Protected: E-DISCOVERY IS OVER: The big problems of e-discovery have now all been solved. Crises Averted. The Law now has bigger fish to fry.
July 30, 2017
 Enter your password to view comments. |
Enter your password to view comments. |  Evidence, informaton, knowledge, Lawyers Duties, New Rules, Related Legal Webs, Review, Search, Technology, VENDORS, wisdom | Tagged: best practices, discovery, edbp, education, ethics, justice, law, legal profession, legal search, machine learning, predictive coding, robot, robots, science, search, tar, technology, too much information, truth, vendors |
Evidence, informaton, knowledge, Lawyers Duties, New Rules, Related Legal Webs, Review, Search, Technology, VENDORS, wisdom | Tagged: best practices, discovery, edbp, education, ethics, justice, law, legal profession, legal search, machine learning, predictive coding, robot, robots, science, search, tar, technology, too much information, truth, vendors |  Permalink
Permalink
 Posted by Ralph Losey
Posted by Ralph Losey
Protected: Predictive Coding 4.0 – Nine Key Points of Legal Document Review and an Updated Statement of Our Workflow – Part Four
October 2, 2016
Enter your password to view comments. | informaton, knowledge, Lawyers Duties, Review, Search, Technology, VENDORS, wisdom | Tagged: best practices, computer assisted review, discovery, document review, legal profession, legal search, machine learning, predictive coding, robot, tar, technology, too much information, vendors | Permalink
Posted by Ralph Losey
Predictive Coding 4.0 – Nine Key Points of Legal Document Review and an Updated Statement of Our Workflow – Part Three
September 26, 2016This is the third installment of my lengthy article explaining the e-Discovery Team’s latest enhancements to electronic document review using Predictive Coding. Here are Parts One and Two. This series explains the nine insights (6+3) behind the latest upgrade to version 4.0 and the slight revisions these insights triggered to the eight-step workflow. This is all summarized by the diagram below, which you may freely copy and use if you make no changes.
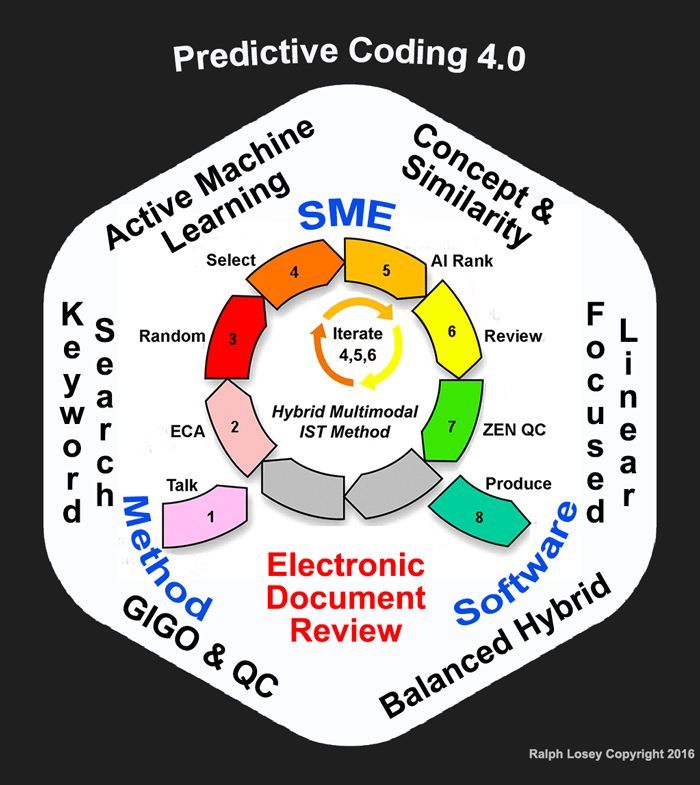
To summarize this series explains the seventeen points, listed below, where the first nine are insights and the last eight are workflow steps:
- Active Machine Learning (aka Predictive Coding)
- Concept & Similarity Searches (aka Passive Learning)
- Keyword Search (tested, Boolean, parametric)
- Focused Linear Search (key dates & people)
- GIGO & QC (Garbage In, Garbage Out) (Quality Control)
- Balanced Hybrid (man-machine balance with IST)
- SME (Subject Matter Expert, typically trial counsel)
- Method (for electronic document review)
- Software (for electronic document review)
- Talk (step 1 – relevance dialogues)
- ECA (step 2 – early case assessment using all methods)
- Random (step 3 – prevalence range estimate, not control sets)
- Select (step 4 – choose documents for training machine)
- AI Rank (step 5 – machine ranks documents according to probabilities)
- Review (step 6 – attorneys review and code documents)
- Zen QC (step 7 – Zero Error Numerics Quality Control procedures)
- Produce (step 8 – production of relevant, non-privileged documents)
So far in Part One of this series we explained how these insights came about and provided other general background. In Part Two we explained the first of the nine insights, Active Machine Learning, including the method of double-loop learning. In the process we introduced three more insights, Balanced Hybrid, Concept & Similarity Searches, and Software. For continuity purposes we will address Balanced Hybrid next. (I had hoped to cover many more of the seventeen in this third installment, but turns out it all takes more words than I thought.)
Balanced Hybrid
Using Intelligently Spaced Training – IST™
The Balanced Hybrid insight is complementary to Active Machine Learning. It has to do with the relationship between the human training the machine and the machine itself. The name itself says it all, namely that is it balanced. We rely on both software and skilled attorneys using the software.

