Protected: It’s Mueller Time! The Emergence of a New Legal Service Based on Artificial Intelligence
January 29, 2019
 Enter your password to view comments. |
Enter your password to view comments. |  Evidence, informaton, knowledge, Lawyers Duties, Metadata, New Rules, Related Legal Webs, Review, Search, Spoliation/Sanctions, Technology, VENDORS, wisdom | Tagged: ai, computer assisted review, discovery, document review, ethics, evidence, legal profession, machine learning, Mueller, predictive coding, search, tar, too much information |
Evidence, informaton, knowledge, Lawyers Duties, Metadata, New Rules, Related Legal Webs, Review, Search, Spoliation/Sanctions, Technology, VENDORS, wisdom | Tagged: ai, computer assisted review, discovery, document review, ethics, evidence, legal profession, machine learning, Mueller, predictive coding, search, tar, too much information |  Permalink
Permalink
 Posted by Ralph Losey
Posted by Ralph Losey
Protected: 12 Days of Christmas: What Do You Do When Your Client Sends To You? – Part Two
December 24, 2018
Enter your password to view comments. | Evidence, Forensic Exam, Lawyers Duties, Metadata, New Rules, Review, Search, Spoliation/Sanctions, Technology | Tagged: best practices, discovery, document review, evidence, search, technology | Permalink
Posted by Ralph Losey
Protected: Transparency in a Salt Lake TAR Pit?
November 11, 2018
Enter your password to view comments. | Lawyers Duties, Review, Search, Technology | Tagged: best practices, computer assisted review, document review, legal search, machine learning, predictive coding, search, tar | Permalink
Posted by Ralph Losey
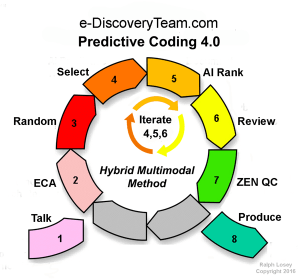
Do TAR the Right Way with “Hybrid Multimodal Predictive Coding 4.0”
October 8, 2018The term “TAR” – Technology Assisted Review – as we use it means document review enhanced by active machine learning. Active machine learning is an important tool of specialized Artificial Intelligence. It is now widely used in many industries, including Law. The method of AI-enhanced document review we developed is called Hybrid Multimodal Predictive Coding 4.0. Interestingly, reading these words in the new Sans Forgetica font will help you to remember them.
 We have developed an online instructional program to teach our TAR methods and AI infused concepts to all kinds of legal professionals. We use words, studies, case-law, science, diagrams, math, statistics, scientific studies, test results and appeals to reason to teach the methods. To balance that out, we also make extensive use of photos and videos. We use right brain tools of all kinds, even subliminals, special fonts, hypnotic images and loads of hyperlinks. We use emotion as another teaching tool. Logic and Emotion. Sorry Spock, but this multimodal, holistic approach is more effective with humans than an all-text, reason-only approach of Vulcan law schools.
We have developed an online instructional program to teach our TAR methods and AI infused concepts to all kinds of legal professionals. We use words, studies, case-law, science, diagrams, math, statistics, scientific studies, test results and appeals to reason to teach the methods. To balance that out, we also make extensive use of photos and videos. We use right brain tools of all kinds, even subliminals, special fonts, hypnotic images and loads of hyperlinks. We use emotion as another teaching tool. Logic and Emotion. Sorry Spock, but this multimodal, holistic approach is more effective with humans than an all-text, reason-only approach of Vulcan law schools.

We even try to use humor and promote student creativity with our homework assignments. Please remember, however, this is not an accredited law school class, so do not expect professorial interaction. Did we mention the TAR Course is free?
By the end of study of the TAR Course you will know and remember exactly what Hybrid Multimodal means. You will understand the importance of using all varieties of legal search, for instance: keywords, similarity searches, concept searches and AI driven probable relevance document ranking. That is the Multimodal part. We use all of the search tools that our KL Discovery document review software provides.

![]() The Hybrid part refers to the partnership with technology, the reliance of the searcher on the advanced algorithmic tools. It is important than Man and Machine work together, but that Man remain in charge of justice. The predictive coding algorithms and software are used to enhance the lawyers, paralegals and law tech’s abilities, not replace them.
The Hybrid part refers to the partnership with technology, the reliance of the searcher on the advanced algorithmic tools. It is important than Man and Machine work together, but that Man remain in charge of justice. The predictive coding algorithms and software are used to enhance the lawyers, paralegals and law tech’s abilities, not replace them.
By the end of the TAR Course you will also know what IST means, literally Intelligently Spaced Training. It is our specialty technique of AI training where you keep training the Machine until first pass relevance review is completed. This is a type of Continuous Active Learning, or as Grossman and Cormack call it, CAL.  By the end of the TAR Course you should also know what a Stop Decision is. It is a critical point of the document review process. When do you stop the active machine teaching process? When is enough review enough? This involves legal proportionality issues, to be sure, but it also involves technological processes, procedures and measurements. What is good enough Recall under the circumstances with the data at hand? When should you stop the machine training?
By the end of the TAR Course you should also know what a Stop Decision is. It is a critical point of the document review process. When do you stop the active machine teaching process? When is enough review enough? This involves legal proportionality issues, to be sure, but it also involves technological processes, procedures and measurements. What is good enough Recall under the circumstances with the data at hand? When should you stop the machine training?

![]()
We can teach you the concepts, but this kind of deep knowledge of timing requires substantial experience. In fact, refining the Stop Decision was one of the main tasks we set for ourself for the e-Discovery Team experiments in the Total Recall Track of the National Institute of Standards and Technology Text Retrieval Conference in 2015 and 2016. We learned a lot in our two years. I do not think anyone has spent more time studying this in both scientific and commercial projects than we have. Kudos again to KL Discovery for helping to sponsor this kind of important research by the e-Discovery Team.

Working with AI like this for evidence gathering is a newly emerging art. Take the TAR Course and learn the latest methods. We divide the Predictive Coding work flow into eight-steps. Master these steps and related concepts to do TAR the right way.
Pop Quiz: What is one of the most important considerations on when to train again?
 One Possible Correct Answer: The schedule of the humans involved. Logistics and project planning is always important for efficiency. Flexibility is easy to attain with the IST method. You can easily accommodate schedule changes and make it as easy as possible for humans and “robots” to work together. We do not literally mean robots, but rather refer to the advanced software and the AI that arises from the machine training as an imiginary robot.
One Possible Correct Answer: The schedule of the humans involved. Logistics and project planning is always important for efficiency. Flexibility is easy to attain with the IST method. You can easily accommodate schedule changes and make it as easy as possible for humans and “robots” to work together. We do not literally mean robots, but rather refer to the advanced software and the AI that arises from the machine training as an imiginary robot.


1 Comment | Lawyers Duties, Related Legal Webs, Review, Search | Tagged: best practices, computer assisted review, document review, education, legal search, machine learning, predictive coding, search, tar, technology | Permalink
Posted by Ralph Losey