 Notice to all TAR students and anyone else who might be interested in my latest thoughts on AI-enhanced document review, new material has been added to the e-Discovery Team’s TAR Course. The new content includes two video lectures that provide examples of applications of the methods taught. One new video is placed at the end of Class 13 on Random Prevalence. That is Step Three in the standard eight-part work flow. The other more lengthy video is at the end of Class 14 on Steps Four, Five and Six. This video provides an example of the iterated training cycle.
Notice to all TAR students and anyone else who might be interested in my latest thoughts on AI-enhanced document review, new material has been added to the e-Discovery Team’s TAR Course. The new content includes two video lectures that provide examples of applications of the methods taught. One new video is placed at the end of Class 13 on Random Prevalence. That is Step Three in the standard eight-part work flow. The other more lengthy video is at the end of Class 14 on Steps Four, Five and Six. This video provides an example of the iterated training cycle.
Class Fourteen is the longest, most difficult class in the Course. It could be broken down into three, easier to manage classes. But the three iterated steps 4-5-6 do go together, so logically they should be taught together in one long class. In the new video for this class, which is shown in two parts due to length, Ralph gives an example of this workflow and also discusses quality control. The video refers to a new graphic added, a screen shot of an actual case we handled. New text was also added to explain the folder naming protocol we typically use to keep track of our search activities in predictive coding projects.
You can go to the classes themselves, Class 13 and Class 14, where you will find the new materials at the end. Or you can keep reading here where the new material added is reproduced in full.
Thirteenth Class: Step Three – Random Prevalence
We close this class with an example to illustrate how this prevalence step works. Below is a screen shot of a project Ralph was working on in 2017 using KrolLDiscovery software. In the video that follows Ralph explains the prevalence calculation made in that case and how it helped guide his efforts. You will see another video discussing this case at the end of the next class.

By the way, Ralph misspoke in the video at point 8:39 when he said 95% confidence interval, he meant to say 95% confidence level. The random sample of 1,535 documents created a probability of 95% +/- 2.5%, meaning a 95% confidence level subject to an error range or interval of plus or minus 2.5%.
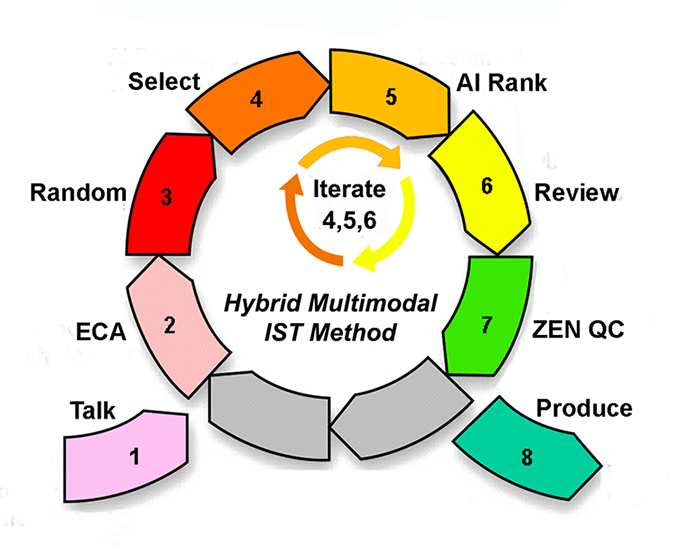
Fourteenth Class: Steps Four, Five and Six – Iterate
Concluding Case Example
 We conclude this class with a two-part video where Ralph illustrates the 4-5-6 steps taken on a particular case. The same case was discussed in the last class. Just above his video is the screen shot of the various document directories that he named to record his efforts up to the eleventh round of training. Each directory contains the actual documents referenced and details of the search itself, what you could call the search metadata. (Those are not shown in the screen shot.) Each directory may also contain multiple sub-directories of documents that illustrate other searches. The directories can further nest as per standard computer protocols.
We conclude this class with a two-part video where Ralph illustrates the 4-5-6 steps taken on a particular case. The same case was discussed in the last class. Just above his video is the screen shot of the various document directories that he named to record his efforts up to the eleventh round of training. Each directory contains the actual documents referenced and details of the search itself, what you could call the search metadata. (Those are not shown in the screen shot.) Each directory may also contain multiple sub-directories of documents that illustrate other searches. The directories can further nest as per standard computer protocols.
 This kind of directory naming protocol serves to document the key procedures you followed. It is an outline of your work-flow. Each directory contains the electronic files you retrieved by each procedure. This makes it easier to refresh your memory and quickly access the underlying documents found from different searches. You can, if need be, also contemporaneously create a detailed memorandum that further documents each step. We sometimes do so in special cases, but here we only used this far-quicker folder naming protocol and did not also create a memorandum to file. We do this largely as a cost and time-savings measure. The preparation of a full, detailed narrative of work flow can become quite time consuming and expensive. Whereas using this protocol to create a running record of your activities takes comparatively little time.
This kind of directory naming protocol serves to document the key procedures you followed. It is an outline of your work-flow. Each directory contains the electronic files you retrieved by each procedure. This makes it easier to refresh your memory and quickly access the underlying documents found from different searches. You can, if need be, also contemporaneously create a detailed memorandum that further documents each step. We sometimes do so in special cases, but here we only used this far-quicker folder naming protocol and did not also create a memorandum to file. We do this largely as a cost and time-savings measure. The preparation of a full, detailed narrative of work flow can become quite time consuming and expensive. Whereas using this protocol to create a running record of your activities takes comparatively little time.
 It is important for quality control purposes to keep a history of your work like this, even if it is just in outline form. The folder histories we create are fairly short and abbreviated, as you can see, but they were originally far less detailed than this. We have found that this level of detail of work description, combined with the actual documents, makes it easier to analyze your efforts and decide what to do next. Yes, it takes some time to do this, and slows your work a little bit, but it is well worth the efforts from the gains in quality that you will achieve.
It is important for quality control purposes to keep a history of your work like this, even if it is just in outline form. The folder histories we create are fairly short and abbreviated, as you can see, but they were originally far less detailed than this. We have found that this level of detail of work description, combined with the actual documents, makes it easier to analyze your efforts and decide what to do next. Yes, it takes some time to do this, and slows your work a little bit, but it is well worth the efforts from the gains in quality that you will achieve.
As an added benefit, this kind of history also strengthens the defensability of your efforts. Although we are almost never challenged, if we were, we could easily recreate and explain our actions. That kind of evidence could be required in exceptional circumstances to prove that reasonable efforts were made under Rule 26(g) Federal Rules of Civil Procedure or other rules and law. As you might imagine, Losey can testify for hours, if need be, on predictive coding and the 4.0 methods that were followed in a particular case in which he was involved. He would provide this testimony by relying on his memory, refreshed by contemporaneous notes like you see in the screen shot below. You can do the same.

____
____
_
e-Discovery Team LLC COPYRIGHT 2017
ALL RIGHTS RESERVED
_