We advocate reliance on the machine after it become trained, after it starts to understand your conception of relevance. At that point we find it very helpful to rely on what the machine has determined to be the documents most likely to be relevant. We have found it is a good way to improve precision in the sixth step of our 8-step document review methodology shown below. We generally use a balanced approach where we start off relying more on human selections of documents for training based on their knowledge of the case and other search selection processes, such as keyword or passive machine learning, a/k/a concept search. See steps 2 and 4 of our 8-step method – ECA and Select. Then we switch to relying more on the machine as it’s understanding catches one. See steps 4 and 5 – Select and AI Rank. It is usually balanced throughout a project with equal weight given to the human trainer, typically a skilled attorney, and the machine, a predictive coding algorithm of some time, typically logistic regression or support vector.
{kind=link}
Unlike other methods of Active Machine Learning we do not completely turn over to the machine all decisions as to what documents to review next. We look to the machine for guidance as to what documents should be reviewed next, but it is always just guidance. We never completely abdicate control over to the machine. I have gone into this before at some length in my article Why the ‘Google Car’ Has No Place in Legal Search. In this article I cautioned against over reliance on fully automated methods of active machine learning. Our method is designed to empower the humans in control, the skilled attorneys. Thus although our Hybrid method is generally balanced, our scale tips slightly in favor of humans, the team of attorneys who run the document review. We favor humans. So while we like our software very much, and have even named it Mr. EDR, we have an unabashed favoritism for humans. More on this at the conclusion of the Balanced Hybrid section of this article.

Three Factors That Influence the Hybrid Balance
We have shared the previously described hybrid insights before in earlier e-Discovery Team writings on predictive coding. The new insights on Balanced Hybrid are described in the rest of this segment. Again, they are not entirely new either. They represent more of a deepening of understanding and should be familiar to most document review experts. First, we have gained better insight into when and why the Balanced Hybrid approach should be tipped one way or another towards greater reliance on humans or machine. We see three factors that influence our decision.
- On some projects your precision and recall improves by putting greater reliance of the AI, on the machine. These are typically projects where one or more of the following conditions exist:
* the data itself is very complex and difficult to work with, such as specialized forum discussions; or,
* the search target is ill-defined, i.w. – no one is really sure what they are looking for; or,
* the Subject Matter Expert (SME) making final determinations on relevance has limited experience and expertise.
 2. On some projects your precision and recall improves by putting even greater reliance of the humans, on the skilled attorneys working with the machine. These are typically projects where the converse of one or more of the three criteria above are present:
2. On some projects your precision and recall improves by putting even greater reliance of the humans, on the skilled attorneys working with the machine. These are typically projects where the converse of one or more of the three criteria above are present:
* the data itself is fairly simple and easy to work with, such as a disciplined email user (note this has little or nothing to do with data volume) or,
* the search target is well-defined, i.w. there are clearly defined search requests and everyone is on the same page as to what they are looking for; or,
* the Subject Matter Expert (SME) making final determinations on relevance has extensive experience and expertise.
What was somewhat surprising from our 2016 TREC research is how one-sided you can go on the Human side of the equation and still attain near perfect recall and precision. The Jeb Bush email underlying all thirty of our topics in TREC Total Recall Track 2016 is, at this point, well-known to us. It is fairly simple and easy to work with. Although the spelling of the thousands of constituents who wrote to Jeb Bush was atrocious (far worse than general corporate email, except maybe construction company emails), Jeb’s use of the email was fairly disciplined and predictable. As a Florida native and lawyer who lived through the Jeb Bush era, and was generally familiar with all of the issues, and have become very familiar with his email, I have become a good SME, and, to a somewhat lesser extent, so has my whole team. (I did all ten of the Bush Topics in 2015 and another ten in 2016.) Also, we had fairly well-defined, simple search goals in most of the topics.
 For these reasons in many of these 2016 TREC document review projects the role of the machine and machine ranking became fairly small. In some that I handled it was reduced to a quality control, quality assurance method. The machine would pick up and catch a few documents that the lawyers alone had missed, but only a few. The machine thus had a slight impact on improved recall, but not much effect at all on precision, which was anyway very high. (More on this experience with easy search topics later in this essay when we talk about our Keyword Search insights.)
For these reasons in many of these 2016 TREC document review projects the role of the machine and machine ranking became fairly small. In some that I handled it was reduced to a quality control, quality assurance method. The machine would pick up and catch a few documents that the lawyers alone had missed, but only a few. The machine thus had a slight impact on improved recall, but not much effect at all on precision, which was anyway very high. (More on this experience with easy search topics later in this essay when we talk about our Keyword Search insights.)
On a few of the 2016 TREC Topics the search targets were not well-defined. On these Topics our SME skills were necessarily minimized. Thus in these few Topics, even though the data itself was simple, we had to put greater reliance on the machine (in our case Mr. EDR) than on the attorney reviewers.
It bears repeating that the volume of emails has nothing to do with the ease or difficulty of the review project. This is a secondary question and is not dispositive as to how much weight you need to give to machine ranking. (Volume size may, however, have a big impact on project duration.)
We use IST, Not CAL
 Another insight in Balanced Hybrid in our new version 4.0 of Predictive Coding is what we call Intelligently Spaced Training, or IST™. See Part Two of this series for more detail on IST. We now use the term IST, instead of CAL, for two reasons:
Another insight in Balanced Hybrid in our new version 4.0 of Predictive Coding is what we call Intelligently Spaced Training, or IST™. See Part Two of this series for more detail on IST. We now use the term IST, instead of CAL, for two reasons:
1. Our previous use of the term CAL was only to refer to the fact that our method of training was continuous, in that it continued and was ongoing throughout a document review project. The term CAL has come to mean much more than that, as will be explained, and thus our continued use of the term may cause confusion.
