguments during their conferences. Suggest you do some general research on what is meant by dialogue. You will find that it is a very loaded word, referring to a method of group communication used by many different types of organizations, not just Sedona. Research related subjects too, such as active listening, body language, subliminal emotional reactions and reading between the lines. Try out the listening and talking approaches described in these writings. Try them with your family and friends. Try them in your next meeting for document reviews. Notice how elusive and difficult it can be to obtain clear, effective, multilevel communication. Notice how some people seem incapable of this, or are unwilling to participate at all for one reason or another. How do you deal with that? How do you make sure your entire team is with you and understands the review plan and what they are expected to do? Notice how hard it is to just listen, to simply try to understand another’s position without, at the same time, formulating a criticism or counter-point.
Have you formulated any good techniques to deal with oppressive opposing counsel, you know the kind, the ones who are extremely difficult to talk to for a variety of reasons? The ones that leave you exhausted and frustrated, where ten minutes seems like ten hours. If so, please share your best techniques with us in the comments section. Avoidance is effective, but can only take you so far.
Students are invited to leave a public comment below. Insights that might help other students are especially welcome. Let’s collaborate!
_
e-Discovery Team LLC COPYRIGHT 2017
ALL RIGHTS RESERVED
_
I sometimes pretend that “difficult” people like those described in the last exercise are simply mentally or physically ill, or both. That helps me to detach, rather than be provoked or react emotionally. That does not mean give-in to them. Do not do that. It just encourages them. Calm firm statements of your positions are all that are necessary. Never let a maniac know that you have any hot buttons, much less let them push your buttons.