 This is an introductory course on document review and predictive coding as used by Ralph Losey and his e-Discovery Teams in complex document reviews. [Published previously in seven parts and consolidated here.] The eight-step workflow is explained in seven videos totaling one hour and ten minutes. There are introductions for each video, which provide a total of 2,982 written words. Altogether this course provides a fairly detailed overview of the Team’s Hybrid Multimodal Method of document review.
This is an introductory course on document review and predictive coding as used by Ralph Losey and his e-Discovery Teams in complex document reviews. [Published previously in seven parts and consolidated here.] The eight-step workflow is explained in seven videos totaling one hour and ten minutes. There are introductions for each video, which provide a total of 2,982 written words. Altogether this course provides a fairly detailed overview of the Team’s Hybrid Multimodal Method of document review.
This first video addresses the big picture, why it is critical to our system of justice for the legal profession to keep up with technology, including especially active machine learning (predictive coding).
The flood of data now all too often hides the truth and frustrates justice. Cases tend to be decided on shadows, smoke and mirrors, because the key documents cannot be found. The needles of truth hide in vast haystacks in the clouds. Justice demands the truth, the full truth, not some bastardized twitter version.
 The use of AI in legal search can change that. It can empower lawyers to find the needles and decide cases on what really happened, and do so quickly and inexpensively. It can usher in a new age of greater justice for all, blind to wealth and power. The stability of society demands nothing less.
The use of AI in legal search can change that. It can empower lawyers to find the needles and decide cases on what really happened, and do so quickly and inexpensively. It can usher in a new age of greater justice for all, blind to wealth and power. The stability of society demands nothing less.
 The videos after this introduction are more technical. They delve into details of the work flow and show that it is easier than you might think. After all, only two of the eight steps (four and six) are unique to document reviews that use predictive coding. The others are found in any large scale review project, or should be.
The videos after this introduction are more technical. They delve into details of the work flow and show that it is easier than you might think. After all, only two of the eight steps (four and six) are unique to document reviews that use predictive coding. The others are found in any large scale review project, or should be.
For a more systematic explanation of the methods and eight-steps see Predictive Coding 3.0. Still more information on predictive coding and electronic document review can be found in the fifty-six articles published here on the topic since 2011.
________
_______
STEP ONE
 This second video begins an explanation of the e-Discovery Team’s eight-step work flow by talking about the first step, ESI Discovery Communications.
This second video begins an explanation of the e-Discovery Team’s eight-step work flow by talking about the first step, ESI Discovery Communications.
Good review projects begin in talk. You need to understand and articulate the disputed issues of fact. If you do not know what you are looking for, you will never find it. That does not mean you know of specific documents. If you knew that, it would not be much of a search. It means you know the bounds of relevance, you understand what needs to be proven at trial, and what documents will have impact on judge and jury.
![]() What is the target? What is the information need? What documents are relevant? What would a hot document look like? A common understanding of relevance by a review team, of what you are looking for, requires a lot of talk. Silent review projects are doomed to failure. They tend to stagnate and do not enjoy the benefits of Concept Drift, where a team’s understanding of relevance is refined and evolves as the review progresses. Yes, the target may move, and that is a good thing. See: Concept Drift and Consistency: Two Keys To Document Review Quality – Parts One, Two and Three.
What is the target? What is the information need? What documents are relevant? What would a hot document look like? A common understanding of relevance by a review team, of what you are looking for, requires a lot of talk. Silent review projects are doomed to failure. They tend to stagnate and do not enjoy the benefits of Concept Drift, where a team’s understanding of relevance is refined and evolves as the review progresses. Yes, the target may move, and that is a good thing. See: Concept Drift and Consistency: Two Keys To Document Review Quality – Parts One, Two and Three.
 Review projects are also doomed where the communications are one way, lecture down projects where only the SME talks. The reviewers must talk back, must ask questions. The input of reviewers is key and their questions and comments are very important. Dialogue and active listening are required for all review projects, including ones with predictive coding.
Review projects are also doomed where the communications are one way, lecture down projects where only the SME talks. The reviewers must talk back, must ask questions. The input of reviewers is key and their questions and comments are very important. Dialogue and active listening are required for all review projects, including ones with predictive coding.
________
______
STEP TWO
 This video talks about the second step of the e-Discovery Team’s eight-step work flow, Multimodal Search Review.