2. Trademark rights have recently been asserted by Professors Grossman and Cormack, who originated this acronym CAL. As they have refined the use of the mark it now not only stands for Continuous Active Learning throughout a project, but also stands for a particular method of training that only uses the highest ranked documents.
Under the Grossman-Cormack CAL method the machine training continues throughout the document review project, as it does under our IST method, but there the similarities end. Under their CAL method of predictive coding the machine trains automatically as soon as a new document is coded. Further, the document or documents are selected by the software itself. It is a fully automatic process. The only role of the human is to say yes or no as to relevance of the document. The human does not select which document or documents to review next to say yes or no to. That is controlled by the algorithm, the machine. Their software always selects and presents for review the document or documents that it considers to have the highest probability of relevance, which have, of course, not already been coded.
The CAL method is only hybrid, like the e-Discovery Team method, in the sense of man and machine working together. But, from our perspective, it is not balanced. In fact, from our perspective the CAL method is way out of balance in favor of the machine. This may be the whole point of their method, to limit the human role as much as possible. The attorney has no role to play at all in selecting what document to review next and it does not matter if the attorney understands the training process. Personally, we do not like that. We want to be in charge and fully engaged throughout. We want the computer to be our tool, not our master.

Under our IST method the attorney chooses what documents to review next. We do not need the computer’s permission. We decide whether to accept a batch of high-ranking documents from the machine, or not. The attorney may instead find documents that they think are relevant from other methods. Even if the high ranked method of selection of training documents is used, the attorney decides the number of such documents to use and whether to supplement the machine selection with other training documents.
In fact, the only thing in common between IST and CAL is that both process continue throughout the life of a document review project and both are concerned with the Stop decision (when to when to stop the training and project). Under both methods after the Stopping point no new documents are selected for review and production. Instead, quality assurance methods that include sampling reviews are begun. If the quality assurance tests affirm that the decision to stop review was reasonable, then the project concludes. If they fail, more training and review are initiated.
 Aside from the differences in document selection between CAL and IST, the primary difference is that under IST the attorney decides when to train. The training does not occur automatically after each document, or specified number of documents, as in CAL, or at certain arbitrary time periods, as is common with other software. In the e-Discovery Team method of IST, which, again, stands for Intelligently Spaced (or staggered) Training, the attorney in charge decide when to train. We control the clock, the clock does not control us. The machine does not decide. Attorneys use their own intelligence to decide when to train the machine.
Aside from the differences in document selection between CAL and IST, the primary difference is that under IST the attorney decides when to train. The training does not occur automatically after each document, or specified number of documents, as in CAL, or at certain arbitrary time periods, as is common with other software. In the e-Discovery Team method of IST, which, again, stands for Intelligently Spaced (or staggered) Training, the attorney in charge decide when to train. We control the clock, the clock does not control us. The machine does not decide. Attorneys use their own intelligence to decide when to train the machine.
This timing control allows the attorney to observe the impact of the training on the machine. It is designed to improve the communication between man and machine. That is the double-loop learning process described in Part Two as part of the insights into Active Machine Learning. The attorney trains the machine and the machine is observed so that the trainer can learn how well the machine is doing. The attorney can learn what aspects of the relevance rule have been understood and what aspects still need improvement. Based on this student to teacher feedback the teacher is able to custom the next rounds of training to fit the needs of the student. This maximizes efficiency and effectiveness and is the essence of double-loop learning.
Pro Human Approach to Hybrid Man-Machine Partnership
 To wrap up the new Balanced Hybrid insights we would like to point out that our terminology speaks of Training– IST – rather than Learning – CAL. We do this intentionally because training is consistent with our human perspective. That is our perspective whereas the perspective of the machine is to learn. The attorney trains and the machine learns. We favor humans. Our goal is empowerment of attorney search experts to find the truth (relevance), the whole truth (recall) and nothing but the truth (precision). Our goal is to enhance human intelligence with artificial intelligence. Thus we prefer a Balanced Hybrid approach with IST and not CAL.
To wrap up the new Balanced Hybrid insights we would like to point out that our terminology speaks of Training– IST – rather than Learning – CAL. We do this intentionally because training is consistent with our human perspective. That is our perspective whereas the perspective of the machine is to learn. The attorney trains and the machine learns. We favor humans. Our goal is empowerment of attorney search experts to find the truth (relevance), the whole truth (recall) and nothing but the truth (precision). Our goal is to enhance human intelligence with artificial intelligence. Thus we prefer a Balanced Hybrid approach with IST and not CAL.
This is not to say the CAL approach of Grossman and Cormack is not good and does not work. It appears to work fine. It is just a tad too boring for us and sometimes too slow. Overall we think it is less efficient and may sometimes even be less effective than our Hybrid Multimodal method. But, even though it is not for us, it may be well be great for many beginners. It is very easy and simple to operate. From language in the Grossman Cormack patents that appears to be what they are going for – simplicity and ease of use. They have that and a growing body of evidence that it works. We wish them well, and also their software and CAL methodology.

I expect Grossman and Cormack, and others in the pro-machine camp, to move beyond the advantages of simplicity and also argue safety issues. I expect them to argue that it is safer to rely on AI because a machine is more reliable than a human, in the same way that Google’s self-driving car is safer and more reliable than a human driven car. Of course, unlike driving a car, they still need a human, an attorney, to decide yes or no on relevance, and so they are stuck with human reviewers. They are stuck with a least a partial Hybrid method, albeit one favoring as much as possible the machine side of the partnership. We do not think the pro-machine approach will work with attorneys, nor should it. We think that only an unabashedly pro-human approach like ours is likely to be widely adopted in the legal marketplace.
The goal of the pro-machine approach of Professors Cormack and Grossman, and others, is to minimize human judgments, no matter how skilled, and thereby reduce as much as possible the influence of human error and outright fraud. This is a part of a larger debate in the technology world. We respectfully disagree with this approach, at least in so far as legal document review is concerned. (Personally I tend to agree with it in so far as the driving of automobiles is concerned.) We instead seek enhancement and empowerment of attorneys by technology, including quality controls and fraud detection. See Why the ‘Google Car’ Has No Place in Legal Search. No doubt you will be hearing more about this interesting debate in the coming years. It may well have a significant impact on technology in the law, the quality of justice, and the future of lawyer employment.

To be continued …
7 Comments | Lawyers Duties, Review, Search, Technology, VENDORS | Tagged: best practices, computer assisted review, discovery, document review, justice, legal profession, legal search, machine learning, predictive coding, robot, robots, science, search, tar, technology, vendors | Permalink
Posted by Ralph Losey
What Chaos Theory Tell Us About e-Discovery and the Projected ‘Information → Knowledge → Wisdom’ Transition
May 20, 2016
Gleick & Losey meeting sometime in the future
This article assumes a general, non-technical familiarity with the scientific theory of Chaos. See James Gleick’s book, Chaos: making a new science (1987). This field of study is not usually discussed in the context of “The Law,” although there is a small body of literature outside of e-discovery. See: Chen, Jim, Complexity Theory in Legal Scholarship (Jurisdymanics 2006).
The article begins with a brief, personal recapitulation of the basic scientific theories of Chaos. I buttress my own synopsis with several good instructional videos. My explanation of the Mandelbrot Set and Complex numbers is a little long, I know, but you can skip over that and still understand all of the legal aspects. In this article I also explore the application of the Chaos theories to two areas of my current work:
- The search for needles of relevant evidence in large, chaotic, electronic storage systems, such as email servers and email archives, in order to find the truth, the whole truth, and nothing but the truth needed to resolve competing claims of what happened – the facts – in the context of civil and criminal law suits and investigations.
- The articulation of a coherent social theory that makes sense of modern technological life, a theory that I summarize with the words/symbols: Information → Knowledge → Wisdom. See Information → Knowledge → Wisdom: Progression of Society in the Age of Computers and the more recent, How The 12 Predictions Are Doing That We Made In “Information → Knowledge → Wisdom.”
Introduction to the Science of Chaos
Gleick’s book on Chaos provides a good introduction to the science of chaos and, even though written in 1987, is still a must read. For those who have read this long ago, like me, here is a good, short, 3:53, refresher video James Gleick on Chaos: Making a New Science (Open Road Media, 2011) below:
 A key leader in the Chaos Theory field is the late great French mathematician, Benoit Mandelbrot (1924-2010) (shown right). Benoit, a math genius who never learned the alphabet, spent most of his adult life employed by IBM. He discovered and named the natural phenomena of fractals. He discovered that there is a hidden order to any complex, seemingly chaotic system, including economics and the price of cotton. He also learned that this order was not causal and could not be predicted. He arrived at these insights by study of geometry, specifically the rough geometric shapes found everywhere in nature and mathematics, which he called fractals. The penultimate fractal he discovered now bears his name, The Mandelbrot Fractal, shown in the computer photo below, and explained further in the video that follows.
A key leader in the Chaos Theory field is the late great French mathematician, Benoit Mandelbrot (1924-2010) (shown right). Benoit, a math genius who never learned the alphabet, spent most of his adult life employed by IBM. He discovered and named the natural phenomena of fractals. He discovered that there is a hidden order to any complex, seemingly chaotic system, including economics and the price of cotton. He also learned that this order was not causal and could not be predicted. He arrived at these insights by study of geometry, specifically the rough geometric shapes found everywhere in nature and mathematics, which he called fractals. The penultimate fractal he discovered now bears his name, The Mandelbrot Fractal, shown in the computer photo below, and explained further in the video that follows.

Look here for thousands of additional videos of fractals with zoom magnifications. You will see the recursive nature of self-similarity over varying scales of magnitude. The patterns repeat with slight variations. The complex patterns at the rough edges continue infinitely without repetition, much like Pi. They show the unpredictable element and the importance of initial conditions played out over time. The scale of the in-between dimensions can be measured. Metadata remains important in all investigations, legal or otherwise.
![]()
The Mandelbrot is based on a simple mathematical formula involving feedback and Complex Numbers: z ⇔ z2 + c. The ‘c’ in the formula stands for any Complex Number. Unlike all other numbers, such as the natural numbers one through nine – 1.2.3.4.5.6.7.8.9, the Complex Numbers do not exist on a horizontal number line. They exist only on an x-y coordinate time plane where regular numbers on the horizontal grid combine with so-called Imaginary Numbers on the vertical grid. A complex number is shown as c= a + bi, where a and b are real numbers and i is the imaginary number. 
A complex number can be visually represented as a pair of numbers (a, b) forming a vector on a diagram called an Argand diagram, representing the complex plane. “Re” is the real axis, “Im” is the imaginary axis, and i is the imaginary number. And that is all there is too it. Mandelbrot calls the formula embarrassingly simple. That is the Occam’s razor beauty of it.
To understand the full dynamics of all of this remember what Imaginary Numbers are. They are a special class of numbers where a negative times a negative creates a negative, not a positive, like is the rule with all other numbers. In other words, with imaginary numbers -2 times -2 = -4, not +4. Imaginary numbers are formally defined as i2 = −1.
Thus, the formula z ⇔ z2 + c, can be restated as z ⇔ z2 + (a + bi).
The Complex Numbers when iterated according to this simple formula – subject to constant feedback – produce the Mandelbrot set.