This video talks about the second step of the e-Discovery Team’s eight-step work flow, Multimodal Search Review.
After you understand the initial scope of relevance, you start to use all of the search tools you have, excluding only predictive coding, to create the first round of training documents. This is an exercise in early case assessment where you locate the low hanging fruit, the documents that are easy to find with keyword search, some linear review, similarity searches, including email string searches, and maybe even some concept searches. This is depicted in the first four levels of the search pyramid below.

Again, nothing new here. This is done in all review projects, except for the truly archaic ones that only use linear review, the expert manual review at the base of the search pyramid.
Before you can begin the predictive coding steps four and six, you have to find some relevant documents using other types of search. The relevant documents found in step two are then used to begin to teach the machine in step four. You do not need to find any particular minimum number of documents for the training to begin. Just go for what is easy to find. In the process you start to get a better understanding of the custodians, their data and relevance. That is what early case assessment is all about. You will find the rest of the still hidden relevant documents in the iterated rounds of machine training and other searches that follow.
You can continue using multiple forms of search in the following iterated rounds as the AI training evolves. Step Five is essentially a repeat of Step Two, except that in Step Five you can also use document ranking created in Step Four as an additional type of search.
______
_______
STEP THREE
 This video talks about the third step of the e-Discovery Team’s eight-step work flow, Random Baseline Sample.
This video talks about the third step of the e-Discovery Team’s eight-step work flow, Random Baseline Sample.
 Although this text intro is overly long, the video itself is short, under eight minutes, as there is really not that much to this step. You simply take a random sample at or near the beginning of the project. Again, this step can be used in any document review project, not just ones with predictive coding. You do this to get some sense of the prevalence of relevant documents in the data collection. That just means the sample will give you an idea as to the total number of relevant documents. You do not take the sample to set up a secret control set, a practice that has been thoroughly discredited by our Team and others. See Predictive Coding 3.0.
Although this text intro is overly long, the video itself is short, under eight minutes, as there is really not that much to this step. You simply take a random sample at or near the beginning of the project. Again, this step can be used in any document review project, not just ones with predictive coding. You do this to get some sense of the prevalence of relevant documents in the data collection. That just means the sample will give you an idea as to the total number of relevant documents. You do not take the sample to set up a secret control set, a practice that has been thoroughly discredited by our Team and others. See Predictive Coding 3.0.
 If you understand sampling statistics you know that sampling like this produces a range, not an exact number. If your sample size is small, then the range will be very high. If you want to reduce your range in half, which is a function in statistics known as a confidence interval, you have to quadruple your sample size. This is a general rule of thumb that I explained in tedious mathematical detail several years ago in Random Sample Calculations And My Prediction That 300,000 Lawyers Will Be Using Random Sampling By 2022. Our Team likes to use a fairly large sample size of about 1,533 documents that creates a confidence interval of plus or minus 2.5%, subject to a confidence level of 95% (meaning the true value will lie within that range 95 times out of 100). More information on sample size is summarized in the graph below. Id.
If you understand sampling statistics you know that sampling like this produces a range, not an exact number. If your sample size is small, then the range will be very high. If you want to reduce your range in half, which is a function in statistics known as a confidence interval, you have to quadruple your sample size. This is a general rule of thumb that I explained in tedious mathematical detail several years ago in Random Sample Calculations And My Prediction That 300,000 Lawyers Will Be Using Random Sampling By 2022. Our Team likes to use a fairly large sample size of about 1,533 documents that creates a confidence interval of plus or minus 2.5%, subject to a confidence level of 95% (meaning the true value will lie within that range 95 times out of 100). More information on sample size is summarized in the graph below. Id.

The picture below this paragraph illustrates a data cloud where the yellow dots are the sampled documents from the grey dot total, and the hard to see red dots are the relevant documents found in that sample. Although this illustration is from a real project we had, it shows a dataset that is unusual in legal search because the prevalence here was high, between 22.5% and 27.5%. In most data collections searched in the law today, where the custodian data has not been filtered by keywords, the prevalence is far less than that, typically less than 5%, maybe even less that 0.5%. The low prevalence increases the range size, the uncertainties, and requires a binomial calculation adjustment to determine the statistically valid confidence interval, and thus the true document range.