 The value for z in the iteration always starts with zero. The ⇔ symbol stands for iteration, meaning the formula is repeated in a feedback loop. The end result of the last calculation becomes the beginning constant of the next: z² + c becomes the z in the next repetition. Z begins with zero and starts with different values for c. When you repeat the simple multiplication and addition formula millions of times, and plot it on a Cartesian grid, the Mandelbrot shape is revealed.
The value for z in the iteration always starts with zero. The ⇔ symbol stands for iteration, meaning the formula is repeated in a feedback loop. The end result of the last calculation becomes the beginning constant of the next: z² + c becomes the z in the next repetition. Z begins with zero and starts with different values for c. When you repeat the simple multiplication and addition formula millions of times, and plot it on a Cartesian grid, the Mandelbrot shape is revealed.
When iteration of a squaring process is applied to non-complex numbers the results are always known and predictable. For instance when any non-complex number greater than one is repeatedly squared, it quickly approaches infinity: 1.1 * 1.1 = 1.21 * 1.21 = 1.4641 * 1.4641 = 2.14358 and after ten iterations the number created is 2.43… * 10 which written out is 2,430,000,000,000,000,000,000,000,000,000,000,000,000,000. A number so large as to dwarf even the national debt. Mathematicians say of this size number that it is approaching infinity.
The same is true for any non-complex number which is less than one, but in reverse; it quickly goes to the infinitely small, the zero. For example with .9: .9.9=.81; .81.81=.6561; .6561.6561=.43046 and after only ten iterations it becomes 1.39…10 which written out is .0000000000000000000000000000000000000000000000139…, a very small number indeed.
With non-complex numbers, such as real, rational or natural numbers, the squaring iteration must always go to infinity unless the starting number is one. No matter how many times you square one, it will still equal one. But just the slightest bit more or less than one and the iteration of squaring will attract it to the infinitely large or small. The same behavior holds true for complex numbers: numbers just outside of the circle z = 1 on the complex plane will jump off into the infinitely large, complex numbers just inside z = 1 will quickly square into zero.
The magic comes by adding the constant c (a complex number) to the squaring process and starting from z at zero: z ⇔ z² + c. Then stable iterations – a set attracted to neither the infinitely small or infinitely large – become possible. The potentially stable Complex numbers lie both outside and inside of the circle of z = 1; specifically on the complex plane they lie between -2.4 and .8 on the real number line, the horizontal x grid, and between -1.2 and +1.2 on the imaginary line, the vertical y grid. These numbers are contained within the black of the Mandelbrot fractal.

In the Mandelbrot formula z ⇔ z² + c, where you always start the iterative process with z equals zero, and c equaling any complex number, an endless series of seemingly random or chaotic numbers are produced. Like the weather, the stock market and other chaotic systems, negligible changes in quantities, coupled with feedback, can produce unexpected chaotic effects. The behavior of the complex numbers thus mirrors the behavior of the real world where Chaos is obvious or lurks behind the most ordered of systems.
With some values of ‘c’ the iterative process immediately begins to exponentially increase or fall into infinity. These numbers are completely outside of the Mandelbrot set. With other values of ‘c’ the iterative process is stable for a number of repetitions, and only later in the dynamic process are they attracted to infinity. These are the unstable strange attractor numbers just on the outside edge of the Mandelbrot set. They are shown on computer graphics with colors or shades of grey according to the number of stable iterations. The values of ‘c’ which remain stable, repeating as a finite number forever, never attracted to infinity, and thus within the Mandelbrot set, are plotted as black.

Some iterations of complex numbers like 1 -1i run off into infinity from the start, just like all of the real numbers. Other complex numbers are always stable like -1 +0i. Other complex numbers stay stable for many iterations, and then only further into the process do they unpredictably begin to start to increase or decrease exponentially (for example, .37 +4i stays stable for 12 iterations). These are the numbers on the edge of inclusion of the stable numbers shown in black.
Chaos enters into the iteration because out of the potentially infinite number of complex numbers in the window of -2.4 to .8 along the horizontal real number axis, and -1.2 to 1.2 along the vertical imaginary number axis. There are an infinite subset of such numbers on the edge, and they cannot be predicted in advance. All that we know about these edge numbers is that if the z produced by any iteration lies outside of a circle with a radius of 2 on the complex plane, then the subsequent z values will go to infinity, and there is no need to continue the iteration process.
By using a computer you can escape the normal limitations of human time. You can try a very large number of different complex numbers and iterate them to see what kind they may be, finite or infinite. Under the Mandelbrot formula you start with z equals zero and then try different values for c. When a particular value of c is attracted to infinity – produces a value for z greater than 2 – then you stop that iteration, go back to z equals zero again, and try another c, and so on, over and over again, millions and millions of times as only a computer can do.
 Mandelbrot was the first to discover that by using zero as the base z for each iteration, and trying a large number of the possible complex numbers with a computer on a trial and error basis, that he could define the set of stable complex numbers graphically by plotting their location on the complex plane. This is exactly what the Mandelbrot figure is. Along with this discovery came the surprise realization of the beauty and fractal recursive nature of these numbers when displayed graphically.
Mandelbrot was the first to discover that by using zero as the base z for each iteration, and trying a large number of the possible complex numbers with a computer on a trial and error basis, that he could define the set of stable complex numbers graphically by plotting their location on the complex plane. This is exactly what the Mandelbrot figure is. Along with this discovery came the surprise realization of the beauty and fractal recursive nature of these numbers when displayed graphically.
The following Numberphile video by Holly Krieger, an NSF postdoctoral fellow and instructor at MIT, gives a fairly accessible, almost cutesy, yet still technically correct explanation to the Mandelbrot set.
Fractals and the Mandelbrot set are key parts of the Chaos theories, but there is much more to it than that. Chaos Theory impacts our basic Newtonian, cause-effect, linear world view of reality as a machine. For a refresher on the big picture of the Chaos insights and how the old linear, Newtonian, machine view of reality is wrong, look at this short summary: Chaos Theory (4:48)
Anther Chaos Theory instructional applying the insights to psychology is worth your view. The Science and Psychology of the Chaos Theory (8:59, 2008). It suggests the importance of spontaneous actions in the moment, the so-called flow state.
Also see High Anxieties – The Mathematics of Chaos (59:00, BBC 2008) concerning Chaos Theories, Economics and the Environment, and Order and Chaos (50:36, New Atlantis, 2015).
Application of Chaos Theories to e-Discovery
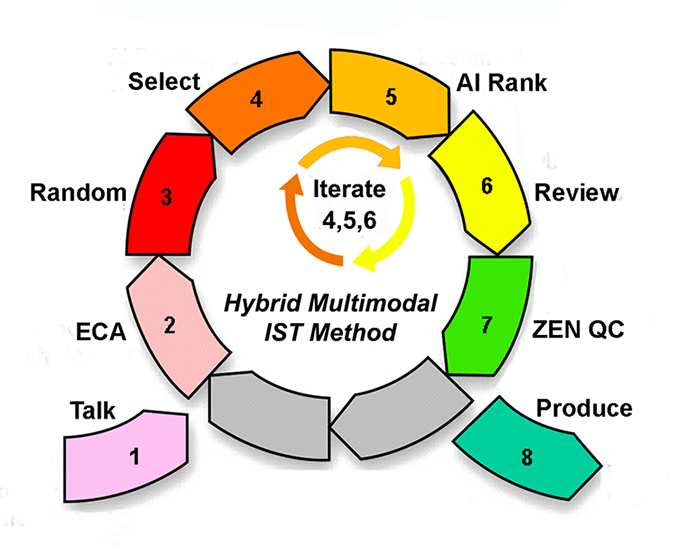
The use of feedback, iteration and algorithmic processes are central to work in electronic discovery. For instance, my search methods to find relevant evidence in chaotic systems follow iterative processes, including continuous, interactive, machine learning methods. I use these methods to find hidden patterns in the otherwise chaotic data. An overview of the methods I use in legal search is summarized in the following chart. As you can see, steps four, five and six iterate. These are the steps where human computer interactions take place.

My methods place heavy reliance on these steps and on human-computer interaction, which I call a Hybrid process. Like Maura Grossman and Gordon Cormack, I rely heavily on high-ranking documents in this Hybrid process. The primary difference in our methods is that I do not begin to place a heavy reliance on high-ranking documents until after completing several rounds of other training methods. I call this four cylinder multimodal training. This is all part of the sixth step in the 8-step workflow chart above. The four cylinders search engines are: (1) high ranking, (2) midlevel ranking or uncertain, (3) random, and (4) multimodal (including all types of search, such as keyword) directed by humans.
Analogous Application of Similar Mandelbrot Formula For Purposes of Expressing the Importance of the Creative Human Component in Hybrid

Recall Mandelbrot’s formula: z ⇔ z² + c, which is the same as z ⇔ z2 + (a + bi). I have something like that going on in my steps four, five and six. If you plugged the numbers of the steps into the Mandelbrot formula it would read something like this: 4 ⇔ 4² + (5+6i). The fourth step is the key AI Predictive Ranking step, where the algorithm ranks the probable relevance of all documents. The fourth step of computer ranking is the whole point of the formula, so AI Ranking here I will call ‘z‘ and represents the left side of the formula. The fifth step is where humans read documents to determine relevance, let’s call that ‘r‘ and the sixth step is where human’s train the computer, ‘t‘. This is the Hybrid Active Training step where the four cylinder multimodal training methods are used to select documents to train the whole set. The documents in steps five and six, r and t are added together for relevance feedback, (r + ti).
Thus, z ⇔ z² + c, which is the same as z ⇔ z2 + (a + bi), becomes under my system z ⇔ z + (r + ti). (Note: I took out the squaring, z², because there is no such exponential function in legal search; it’s all addition.) What, you might ask, is the i in my version of the formula? This is the critical part in my formula, just as it is in Mandelbrot’s. The imaginary number – i – in my formula version represents the creativity of the human conducting the training.
The Hybrid Active Training step is not fully automated in my system. I do not simply use the highest ranking documents to train, especially in the early rounds of training, as do some others. I use a variety of methods in my discretion, especially the multimodal search methods such a keywords, concept search, and the like. In text retrieval science this use of human discretion, human creativity and judgment, is called an ad hoc search. It contrasts with fully automated search, where the text retrieval experts try to eliminate the human element. See Mr EDR for more detail on 2016 TREC Total Recall Track that had both ad hoc and fully automated sections.
My work with legal search engines, especially predictive coding, has shown that new technologies do not work with the old methods and processes, such as linear review or keyword alone. New processes are required that employ new ways of thinking. The new methods that link creative human judgments (i) and the computer’s amazing abilities at text reading speed, consistency, analysis, learning and ranking (z).
 My latest processes, Predictive Coding 3.0, are variations of Continuous Active Training (CAT) where steps four, five and six iterate until the project is concluded. Grossman & Cormack call this Continuous Active Learning or CAL, and they claim Trademark rights to CAL. I respect their right to do so (no doubt they grow weary of vendor rip-offs) and will try to avoid the acronym henceforth. My use of the acronym CAT essentially takes the view of the other side, the human side that trains, not the machine side that learns. In both Continuous Active Learning and CAT the machine keeps learning with every document that a human codes. Continuous Active Learning or Training, makes the linear seed-set method obsolete, along with the control set and random training documents. See Losey, Predictive Coding 3.0.