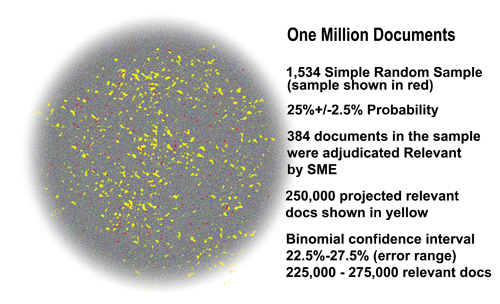
For example, in a typical legal project with a few percent prevalence range, it would be common to see a range between 20,000 and 60,000 relevant documents in a 1,000,000 collection. Still, even with this very large range, we find it useful to at least have some idea of the number of documents they are looking for. That is what the Baseline Step can provide to you, nothing more nor less.
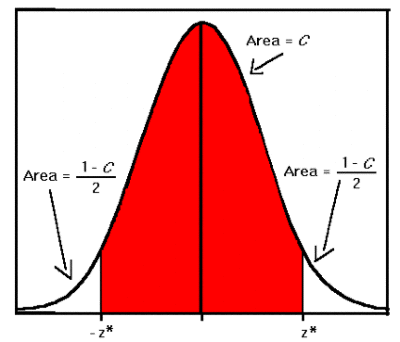
 If you are unsure of how to do sampling for prevalence estimates, your vendor can probably help. Just do not let them tell you that it is one exact number. That is simply a point projection near the middle of a range. The one number point projection is just the top of the typical probability bell curve shown above, which illustrates a 95% confidence level distribution. The top is just one possibility, albeit slightly more likely than either end points. The true value could be anywhere in the blue range.
If you are unsure of how to do sampling for prevalence estimates, your vendor can probably help. Just do not let them tell you that it is one exact number. That is simply a point projection near the middle of a range. The one number point projection is just the top of the typical probability bell curve shown above, which illustrates a 95% confidence level distribution. The top is just one possibility, albeit slightly more likely than either end points. The true value could be anywhere in the blue range.
To repeat, the Step Three prevalence baseline number is always a range, never just one number. Going back to the relatively high prevalence example, the below bell cure shows a point projection of 25% prevalence, with a range of 22.2% and 27.5%, creating a range of relevant documents of from between 225,000 and 275,000. This is shown below.

 The important point that many vendors and other “experts” often forget to mention, is that you can never know exactly where within that range the true value may lie. Plus, there is always a small possibility, 5% when using a sample size based on a 95% confidence level, that the true value may fall outside of that range. It may, for example, only have 200,000 relevant documents. This means that even with a high prevalence project with datasets that approach the Normal Distribution of 50% (here meaning half of the documents are relevant), you can never know that there are exactly 250,000 documents, just because it is the mid-point or point projection. You can only know that there are between 225,000 and 275,000 relevant documents, and even that range may be wrong 5% of the time. Those uncertainties are inherent limitations to random sampling.
The important point that many vendors and other “experts” often forget to mention, is that you can never know exactly where within that range the true value may lie. Plus, there is always a small possibility, 5% when using a sample size based on a 95% confidence level, that the true value may fall outside of that range. It may, for example, only have 200,000 relevant documents. This means that even with a high prevalence project with datasets that approach the Normal Distribution of 50% (here meaning half of the documents are relevant), you can never know that there are exactly 250,000 documents, just because it is the mid-point or point projection. You can only know that there are between 225,000 and 275,000 relevant documents, and even that range may be wrong 5% of the time. Those uncertainties are inherent limitations to random sampling.
Shame on the vendors who still perpetuate that myth of certainty. Lawyers can handle the truth. We are used to dealing with uncertainties. All trial lawyers talk in terms of probable results at trial, and risks of loss, and often calculate a case’s settlement value based on such risk estimates. Do not insult our intelligence by a simplification of statistics that is plain wrong. Reliance on such erroneous point projections alone can lead to incorrect estimates as to the level of recall that we have attained in a project. We do not need to know the math, but we do need to know the truth.
The short video that follows will briefly explain the Random Baseline step, but does not go into the technical details of the math or statistics, such as the use of the binomial calculator for low prevalence. I have previously written extensively on this subject. See for instance:
- In Legal Search Exact Recall Can Never Be Known
- Random Sample Calculations And My Prediction That 300,000 Lawyers Will Be Using Random Sampling By 2022
- Borg Challenge: Part Two where I begin the search with a random sample (text and video)

If you prefer to learn stuff like this by watching cute animated robots, then you might like: Robots From The Not-Too-Distant Future Explain How They Use Random Sampling For Artificial Intelligence Based Evidence Search. But be careful, their view is version 1.0 as to control sets.
Thanks again to William Webber and other scientists in this field who helped me out over the years to understand the Bayesian nature of statistics (and reality).
_______
_____
STEPS FOUR, FIVE AND SIX
 This video talks about the fourth, fifth and sixth steps of the e-Discovery Team’s eight-step work flow. These are the iterated predictive coding steps proper. Step four is AI Predictive Rank, five is Document Review, and six is Hybrid Active Training. Here we get into the core of the predictive coding process proper. As you will see, it’s relatively easy.
This video talks about the fourth, fifth and sixth steps of the e-Discovery Team’s eight-step work flow. These are the iterated predictive coding steps proper. Step four is AI Predictive Rank, five is Document Review, and six is Hybrid Active Training. Here we get into the core of the predictive coding process proper. As you will see, it’s relatively easy.
 As this video explains, it has all become almost simple with Mr. EDR and its improved interfaces and smart algorithms. The whole machine training process has become easier over the last few years as we have tinkered with and refined the methods. (Tinkering is the original and still only true meaning of hacking. See: HackerLaw.org) At this point of the predictive coding lifecycle it is, for example, easier to learn how to do predictive coding than to learn how to do a trial – bench or jury. Interestingly,the most effective instruction method is similar – second chair apprenticeship, watch and learn. It is the way complex legal practices have always been taught. My team can teach it to any smart tech lawyer by having them second chair a couple of projects.
As this video explains, it has all become almost simple with Mr. EDR and its improved interfaces and smart algorithms. The whole machine training process has become easier over the last few years as we have tinkered with and refined the methods. (Tinkering is the original and still only true meaning of hacking. See: HackerLaw.org) At this point of the predictive coding lifecycle it is, for example, easier to learn how to do predictive coding than to learn how to do a trial – bench or jury. Interestingly,the most effective instruction method is similar – second chair apprenticeship, watch and learn. It is the way complex legal practices have always been taught. My team can teach it to any smart tech lawyer by having them second chair a couple of projects.
 It is interesting to note that medicine uses the same method to teach surgeons how to do complex robotic surgery, with a da Vinci surgical system, or the like. Whenever a master surgeon operates with robotics, there are always several doctors watching and assisting, more than are needed. In this photo they are the ones around the patient. The master surgeon who is actually controlling the tiny knifes in the patient is the guy on the far left sitting down with his head in the machine. He is looking at a magnified video picture of what is happening inside the patient’s body and moving the tiny knives around with a joystick.
It is interesting to note that medicine uses the same method to teach surgeons how to do complex robotic surgery, with a da Vinci surgical system, or the like. Whenever a master surgeon operates with robotics, there are always several doctors watching and assisting, more than are needed. In this photo they are the ones around the patient. The master surgeon who is actually controlling the tiny knifes in the patient is the guy on the far left sitting down with his head in the machine. He is looking at a magnified video picture of what is happening inside the patient’s body and moving the tiny knives around with a joystick.
 The hybrid human/robot system augments the human surgeon’s abilities. The surgeon has his hands on the wheel at all times. The other doctors may watch dozens, and if they are younger, maybe even hundreds of surgeries before they are allowed to take control of the joy stick and do the hard stuff. The predictive coding steps four, five and six are far easier than this, besides, if you screw up, nobody dies.
The hybrid human/robot system augments the human surgeon’s abilities. The surgeon has his hands on the wheel at all times. The other doctors may watch dozens, and if they are younger, maybe even hundreds of surgeries before they are allowed to take control of the joy stick and do the hard stuff. The predictive coding steps four, five and six are far easier than this, besides, if you screw up, nobody dies.
_______
_____
In after production QC I noticed one fact error at the 6:07 point in the video. I said that my Borg experiment review took me up to thirty rounds of training. In fact, it took exactly fifty rounds of training. Borg Challenge: Report of my experimental review of 699,082 Enron documents using a semi-automated monomodal methodology (a five-part written and video series comparing two different kinds of predictive coding search methods). I still cannot believe I spent fifty hours, and fifty rounds, on that predictive coding experiment. As you can see it took quite a toll of me physically to slog through that.