My latest processes, Predictive Coding 3.0, are variations of Continuous Active Training (CAT) where steps four, five and six iterate until the project is concluded. Grossman & Cormack call this Continuous Active Learning or CAL, and they claim Trademark rights to CAL. I respect their right to do so (no doubt they grow weary of vendor rip-offs) and will try to avoid the acronym henceforth. My use of the acronym CAT essentially takes the view of the other side, the human side that trains, not the machine side that learns. In both Continuous Active Learning and CAT the machine keeps learning with every document that a human codes. Continuous Active Learning or Training, makes the linear seed-set method obsolete, along with the control set and random training documents. See Losey, Predictive Coding 3.0.
In my typical implementation of Continuous Active Training I do not automatically include every document coded as a training document. This is the sixth training step (‘t‘ in the prior formula). Instead of automatically using every document to train that has been coded relevant or irrelevant, I select particular documents that I decide to use to train. This, in addition to multimodal search in step six, Hybrid Active, is another way in which the equivalent of Imaginary Numbers come into my formula, the uniquely human element (ti). I typically use most every relevant document coded in step five, the ‘r‘ in the formula, as a training document, but not all. z ⇔ z + (r + ti)
I exercise my human judgment and experience to withhold certain training documents. (Note, I never withhold hot trainers (highly relevant documents)). I do this if my experience (I am tempted to say ‘my imagination‘) suggests that including them as training documents will likely slow down or confuse the algorithm, even if temporarily. I have found that this improves efficiency and effectiveness. It is one of the techniques I used to win document review contests.
 This kind of intimate machine communication is possible because I carefully observe the impact of each set of training documents on the classifying algorithm, and carryover lessons – iterate – from one project to the next. I call this keeping a human in the loop and the attorney in charge of relevance scope adjudications. See Losey, Why the ‘Google Car’ Has No Place in Legal Search. We humans provide experienced observation, new feedback, different approaches, empathy, play and emotion. We also add a whole lot of other things too. The AI-Robot is the Knowledge fountain. We are the Wisdom fountain.That it is why we should strive to progress into and through the Knowledge stage as soon as possible. We will thrive in the end-goal Wisdom state.
This kind of intimate machine communication is possible because I carefully observe the impact of each set of training documents on the classifying algorithm, and carryover lessons – iterate – from one project to the next. I call this keeping a human in the loop and the attorney in charge of relevance scope adjudications. See Losey, Why the ‘Google Car’ Has No Place in Legal Search. We humans provide experienced observation, new feedback, different approaches, empathy, play and emotion. We also add a whole lot of other things too. The AI-Robot is the Knowledge fountain. We are the Wisdom fountain.That it is why we should strive to progress into and through the Knowledge stage as soon as possible. We will thrive in the end-goal Wisdom state.
Application of Chaos Theory to Information→Knowledge→Wisdom
 The first Information stage of the post-computer society in which we live is obviously chaotic. It is like the disconnected numbers that lie completely outside of the Mandelbrot set. It is pure information with only haphazard meaning. It is often just misinformation. Just exponential. There is an overwhelming deluge of such raw information, raw data, that spirals off into an infinity of dead-ends. It leads no where and is disconnected. The information is useless. You may be informed, but to no end. That is modern life in the post-PC era.
The first Information stage of the post-computer society in which we live is obviously chaotic. It is like the disconnected numbers that lie completely outside of the Mandelbrot set. It is pure information with only haphazard meaning. It is often just misinformation. Just exponential. There is an overwhelming deluge of such raw information, raw data, that spirals off into an infinity of dead-ends. It leads no where and is disconnected. The information is useless. You may be informed, but to no end. That is modern life in the post-PC era.
The next stage of society we seek, a Knowledge based culture, is geometrically similar to the large black blogs that unite most of the figure. This is the finite set of numbers that provide all connectivity in the Mandelbrot set. Analogously, this will be a time when many loose-ends will be discarded, false theories abandoned, and consensus arise.
In the next stage we will not only be informed, we will be knowledgable. The information we all be processed. The future Knowledge Society will be static, responsible, serious and well fed. People will be brought together by common knowledge. There will be large scale agreements on most subjects. A tremendous amount of diversity will likely be lost.
After a while a knowledgable world will become boring. Ask any professor or academic. The danger of the next stage will be stagnation, complacency, self-satisfaction. The smug complacency of a know-it-all world. This may be just as dangerous as the pure-chaos Information world in which we now live.
If society is to continue to evolve after that, we will need to move beyond mere Knowledge. We will need to challenge ourselves to attain new, creative applications of Knowledge. We will need to move beyond Knowledge into Wisdom.
 I am inclined to think that if we ever do progress to a Wisdom-based society, we will be a place and time much like the unpredictable fractal edges of the Mandelbrot. Stable to a point, but ultimately unpredictable, constantly changing, evolving. The basic patterns of our truth will remain the same, but they will constantly evolve and be refined. The deeper we dig, the more complex and beautiful it will be. The dry sameness of a Knowledgable based world will be replaced by an ever-changing flow, by more and more diversity and individuality. Our social cohesivity will arise from recursivity and similarity, not sameness and conformity. A Wisdom based society will be filled with fractal beauty. It will live ever zigzagging between the edge of the known and unknown. It will also necessarily have to be a time when people learn to get along together and share in prosperity and health, both physical and mental. It will be a time when people are accustomed to ambiguities and comfortable with them.