__________
STEP SEVEN

This video talks about step seven, ZEN Quality Assurance Tests, where ZEN stands for Zero Error Numerics. It is the quality control step that includes metrics and a number of other techniques to reduce and catch errors.
 The specific test we use on a predictive coding stop decision, one that we have found measures recall the best, is ei-Recall. It is a second random sample of all of the negatives in the dataset, the documents that you presume irrelevant and will not be human reviewed. The ei-Recall formula calculates recall as a range. The sampling test also contains an accept on zero error component, where the presence of even a single Highly Relevant document as a false positive automatically triggers more rounds of machine training. I have explained this in detail in Introducing “ei-Recall” – A New Gold Standard for Recall Calculations in Legal Search – Parts One, Two and Three. The formula and technique is also set forth on one page at ZeroErrorNumericcs.com.
The specific test we use on a predictive coding stop decision, one that we have found measures recall the best, is ei-Recall. It is a second random sample of all of the negatives in the dataset, the documents that you presume irrelevant and will not be human reviewed. The ei-Recall formula calculates recall as a range. The sampling test also contains an accept on zero error component, where the presence of even a single Highly Relevant document as a false positive automatically triggers more rounds of machine training. I have explained this in detail in Introducing “ei-Recall” – A New Gold Standard for Recall Calculations in Legal Search – Parts One, Two and Three. The formula and technique is also set forth on one page at ZeroErrorNumericcs.com.
Another important quality control technique, one used throughout a project, is the avoidance of all dual tasking, and learned, focused concentration, a flow-state, like an all-absorbing video game, movie, or a meditation.
 Speaking of relaxed, thought free, flow state, did you know that United States Supreme Court Justice Stephen Breyer is a regular meditator? In a CNN reporter interview in 2011 he said:
Speaking of relaxed, thought free, flow state, did you know that United States Supreme Court Justice Stephen Breyer is a regular meditator? In a CNN reporter interview in 2011 he said:
For 10 or 15 minutes twice a day I sit peacefully. I relax and think about nothing or as little as possible. … And really I started because it’s good for my health. My wife said this would be good for your blood pressure and she was right. It really works. I read once that the practice of law is like attempting to drink water from a fire hose. And if you are under stress, meditation – or whatever you choose to call it – helps. Very often I find myself in circumstances that may be considered stressful, say in oral arguments where I have to concentrate very hard for extended periods. If I come back at lunchtime, I sit for 15 minutes and perhaps another 15 minutes later. Doing this makes me feel more peaceful, focused and better able to do my work.”
 Apparently Steve Breyer also sometimes meditates with friends, including legendary Public Interest Lawyer, Professor and meditation promoter, Charles Halpern. Also see Halpern, Making Waves and Riding the Currents (2008) (his interesting autobiography); Charles Halpern on Empathy, Meditation, Barack Obama, Justice and Law (YouTube Interview in 2011 with interesting thoughts on judicial selection).
Apparently Steve Breyer also sometimes meditates with friends, including legendary Public Interest Lawyer, Professor and meditation promoter, Charles Halpern. Also see Halpern, Making Waves and Riding the Currents (2008) (his interesting autobiography); Charles Halpern on Empathy, Meditation, Barack Obama, Justice and Law (YouTube Interview in 2011 with interesting thoughts on judicial selection).
Document review is not as stressful as a Supreme Court oral argument, but it does go on far longer. Everybody needs to relax with a clear mind, and with focused attention, to attain their peak level of performance. That is the key to all quality control. How you get there is your business. Me, in addition to frequent breaks, I like headphones with music to help me there and help me to stay undistracted, focused. So, sit comfortably, spine erect, and enjoy this moment of ZEN.
_________
____
For more details on step seven see ZeroErrorNumericcs.com.
____________
STEP EIGHT

This last video talks about step eight in work flow, Phased Productions. This is also sometimes known as second pass review, where you identify confidential and privileged documents and take appropriate action of logging, redacting or fixing special legends on the face of Tiffed or PDF productions. You are probably already well acquainted with this step. Again this is fairly easy and straightforward. Here is my short, five-minute wrap up.
_________
____
For details on phased productions see Electronic Discovery Best Practices. For information on all eight steps see Predictive Coding 3.0. More information on document review and predictive coding can be found in the over fifty-six articles published here.
[…] EDBP Mr.EDR Predictive Coding 3.0 59 TAR Articles Doc Review Videos […]