I am inclined to think that if we ever do progress to a Wisdom-based society, we will be a place and time much like the unpredictable fractal edges of the Mandelbrot. Stable to a point, but ultimately unpredictable, constantly changing, evolving. The basic patterns of our truth will remain the same, but they will constantly evolve and be refined. The deeper we dig, the more complex and beautiful it will be. The dry sameness of a Knowledgable based world will be replaced by an ever-changing flow, by more and more diversity and individuality. Our social cohesivity will arise from recursivity and similarity, not sameness and conformity. A Wisdom based society will be filled with fractal beauty. It will live ever zigzagging between the edge of the known and unknown. It will also necessarily have to be a time when people learn to get along together and share in prosperity and health, both physical and mental. It will be a time when people are accustomed to ambiguities and comfortable with them.
In Wisdom World knowledge itself will be plentiful, but will be held very lightly. It will be subject to constant reevaluation. Living in Wisdom will be like living on the rough edge of the Mandelbrot. It will be a culture that knows infinity firsthand. An open, peaceful, ecumenical culture that knows everything and nothing at the same time. A culture where most of the people, or at least a strong minority, have attained a certain level of personal Wisdom.
Conclusion
 Back to our times, where we are just now discovering what machine learning can do, we are just beginning to pattern our investigations, our search for truth, in the Law and elsewhere, on new information gleaned from the Chaos theories. Active machine learning, Predictive Coding, is a natural outgrowth of Chaos Theory and the Mandelbrot Set. The insights of hidden fractal order that can only be seen by repetitive computer processes are prevalent in computer based culture. These iterative, computer assisted processes have been the driving force behind thousands of fact investigations that I have conducted since 1980.
Back to our times, where we are just now discovering what machine learning can do, we are just beginning to pattern our investigations, our search for truth, in the Law and elsewhere, on new information gleaned from the Chaos theories. Active machine learning, Predictive Coding, is a natural outgrowth of Chaos Theory and the Mandelbrot Set. The insights of hidden fractal order that can only be seen by repetitive computer processes are prevalent in computer based culture. These iterative, computer assisted processes have been the driving force behind thousands of fact investigations that I have conducted since 1980.
I have been using computers to help me in legal investigations since 1980. The reliance on computers at first increased slowly, but steadily. Then from about 2006 to 2013 the increase accelerated and peaked in late 2013. The shift is beginning to level off. We are still heavily dependent on computers, but now we understand that human methods are just as important as software. Software is limited in its capacities without human additive, especially in legal search. Hybrid, Man and Machine, that is the solution. But remember that the focus should be on us, human lawyers and search experts. The AIs we are creating and training should be used to Augment and Enhance our abilities, not replace them. They should complement and complete us.
 The converse realization of Chaos Theory, that disorder underlies all apparent order, that if you look closely enough, you will find it, also informs our truth-seeking investigatory work. There are no smooth edges. It is all rough. If you look close enough the border of any coastline is infinite.
The converse realization of Chaos Theory, that disorder underlies all apparent order, that if you look closely enough, you will find it, also informs our truth-seeking investigatory work. There are no smooth edges. It is all rough. If you look close enough the border of any coastline is infinite.
The same is true of the complexity of any investigation. As every experienced lawyer knows, there is no black and white, no straight line. It always depends on so many things. Complexity and ambiguity are everywhere. There is always a mess, always rough edges. That is what makes the pursuit of truth so interesting. Just when you think you have it, the turbulent echo of another butterfly’s wings knock you about.
The various zigs and zags of e-discovery, and other investigative, truth-seeking activities, are what make them fascinating. Each case is different, unique, yet the same patterns are seen again and again with recursive similarity. Often you begin a search only to have it quickly burn out. No problem, try again. Go back to square one, back to zero, and try another complex number, another clue. Pursue a new idea, a new connection. You chase down all reasonable leads, understanding that many of them will lead nowhere. Even failed searches rule out negatives and so help in the investigation. Lawyers often try to prove a negative.
The fractal story that emerges from Hybrid Multimodal search is often unexpected. As the search matures you see a bigger story, a previously hidden truth. A continuity emerges that connects previously unrelated facts. You literally connect the dots. The unknown complex numbers – (a + bi) – the ones that do not spiral off into the infinite large or small, do in fact touch each other when you look closely enough at the spaces.
z ⇔ z2 + (a + bi)
 I am no Sherlock, but I know how to find ESI using computer processes. It requires an iterative sorting processes, a hybrid multimodal process, using the latest computers and software. This process allows you to harness the infinite patience, analytics and speed of a machine to enhance your own intelligence ……. to augment your own abilities. You let the computer do the boring bits, the drudgery, while you do the creative parts.
I am no Sherlock, but I know how to find ESI using computer processes. It requires an iterative sorting processes, a hybrid multimodal process, using the latest computers and software. This process allows you to harness the infinite patience, analytics and speed of a machine to enhance your own intelligence ……. to augment your own abilities. You let the computer do the boring bits, the drudgery, while you do the creative parts.
The strength comes from the hybrid synergy. It comes from exploring the rough edges of what you think you know about the evidence. It does not come from linear review, nor simple keyword cause-effect. Evidence is always complex, always derived from chaotic systems. A full multimodal selection of search tools is needed to find this kind of dark data.
The truth is out there, but sometimes you have to look very carefully to find it. You have to dig deep and keep on looking to find the missing pieces, to move from Information → Knowledge → Wisdom.
_______
______
_____
____
___
__
_
.

.
_
—
–
.

.
—
–
.
2 Comments | Evidence, informaton, knowledge, Lawyers Duties, Review, Search, Technology, wisdom | Tagged: chaos, computer assisted review, evidence, legal search, machine learning, predictive coding, robot, science, search, technology, too much information, truth | Permalink
Posted by Ralph Losey